Hello Guys,
Today, I’ll share one of the important posts on predicting data using facebook’s relatively new machine-learning-based API. I find this API is interesting as to how it can build & anticipate the outcome.
We’ll be using one of the most acceptable API-based sources for Covid-19 & I’ll be sharing the link over here.
We’ll be using the prophet-API developed by Facebook to predict the data. You will get the details from this link.
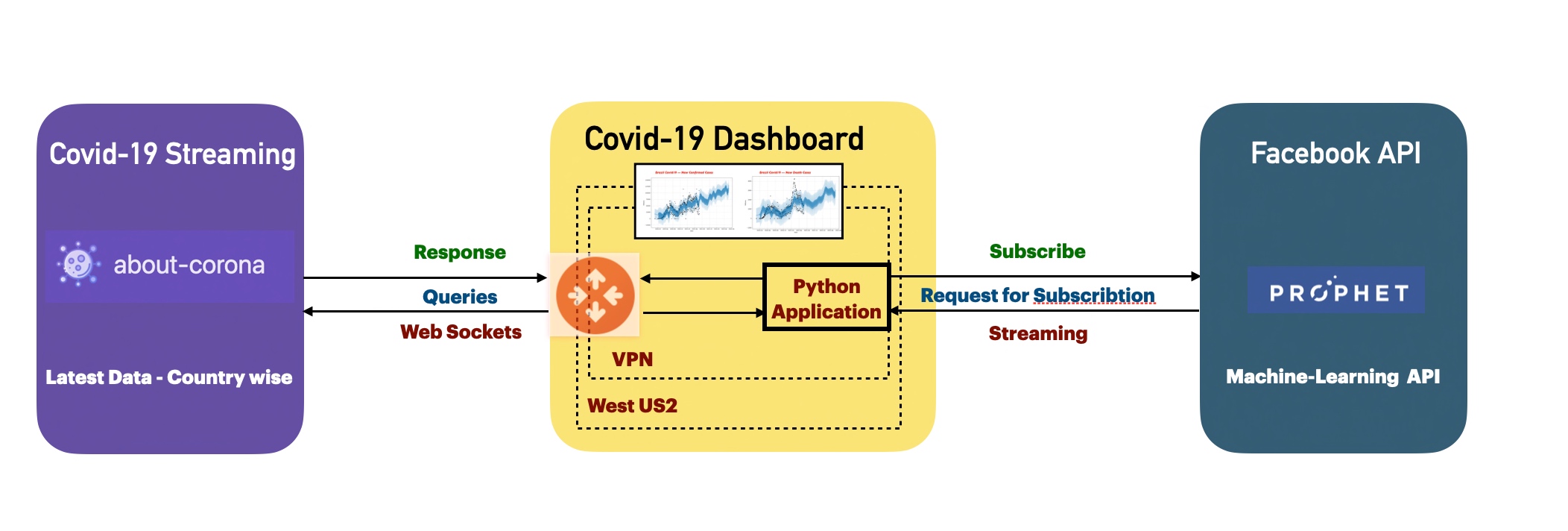
Now, let’s explore the architecture shared above.
As you can see that the application will consume the data from the third-party API named “about-corona,” & the python application will clean & transform the data. The application will send the clean data to the Facebook API (prophet) built on the machine-learning algorithm. This API is another effective time-series analysis platform given to the data scientist community.
Once the application receives the predicted model, it will visualize them using plotly & matplotlib.
I would request you to please check the demo of this application just for your reference.
We’ll do a time series analysis. Let us understand the basic concept of time series.
Time series is a series of data points indexed (or listed or graphed) in time order.
Therefore, the data organized by relatively deterministic timestamps and potentially compared with random sample data contain additional information that we can leverage for our business use case to make a better decision.
To use the prophet API, one needs to use & transform their data cleaner & should contain two fields (ds & y).
Let’s check one such use case since our source has plenty of good data points to decide. We’ve daily data of newly infected covid patients based on countries, as shown below –
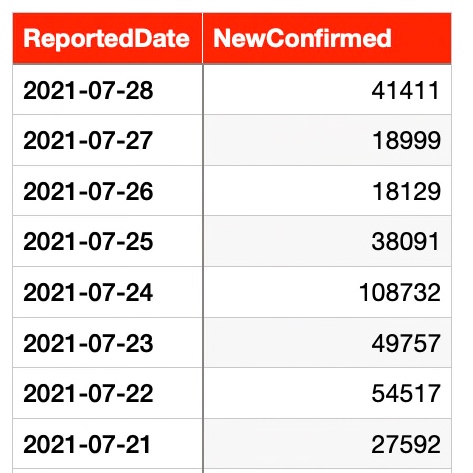
And, our clean class will transform the data into two fields –
Once we fit the data into the prophet model, it will generate some additional columns, which will be used for prediction as shown below –
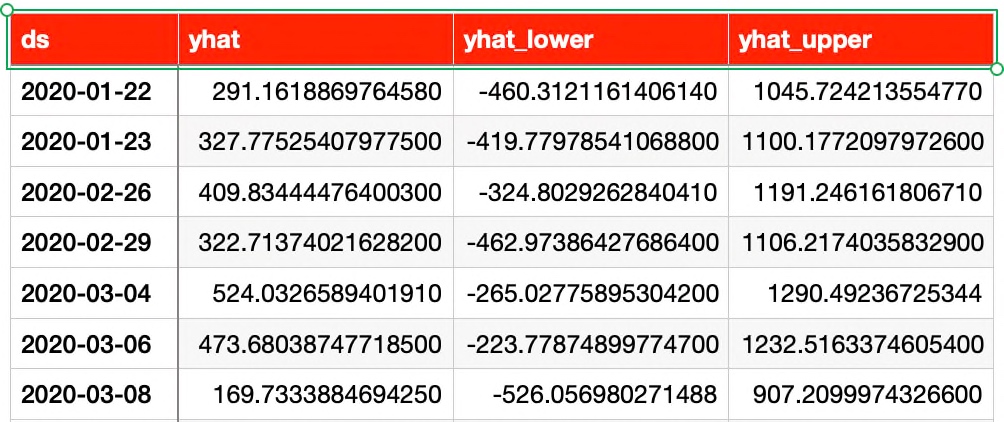
And, a sample prediction based on a similar kind of data would be identical to this –

Let us understand what packages we need to install to prepare this application –

And, here is the packages –
pip install pandas pip install matplotlib pip install prophet
Let us now revisit the code –
1. clsConfig.py ( This native Python script contains the configuration entries. )
This file contains hidden or bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
| ##################################################### | |
| #### Written By: SATYAKI DE #### | |
| #### Written On: 26-Jul-2021 #### | |
| #### #### | |
| #### Objective: This script is a config #### | |
| #### file, contains all the keys for #### | |
