Today, I’ll discuss one widespread use case of handling unique & critical data using a new python-based FastDataMask package. But before going through the details, why don’t we view the demo & then go through it?
Great! Let us understand in detail.
Architecture:
Let us understand the flow of events –
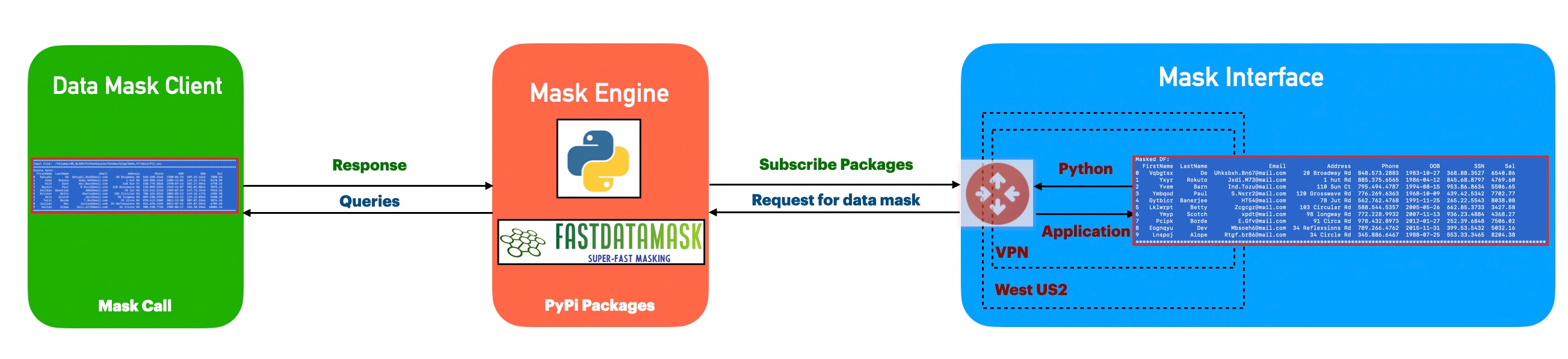
The application first invokes the FastDataMask python package, which accepts individual data in nature & then generates non-recoverable masked data, keeping the data pattern & nature in mind. Hence, anyone can still use the data for their analysis, whereas you can encapsulate the information from unauthorized pairs of eyes. Yet, they can get the essence & close data patterns to decide from any data analysis.
Python Packages:
Following are the python packages that are necessary to develop this brilliant use case –
pip install FastDataMask==0.0.6
pip install imutils==0.5.3
pip install numpy==1.23.2
pip install pandas==1.4.3CODE:
Let us now understand the code. For this use case, we will only discuss three python scripts. However, we need more than these three. However, we have already discussed them in some of the early posts. Hence, we will skip them here.
- clsConfigClient.py (Main configuration file)
This file contains hidden or bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
| ################################################ | |
| #### Written By: SATYAKI DE #### | |
| #### Written On: 15-May-2020 #### | |
| #### Modified On: 15-Feb-2023 #### | |
| #### #### | |
| #### Objective: This script is a config #### | |
| #### file, contains all the keys for #### | |
| #### personal AI-driven voice assistant. #### | |
| #### #### | |
| ################################################ | |
| import os | |
| import platform as pl | |
| class clsConfigClient(object): | |
| Curr_Path = os.path.dirname(os.path.realpath(__file__)) | |
| os_det = pl.system() | |
| if os_det == "Windows": | |
| sep = '\\' | |
| else: | |
| sep = '/' | |
| conf = { | |
| 'APP_ID': 1, | |
| 'ARCH_DIR': Curr_Path + sep + 'arch' + sep, | |
| 'PROFILE_PATH': Curr_Path + sep + 'profile' + sep, | |
| 'LOG_PATH': Curr_Path + sep + 'log' + sep, | |
| 'REPORT_PATH': Curr_Path + sep + 'output' + sep, | |
| 'REPORT_DIR': 'output', | |
| 'SRC_PATH': Curr_Path + sep + 'data' + sep, | |
| 'APP_DESC_1': 'Masking PII Data!', | |
| 'DEBUG_IND': 'N', | |
| 'INIT_PATH': Curr_Path, | |
| 'FILE_NAME': 'PII.csv', | |
| 'TITLE': "Masking PII Data!", | |
| 'PATH' : Curr_Path | |
| } |
Key entries from the above scripts are as follows –
'FILE_NAME': 'PII.csv',This excel is a dummy input file, which looks like this –
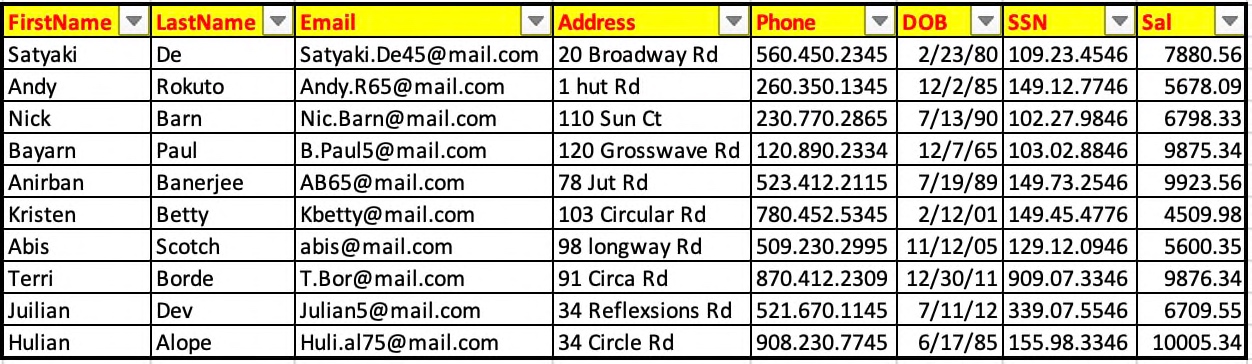
In the above screenshot, our applications will use critical information like – First Name, Email, Address, Phone, Date Of Birth, SSN & Sal.