| #### for Prophet API. Application will #### | |
| #### process these information & perform #### | |
| #### the call to our newly developed with #### | |
| #### APIs developed by Facebook & a open-source #### | |
| #### project called "About-Corona". #### | |
| ##################################################### | |
| import os | |
| import platform as pl | |
| class clsConfig(object): | |
| Curr_Path = os.path.dirname(os.path.realpath(__file__)) | |
| os_det = pl.system() | |
| if os_det == "Windows": | |
| sep = '\\' | |
| else: | |
| sep = '/' | |
| conf = { | |
| 'APP_ID': 1, | |
| "URL":"https://corona-api.com/countries/", | |
| "appType":"application/json", | |
| "conType":"keep-alive", | |
| "limRec": 10, | |
| "CACHE":"no-cache", | |
| "coList": "DE, IN, US, CA, GB, ID, BR", | |
| "LOG_PATH":Curr_Path + sep + 'log' + sep, | |
| "MAX_RETRY": 3, | |
| "FNC": "NewConfirmed", | |
| "TMS": "ReportedDate", | |
| "FND": "NewDeaths" | |
| } |
We’re not going to discuss anything specific to this script.
2. clsL.py ( This native Python script logs the application. )
This file contains hidden or bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
| ##################################################### | |
| #### Written By: SATYAKI DE #### | |
| #### Written On: 26-Jul-2021 #### | |
| #### #### | |
| #### Objective: This script is a log #### | |
| #### file, that is useful for debugging purpose. #### | |
| #### #### | |
| ##################################################### | |
| import pandas as p | |
| import os | |
| import platform as pl | |
| class clsL(object): | |
| def __init__(self): | |
| self.path = os.path.dirname(os.path.realpath(__file__)) | |
| def logr(self, Filename, Ind, df, subdir=None, write_mode='w', with_index='N'): | |
| try: | |
| x = p.DataFrame() | |
| x = df | |
| sd = subdir | |
| os_det = pl.system() | |
| if sd == None: | |
| if os_det == "windows": | |
| fullFileName = self.path + '\\' + Filename | |
| else: | |
| fullFileName = self.path + '/' + Filename | |
| else: | |
| if os_det == "windows": | |
| fullFileName = self.path + '\\' + sd + '\\' + Filename | |
| else: | |
| fullFileName = self.path + '/' + sd + '/' + Filename | |
| if (with_index == 'N'): | |
| if ((Ind == 'Y') & (write_mode == 'w')): | |
| x.to_csv(fullFileName, index=False) | |
| else: | |
| x.to_csv(fullFileName, index=False, mode=write_mode, header=None) | |
| else: | |
| if ((Ind == 'Y') & (write_mode == 'w')): | |
| x.to_csv(fullFileName) | |
| else: | |
| x.to_csv(fullFileName, mode=write_mode, header=None) | |
| return 0 | |
| except Exception as e: | |
| y = str(e) | |
| print(y) | |
| return 3 |
Based on the operating system, the log class will capture potential information under the “log” directory in the form of csv for later reference purposes.
3. clsForecast.py ( This native Python script will clean & transform the data. )
This file contains hidden or bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
| ############################################## | |
| #### Written By: SATYAKI DE #### | |
| #### Written On: 26-Jul-2021 #### | |
| #### Modified On 26-Jul-2021 #### | |
| #### #### | |
| #### Objective: Calling Data Cleaning API #### | |
| ############################################## | |
| import json | |
| from clsConfig import clsConfig as cf | |
| import requests | |
| import logging | |
| import time | |
| import pandas as p | |
| import clsL as cl | |
| from prophet import Prophet | |
| class clsForecast: | |
| def __init__(self): | |
| self.fnc = cf.conf['FNC'] | |
| self.fnd = cf.conf['FND'] | |
| self.tms = cf.conf['TMS'] | |
| def forecastNewConfirmed(self, srcDF, debugInd, varVa): | |
| try: | |
| fnc = self.fnc | |
| tms = self.tms | |
| var = varVa | |
| debug_ind = debugInd | |
| countryISO = '' | |
| df_M = p.DataFrame() | |
| dfWork = srcDF | |
| # Initiating Log class | |
| l = cl.clsL() | |
| #Extracting the unique country name | |
| unqCountry = dfWork['CountryCode'].unique() | |
| for i in unqCountry: | |
| countryISO = i.strip() | |
| print('Country Name: ' + countryISO) | |
| df_Comm = dfWork[[tms, fnc]] | |
| l.logr('13.df_Comm_' + var + '.csv', debug_ind, df_Comm, 'log') | |
| # Aligning as per Prophet naming convention | |
| df_Comm.columns = ['ds', 'y'] | |
| l.logr('14.df_Comm_Mod_' + var + '.csv', debug_ind, df_Comm, 'log') | |
| return df_Comm | |
| except Exception as e: | |
| x = str(e) | |
| print(x) | |
| logging.info(x) | |
| df = p.DataFrame() | |
| return df | |
| def forecastNewDead(self, srcDF, debugInd, varVa): | |
| try: | |
| fnd = self.fnd | |
| tms = self.tms | |
| var = varVa | |
| debug_ind = debugInd | |
| countryISO = '' | |
| df_M = p.DataFrame() | |
| dfWork = srcDF | |
| # Initiating Log class | |
| l = cl.clsL() | |
| #Extracting the unique country name | |
| unqCountry = dfWork['CountryCode'].unique() | |
| for i in unqCountry: | |
| countryISO = i.strip() | |
| print('Country Name: ' + countryISO) | |
| df_Comm = dfWork[[tms, fnd]] | |
| l.logr('17.df_Comm_' + var + '.csv', debug_ind, df_Comm, 'log') | |
| # Aligning as per Prophet naming convention | |
| df_Comm.columns = ['ds', 'y'] | |
| l.logr('18.df_Comm_Mod_' + var + '.csv', debug_ind, df_Comm, 'log') | |
| return df_Comm | |
| except Exception as e: | |
| x = str(e) | |
| print(x) | |
| logging.info(x) | |
| df = p.DataFrame() | |
| return df |
Let’s explore the critical snippet out of this script –
df_Comm = dfWork[[tms, fnc]]
Now, the application will extract only the relevant columns to proceed.
df_Comm.columns = ['ds', 'y']
It is now assigning specific column names, which is a requirement for prophet API.
4. clsCovidAPI.py ( This native Python script will call the Covid-19 API. )
This file contains hidden or bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
| ############################################## | |
| #### Written By: SATYAKI DE #### | |
| #### Written On: 26-Jul-2021 #### | |
| #### Modified On 26-Jul-2021 #### | |
| #### #### | |
| #### Objective: Calling Covid-19 API #### | |
| ############################################## | |
| import json | |
| from clsConfig import clsConfig as cf | |
| import requests | |
| import logging | |
| import time | |
| import pandas as p | |
| import clsL as cl | |
| class clsCovidAPI: | |
| def __init__(self): | |
| self.url = cf.conf['URL'] | |
| self.azure_cache = cf.conf['CACHE'] | |
| self.azure_con = cf.conf['conType'] | |
| self.type = cf.conf['appType'] | |
| self.typVal = cf.conf['coList'] | |
| self.max_retries = cf.conf['MAX_RETRY'] | |
| def searchQry(self, varVa, debugInd): | |
| try: | |
| url = self.url | |
| api_cache = self.azure_cache | |
| api_con = self.azure_con | |
| type = self.type | |
| typVal = self.typVal | |
| max_retries = self.max_retries | |
| var = varVa | |
| debug_ind = debugInd | |
| cnt = 0 | |
| df_M = p.DataFrame() | |
| # Initiating Log class | |
| l = cl.clsL() | |
| payload = {} | |
| strMsg = 'Input Countries: ' + str(typVal) | |
| logging.info(strMsg) | |
| headers = {} | |
| countryList = typVal.split(',') | |
| for i in countryList: | |
| # Failed case retry | |
| retries = 1 | |
| success = False | |
| val = '' | |
| try: | |
| while not success: | |
| # Getting response from web service | |
| try: | |
| df_conv = p.DataFrame() | |
| strCountryUrl = url + str(i).strip() | |
| print('Country: ' + str(i).strip()) | |
| print('Url: ' + str(strCountryUrl)) | |
| str1 = 'Url: ' + str(strCountryUrl) | |
| logging.info(str1) | |
| response = requests.request("GET", strCountryUrl, headers=headers, params=payload) | |
| ResJson = response.text | |
| #jdata = json.dumps(ResJson) | |
| RJson = json.loads(ResJson) | |
| df_conv = p.io.json.json_normalize(RJson) | |
| df_conv.drop(['data.timeline'], axis=1, inplace=True) | |
| df_conv['DummyKey'] = 1 | |
| df_conv.set_index('DummyKey') | |
| l.logr('1.df_conv_' + var + '.csv', debug_ind, df_conv, 'log') | |
| # Extracting timeline part separately | |
| Rjson_1 = RJson['data']['timeline'] | |
| df_conv2 = p.io.json.json_normalize(Rjson_1) | |
| df_conv2['DummyKey'] = 1 | |
| df_conv2.set_index('DummyKey') | |
| l.logr('2.df_conv_timeline_' + var + '.csv', debug_ind, df_conv2, 'log') | |
| # Doing Cross Join | |
| df_fin = df_conv.merge(df_conv2, on='DummyKey', how='outer') | |
| l.logr('3.df_fin_' + var + '.csv', debug_ind, df_fin, 'log') | |
| # Merging with the previous Country Code data | |
| if cnt == 0: | |
| df_M = df_fin | |
| else: | |
| d_frames = [df_M, df_fin] | |
| df_M = p.concat(d_frames) | |
| cnt += 1 | |
| strCountryUrl = '' | |
| if str(response.status_code)[:1] == '2': | |
| success = True | |
| else: | |
| wait = retries * 2 | |
| print("retries Fail! Waiting " + str(wait) + " seconds and retrying!") | |
| str_R1 = "retries Fail! Waiting " + str(wait) + " seconds and retrying!" | |
| logging.info(str_R1) | |
| time.sleep(wait) | |
| retries += 1 | |
| # Checking maximum retries | |
| if retries == max_retries: | |
| success = True | |
| raise Exception | |
| except Exception as e: | |
| x = str(e) | |
| print(x) | |
| logging.info(x) | |
| pass | |
| except Exception as e: | |
| pass | |
| l.logr('4.df_M_' + var + '.csv', debug_ind, df_M, 'log') | |
| return df_M | |
| except Exception as e: | |
| x = str(e) | |
| print(x) | |
| logging.info(x) | |
| df = p.DataFrame() | |
| return df |
Let us explore the key snippet –
countryList = typVal.split(',')
The application will fetch individual country names into a list based on the input lists from the configure script.