- playPII.py (Main calling python script)
This file contains hidden or bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
| ##################################################### | |
| #### Written By: SATYAKI DE #### | |
| #### Written On: 12-Feb-2023 #### | |
| #### Modified On 16-Feb-2023 #### | |
| #### #### | |
| #### Objective: This is the main calling #### | |
| #### python script that will invoke the #### | |
| #### newly created light data masking class. #### | |
| #### #### | |
| ##################################################### | |
| import pandas as p | |
| import clsL as cl | |
| from clsConfigClient import clsConfigClient as cf | |
| import datetime | |
| from FastDataMask import clsCircularList as ccl | |
| # Disbling Warning | |
| def warn(*args, **kwargs): | |
| pass | |
| import warnings | |
| warnings.warn = warn | |
| ###################################### | |
| ### Get your global values #### | |
| ###################################### | |
| debug_ind = 'Y' | |
| charList = ccl.clsCircularList() | |
| CurrPath = cf.conf['SRC_PATH'] | |
| FileName = cf.conf['FILE_NAME'] | |
| ###################################### | |
| #### Global Flag ######## | |
| ###################################### | |
| ###################################### | |
| ### Wrapper functions to invoke ### | |
| ### the desired class from newly ### | |
| ### built class. ### | |
| ###################################### | |
| def mask_email(email): | |
| try: | |
| maskedEmail = charList.maskEmail(email) | |
| return maskedEmail | |
| except: | |
| return '' | |
| def mask_phone(phone): | |
| try: | |
| maskedPhone = charList.maskPhone(phone) | |
| return maskedPhone | |
| except: | |
| return '' | |
| def mask_name(flname): | |
| try: | |
| maskedFLName = charList.maskFLName(flname) | |
| return maskedFLName | |
| except: | |
| return '' | |
| def mask_date(dt): | |
| try: | |
| maskedDate = charList.maskDate(dt) | |
| return maskedDate | |
| except: | |
| return '' | |
| def mask_uniqueid(unqid): | |
| try: | |
| maskedUnqId = charList.maskSSN(unqid) | |
| return maskedUnqId | |
| except: | |
| return '' | |
| def mask_sal(sal): | |
| try: | |
| maskedSal = charList.maskSal(sal) | |
| return maskedSal | |
| except: | |
| return '' | |
| ###################################### | |
| ### End of wrapper functions. ### | |
| ###################################### | |
| def main(): | |
| try: | |
| var = datetime.datetime.now().strftime("%Y-%m-%d_%H-%M-%S") | |
| print('*'*120) | |
| print('Start Time: ' + str(var)) | |
| print('*'*120) | |
| inputFile = CurrPath + FileName | |
| print('Input File: ', inputFile) | |
| df = p.read_csv(inputFile) | |
| print('*'*120) | |
| print('Source Data: ') | |
| print(df) | |
| print('*'*120) | |
| hdr = list(df.columns.values) | |
| print('Headers:', hdr) | |
| df["MaskedFirstName"] = df["FirstName"].apply(mask_name) | |
| df["MaskedEmail"] = df["Email"].apply(mask_email) | |
| df["MaskedPhone"] = df["Phone"].apply(mask_phone) | |
| df["MaskedDOB"] = df["DOB"].apply(mask_date) | |
| df["MaskedSSN"] = df["SSN"].apply(mask_uniqueid) | |
| df["MaskedSal"] = df["Sal"].apply(mask_sal) | |
| # Dropping old columns | |
| df.drop(['FirstName','Email','Phone','DOB','SSN', 'Sal'], axis=1, inplace=True) | |
| # Renaming columns | |
| df.rename(columns={'MaskedFirstName': 'FirstName'}, inplace=True) | |
| df.rename(columns={'MaskedEmail': 'Email'}, inplace=True) | |
| df.rename(columns={'MaskedPhone': 'Phone'}, inplace=True) | |
| df.rename(columns={'MaskedDOB': 'DOB'}, inplace=True) | |
| df.rename(columns={'MaskedSSN': 'SSN'}, inplace=True) | |
| df.rename(columns={'MaskedSal': 'Sal'}, inplace=True) | |
| # Repositioning columns of dataframe | |
| df = df[hdr] | |
| print('Masked DF: ') | |
| print(df) | |
| print('*'*120) | |
| var1 = datetime.datetime.now().strftime("%Y-%m-%d_%H-%M-%S") | |
| print('End Time: ' + str(var1)) | |
| except Exception as e: | |
| x = str(e) | |
| print('Error: ', x) | |
| if __name__ == "__main__": | |
| main() |
Let us understand the key lines in details –
def mask_email(email):
try:
maskedEmail = charList.maskEmail(email)
return maskedEmail
except:
return ''
def mask_phone(phone):
try:
maskedPhone = charList.maskPhone(phone)
return maskedPhone
except:
return ''
def mask_name(flname):
try:
maskedFLName = charList.maskFLName(flname)
return maskedFLName
except:
return ''
def mask_date(dt):
try:
maskedDate = charList.maskDate(dt)
return maskedDate
except:
return ''
def mask_uniqueid(unqid):
try:
maskedUnqId = charList.maskSSN(unqid)
return maskedUnqId
except:
return ''
def mask_sal(sal):
try:
maskedSal = charList.maskSal(sal)
return maskedSal
except:
return ''These functions take a value as input and attempt to mask it using the corresponding masking method from the charList module. If the masking is successful, the process will return a masked value per input; otherwise, the application will return an empty string.