response = requests.request("GET", strCountryUrl, headers=headers, params=payload)
ResJson = response.text
RJson = json.loads(ResJson)
df_conv = p.io.json.json_normalize(RJson)
df_conv.drop(['data.timeline'], axis=1, inplace=True)
df_conv['DummyKey'] = 1
df_conv.set_index('DummyKey')
The application will extract the elements & normalize the JSON & convert that to a pandas dataframe & also added one dummy column, which will use for the later purpose to merge the data from another set.
# Extracting timeline part separately
Rjson_1 = RJson['data']['timeline']
df_conv2 = p.io.json.json_normalize(Rjson_1)
df_conv2['DummyKey'] = 1
df_conv2.set_index('DummyKey')
Now, the application will take the nested element & normalize that as per granular level. Also, it added the dummy column to join both of these data together.
# Doing Cross Join df_fin = df_conv.merge(df_conv2, on='DummyKey', how='outer')
The application will Merge both the data sets to get the complete denormalized data for our use cases.
# Merging with the previous Country Code data
if cnt == 0:
df_M = df_fin
else:
d_frames = [df_M, df_fin]
df_M = p.concat(d_frames)
This entire deserializing execution happens per country. Hence, the above snippet will create an individual sub-group based on the country & later does union to all the sets.
if str(response.status_code)[:1] == '2':
success = True
else:
wait = retries * 2
print("retries Fail! Waiting " + str(wait) + " seconds and retrying!")
str_R1 = "retries Fail! Waiting " + str(wait) + " seconds and retrying!"
logging.info(str_R1)
time.sleep(wait)
retries += 1
# Checking maximum retries
if retries == max_retries:
success = True
raise Exception
If any calls to source API fails, the application will retrigger after waiting for a specific time until it reaches its maximum capacity.
5. callPredictCovidAnalysis.py ( This native Python script is the main one to predict the Covid. )
This file contains hidden or bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
| ############################################## | |
| #### Written By: SATYAKI DE #### | |
| #### Written On: 26-Jul-2021 #### | |
| #### Modified On 26-Jul-2021 #### | |
| #### #### | |
| #### Objective: Calling multiple API's #### | |
| #### that including Prophet-API developed #### | |
| #### by Facebook for future prediction of #### | |
| #### Covid-19 situations in upcoming days #### | |
| #### for world's major hotspots. #### | |
| ############################################## | |
| import json | |
| import clsCovidAPI as ca | |
| from clsConfig import clsConfig as cf | |
| import datetime | |
| import logging | |
| import clsL as cl | |
| import clsForecast as f | |
| from prophet import Prophet | |
| from prophet.plot import plot_plotly, plot_components_plotly | |
| import matplotlib.pyplot as plt | |
| import pandas as p | |
| # Disbling Warning | |
| def warn(*args, **kwargs): | |
| pass | |
| import warnings | |
| warnings.warn = warn | |
| # Initiating Log class | |
| l = cl.clsL() | |
| # Helper Function that removes underscores | |
| def countryDet(inputCD): | |
| try: | |
| countryCD = inputCD | |
| if str(countryCD) == 'DE': | |
| cntCD = 'Germany' | |
| elif str(countryCD) == 'BR': | |
| cntCD = 'Brazil' | |
| elif str(countryCD) == 'GB': | |
| cntCD = 'United Kingdom' | |
| elif str(countryCD) == 'US': | |
| cntCD = 'United States' | |
| elif str(countryCD) == 'IN': | |
| cntCD = 'India' | |
| elif str(countryCD) == 'CA': | |
| cntCD = 'Canada' | |
| elif str(countryCD) == 'ID': | |
| cntCD = 'Indonesia' | |
| else: | |
| cntCD = 'N/A' | |
| return cntCD | |
| except: | |
| cntCD = 'N/A' | |
| return cntCD | |
| def plot_picture(inputDF, debug_ind, var, countryCD, stat): | |
| try: | |
| iDF = inputDF | |
| # Lowercase the column names | |
| iDF.columns = [c.lower() for c in iDF.columns] | |
| # Determine which is Y axis | |
| y_col = [c for c in iDF.columns if c.startswith('y')][0] | |
| # Determine which is X axis | |
| x_col = [c for c in iDF.columns if c.startswith('ds')][0] | |
| # Data Conversion | |
| iDF['y'] = iDF[y_col].astype('float') | |
| iDF['ds'] = iDF[x_col].astype('datetime64[ns]') | |
| # Forecast calculations | |
| # Decreasing the changepoint_prior_scale to 0.001 to make the trend less flexible | |
| m = Prophet(n_changepoints=20, yearly_seasonality=True, changepoint_prior_scale=0.001) | |
| m.fit(iDF) | |
| forecastDF = m.make_future_dataframe(periods=365) | |
| forecastDF = m.predict(forecastDF) | |
| l.logr('15.forecastDF_' + var + '_' + countryCD + '.csv', debug_ind, forecastDF, 'log') | |
| df_M = forecastDF[['ds', 'yhat', 'yhat_lower', 'yhat_upper']] | |
| l.logr('16.df_M_' + var + '_' + countryCD + '.csv', debug_ind, df_M, 'log') | |
| #m.plot_components(df_M) | |
| # Getting Full Country Name | |
| cntCD = countryDet(countryCD) | |
| # Draw forecast results | |
| lbl = str(cntCD) + ' – Covid – ' + stat | |
| m.plot(df_M, xlabel = 'Date', ylabel = lbl) | |
| # Combine all graps in the same page | |
| plt.title(f'Covid Forecasting') | |
| plt.title(lbl) | |
| plt.ylabel('Millions') | |
| plt.show() | |
| return 0 | |
| except Exception as e: | |
| x = str(e) | |
| print(x) | |
| return 1 | |
| def countrySpecificDF(counryDF, val): | |
| try: | |
| countryName = val | |
| df = counryDF | |
| df_lkpFile = df[(df['CountryCode'] == val)] | |
| return df_lkpFile | |
| except: | |
| df = p.DataFrame() | |
| return df | |
| def main(): | |
| try: | |
| var1 = datetime.datetime.now().strftime("%Y-%m-%d_%H-%M-%S") | |
| print('*' *60) | |
| DInd = 'Y' | |
| NC = 'New Confirmed' | |
| ND = 'New Dead' | |
| SM = 'data process Successful!' | |
| FM = 'data process Failure!' | |
| print("Calling the custom Package for large file splitting..") | |
| print('Start Time: ' + str(var1)) | |
| countryList = str(cf.conf['coList']).split(',') | |
| # Initiating Log Class | |
| general_log_path = str(cf.conf['LOG_PATH']) | |
| # Enabling Logging Info | |
| logging.basicConfig(filename=general_log_path + 'CovidAPI.log', level=logging.INFO) | |
| # Create the instance of the Covid API Class | |
| x1 = ca.clsCovidAPI() | |
| # Let's pass this to our map section | |
| retDF = x1.searchQry(var1, DInd) | |
| retVal = int(retDF.shape[0]) | |
| if retVal > 0: | |
| print('Successfully Covid Data Extracted from the API-source.') | |
| else: | |
| print('Something wrong with your API-source!') | |
| # Extracting Skeleton Data | |
| df = retDF[['data.code', 'date', 'deaths', 'confirmed', 'recovered', 'new_confirmed', 'new_recovered', 'new_deaths', 'active']] | |
| df.columns = ['CountryCode', 'ReportedDate', 'TotalReportedDead', 'TotalConfirmedCase', 'TotalRecovered', 'NewConfirmed', 'NewRecovered', 'NewDeaths', 'ActiveCaases'] | |
| df.dropna() | |
| print('Returned Skeleton Data Frame: ') | |
| print(df) | |
| l.logr('5.df_' + var1 + '.csv', DInd, df, 'log') | |
| # Working with forecast | |
| # Create the instance of the Forecast API Class | |
| x2 = f.clsForecast() | |
| # Fetching each country name & then get the details | |
| cnt = 6 | |
| for i in countryList: | |
| try: | |
| cntryIndiv = i.strip() | |
| print('Country Porcessing: ' + str(cntryIndiv)) | |
| # Creating dataframe for each country | |
| # Germany Main DataFrame | |
| dfCountry = countrySpecificDF(df, cntryIndiv) | |
| l.logr(str(cnt) + '.df_' + cntryIndiv + '_' + var1 + '.csv', DInd, dfCountry, 'log') | |
| # Let's pass this to our map section | |
| retDFGenNC = x2.forecastNewConfirmed(dfCountry, DInd, var1) | |
| statVal = str(NC) | |
| a1 = plot_picture(retDFGenNC, DInd, var1, cntryIndiv, statVal) | |
| retDFGenNC_D = x2.forecastNewDead(dfCountry, DInd, var1) | |
| statVal = str(ND) | |
| a2 = plot_picture(retDFGenNC_D, DInd, var1, cntryIndiv, statVal) | |
| cntryFullName = countryDet(cntryIndiv) | |
| if (a1 + a2) == 0: | |
| oprMsg = cntryFullName + ' ' + SM | |
| print(oprMsg) | |
| else: | |
| oprMsg = cntryFullName + ' ' + FM | |
| print(oprMsg) | |
| # Resetting the dataframe value for the next iteration | |
| dfCountry = p.DataFrame() | |
| cntryIndiv = '' | |
| oprMsg = '' | |
| cntryFullName = '' | |
| a1 = 0 | |
| a2 = 0 | |
| statVal = '' | |
| cnt += 1 | |
| except Exception as e: | |
| x = str(e) | |
| print(x) | |
| var2 = datetime.datetime.now().strftime("%Y-%m-%d_%H-%M-%S") | |
| print('End Time: ' + str(var2)) | |
| print('*' *60) | |
| except Exception as e: | |
| x = str(e) | |
| if __name__ == "__main__": | |
| main() |
Let us explore the key snippet –
def countryDet(inputCD):
try:
countryCD = inputCD
if str(countryCD) == 'DE':
cntCD = 'Germany'
elif str(countryCD) == 'BR':
cntCD = 'Brazil'
elif str(countryCD) == 'GB':
cntCD = 'United Kingdom'
elif str(countryCD) == 'US':
cntCD = 'United States'
elif str(countryCD) == 'IN':
cntCD = 'India'
elif str(countryCD) == 'CA':
cntCD = 'Canada'
elif str(countryCD) == 'ID':
cntCD = 'Indonesia'
else:
cntCD = 'N/A'
return cntCD
except:
cntCD = 'N/A'
return cntCD
The application is extracting the full country name based on ISO country code.