More specifically, the functions are:
- mask_email: masks the email address provided as input
- mask_phone: masks the phone number provided as input
- mask_name: masks the first and last name supplied as input
- mask_date: masks the date provided as input
- mask_uniqueid: masks the unique ID (e.g., Social Security Number) provided as input
- mask_sal: masks the salary supplied as input
The functions use a try-except block to handle any exceptions that may arise when calling the corresponding masking method from the charList module. If the masking method raises an exception, the function will return an empty string to handle cases where the input value is invalid, or the masking method fails for another reason.
inputFile = CurrPath + FileName
df = p.read_csv(inputFile)
hdr = list(df.columns.values)
df["MaskedFirstName"] = df["FirstName"].apply(mask_name)
df["MaskedEmail"] = df["Email"].apply(mask_email)
df["MaskedPhone"] = df["Phone"].apply(mask_phone)
df["MaskedDOB"] = df["DOB"].apply(mask_date)
df["MaskedSSN"] = df["SSN"].apply(mask_uniqueid)
df["MaskedSal"] = df["Sal"].apply(mask_sal)
# Dropping old columns
df.drop(['FirstName','Email','Phone','DOB','SSN', 'Sal'], axis=1, inplace=True)
# Renaming columns
df.rename(columns={'MaskedFirstName': 'FirstName'}, inplace=True)
df.rename(columns={'MaskedEmail': 'Email'}, inplace=True)
df.rename(columns={'MaskedPhone': 'Phone'}, inplace=True)
df.rename(columns={'MaskedDOB': 'DOB'}, inplace=True)
df.rename(columns={'MaskedSSN': 'SSN'}, inplace=True)
df.rename(columns={'MaskedSal': 'Sal'}, inplace=True)- The first line inputFile = CurrPath + FileName concatenates the current working directory path (CurrPath) with the name of a file (FileName) and assigns the resulting file path to a variable inputFile.
- The second line df = p.read_csv(inputFile) – reads the file located at inputFile into a Pandas DataFrame object called df.
- The following few lines apply certain functions (mask_name, mask_email, mask_phone, mask_date, mask_uniqueid, and mask_sal) to specific columns in the DataFrame to mask sensitive data. These functions likely perform some data masking or obfuscation on the input data.
- The following line df.drop([‘FirstName’,’Email’,’Phone’,’DOB’,’SSN’, ‘Sal’], axis=1, inplace=True) drops the original columns that we are supposed to mask (i.e., ‘FirstName’, ‘Email’, ‘Phone’, ‘DOB’, ‘SSN’, and ‘Sal’) from the DataFrame.
- The remaining lines rename the masked columns to their original names (i.e., ‘MaskedFirstName’ is renamed to ‘FirstName’, ‘MaskedEmail’ is renamed to ‘Email’, and so on).
Overall, this code reads in a file, masking specific sensitive columns, then outputting a new file with the masked data.
Now, let’s compare the output against the source data –


As you can see the blue highlighted columns are the masked column & you can compare the data pattern against the source.
So, finally, we’ve done it.
I know that this post is relatively bigger than my earlier post. But, I think, you can get all the details once you go through it.
You will get the complete codebase in the following GitHub link.
I’ll bring some more exciting topics in the coming days from the Python verse. Please share & subscribe to my post & let me know your feedback.
Till then, Happy Avenging! 🙂
Note: All the data & scenarios posted here are representational data & scenarios & available over the internet & for educational purposes only. Some of the images (except my photo) we’ve used are available over the net. We don’t claim ownership of these images. There is always room for improvement & especially in the prediction quality.