# Lowercase the column names
iDF.columns = [c.lower() for c in iDF.columns]
# Determine which is Y axis
y_col = [c for c in iDF.columns if c.startswith('y')][0]
# Determine which is X axis
x_col = [c for c in iDF.columns if c.startswith('ds')][0]
# Data Conversion
iDF['y'] = iDF[y_col].astype('float')
iDF['ds'] = iDF[x_col].astype('datetime64[ns]')
The above script will convert all the column names in lower letters & then convert & cast them with the appropriate data type.
# Forecast calculations
# Decreasing the changepoint_prior_scale to 0.001 to make the trend less flexible
m = Prophet(n_changepoints=20, yearly_seasonality=True, changepoint_prior_scale=0.001)
m.fit(iDF)
forecastDF = m.make_future_dataframe(periods=365)
forecastDF = m.predict(forecastDF)
l.logr('15.forecastDF_' + var + '_' + countryCD + '.csv', debug_ind, forecastDF, 'log')
df_M = forecastDF[['ds', 'yhat', 'yhat_lower', 'yhat_upper']]
l.logr('16.df_M_' + var + '_' + countryCD + '.csv', debug_ind, df_M, 'log')
The above snippet will use the machine-learning driven prophet-API, where the application will fit the model & then predict based on the existing data for a year. Also, we’ve identified the number of changepoints. By default, the prophet-API adds 25 changepoints to the initial 80% of the data set that trend is less flexible.
Prophet allows you to adjust the trend in case there is an overfit or underfit. changepoint_prior_scale helps adjust the strength of the movement & decreasing the changepoint_prior_scale to 0.001 to make it less flexible.
def countrySpecificDF(counryDF, val):
try:
countryName = val
df = counryDF
df_lkpFile = df[(df['CountryCode'] == val)]
return df_lkpFile
except:
df = p.DataFrame()
return df
The application is fetching & creating the country-specific dataframe.
for i in countryList:
try:
cntryIndiv = i.strip()
print('Country Porcessing: ' + str(cntryIndiv))
# Creating dataframe for each country
# Germany Main DataFrame
dfCountry = countrySpecificDF(df, cntryIndiv)
l.logr(str(cnt) + '.df_' + cntryIndiv + '_' + var1 + '.csv', DInd, dfCountry, 'log')
# Let's pass this to our map section
retDFGenNC = x2.forecastNewConfirmed(dfCountry, DInd, var1)
statVal = str(NC)
a1 = plot_picture(retDFGenNC, DInd, var1, cntryIndiv, statVal)
retDFGenNC_D = x2.forecastNewDead(dfCountry, DInd, var1)
statVal = str(ND)
a2 = plot_picture(retDFGenNC_D, DInd, var1, cntryIndiv, statVal)
cntryFullName = countryDet(cntryIndiv)
if (a1 + a2) == 0:
oprMsg = cntryFullName + ' ' + SM
print(oprMsg)
else:
oprMsg = cntryFullName + ' ' + FM
print(oprMsg)
# Resetting the dataframe value for the next iteration
dfCountry = p.DataFrame()
cntryIndiv = ''
oprMsg = ''
cntryFullName = ''
a1 = 0
a2 = 0
statVal = ''
cnt += 1
except Exception as e:
x = str(e)
print(x)
The above snippet will call the function to predict the data & then predict the visual representation based on plotting the data points.
Let us run the application –
And, it will generate the visual representation as follows –

And, here is the folder structure –
Let’s explore the comparison study & try to find out the outcome –
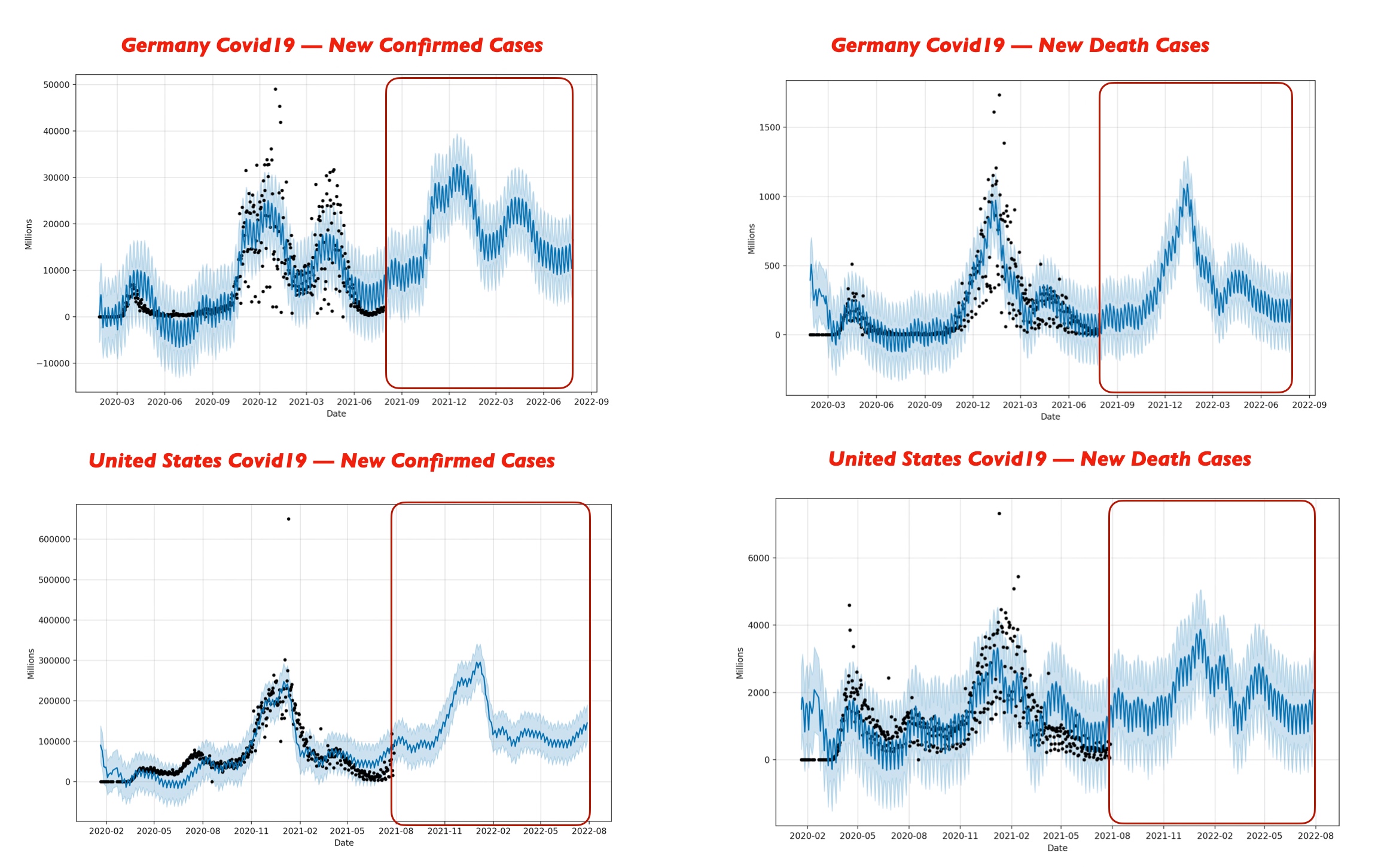

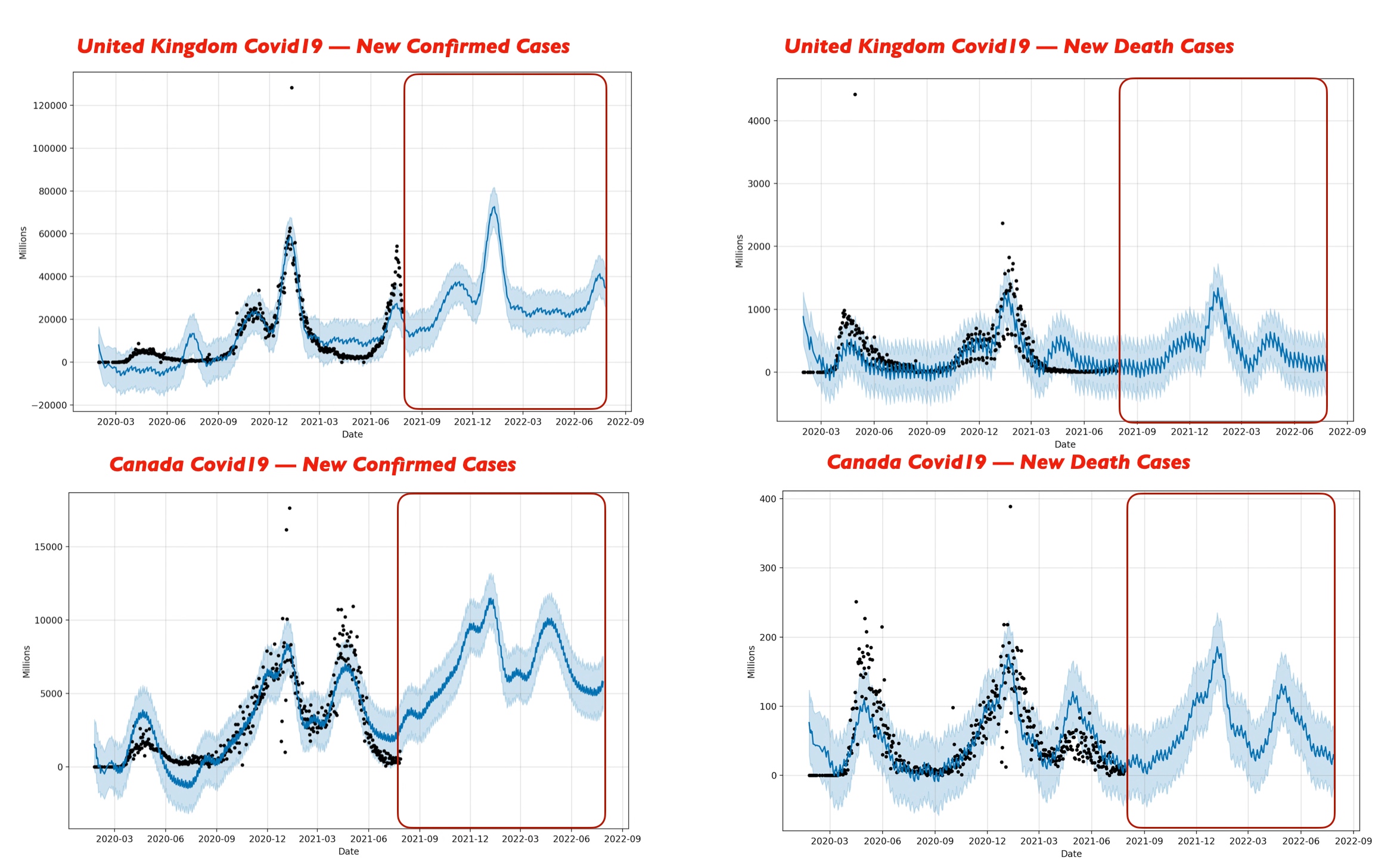
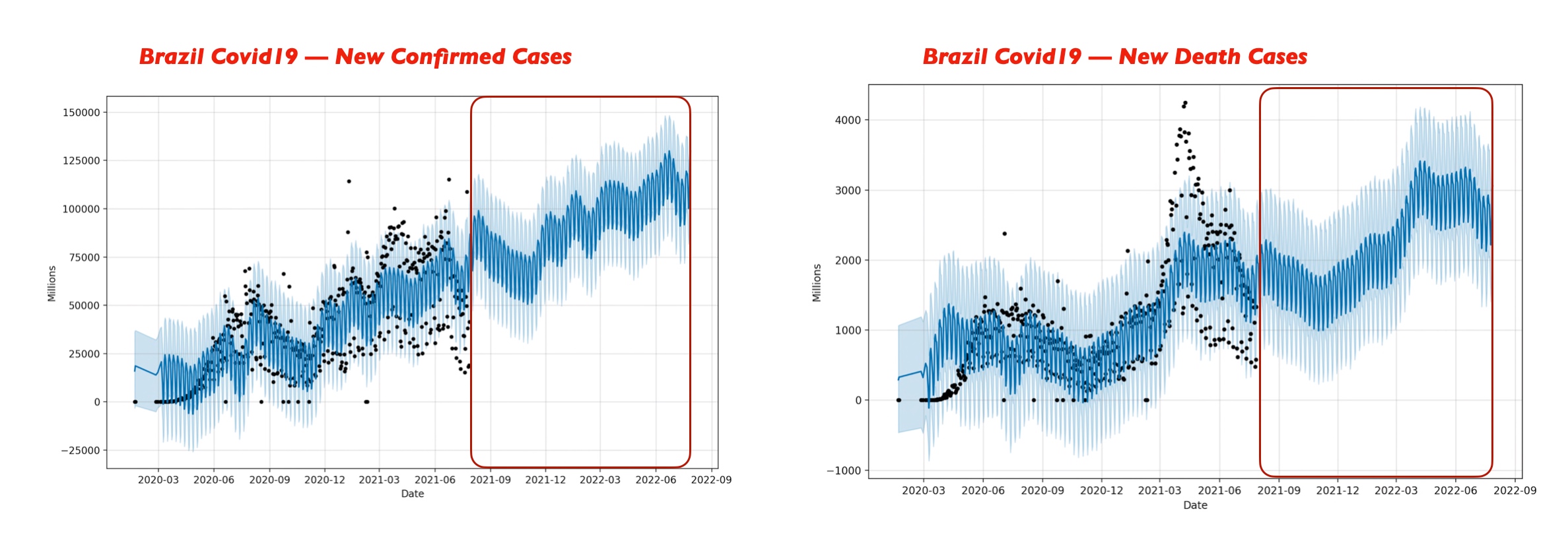
Let us analyze from the above visual data-point.
Conclusion:
Let’s explore the comparison study & try to find out the outcome –
- India may see a rise of new covid cases & it might cross the mark 400,000 during June 2022 & would be the highest among the countries that we’ve considered here including India, Indonesia, Germany, US, UK, Canada & Brazil. The second worst affected country might be the US during the same period. The third affected country will be Indonesia during the same period.
- Canada will be the least affected country during June 2022. The figure should be within 12,000.
- However, death case wise India is not only the leading country. The US, India & Brazil will see almost 4000 or slightly over the 4000 marks.
So, we’ve done it.
You will get the complete codebase in the following Github link.
I’ll bring some more exciting topic in the coming days from the Python verse.
Till then, Happy Avenging! 😀
Note: All the data & scenario posted here are representational data & scenarios & available over the internet & for educational purpose only.
One more thing you need to understand is that this prediction based on limited data points. The actual event may happen differently. Ideally, countries are taking a cue from this kind of analysis & are initiating appropriate measures to avoid the high-curve. And, that is one of the main objective of time series analysis.
There is always a room for improvement of this kind of models & the solution associated with it. I’ve shown the basic ways to achieve the same for the education purpose only.
One thought on “Predicting real-time Covid-19 forecast by analyzing time-series data using Facebook machine-learning API”