
Today, I will discuss our Virtual personal assistant (SJ) with a combination of AI-driven APIs, which is now operational in Python. We will use the three most potent APIs using OpenAI, Rev-AI & Pyttsx3. Why don’t we see the demo first?
Great! Let us understand we can leverage this by writing a tiny snippet using this new AI model.
Architecture:
Let us understand the flow of events –
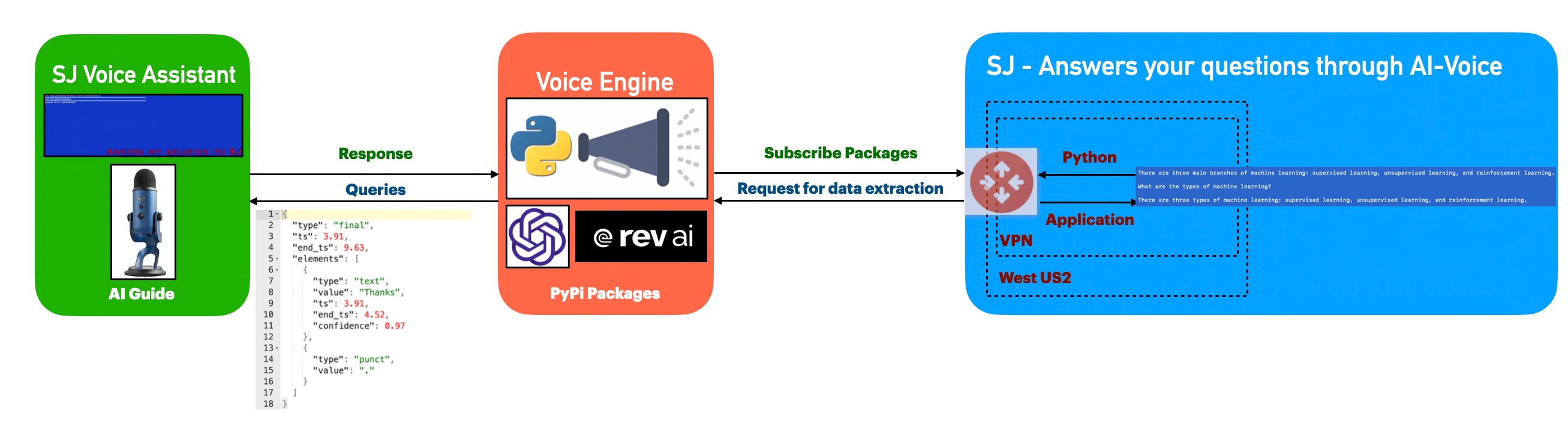
The application first invokes the API to capture the audio spoken through the audio device & then translate that into text, which is later parsed & shared as input by the openai for the response of the posted queries. Once, OpenAI shares the response, the python-based engine will take the response & using pyttsx3 to convert them to voice.
Python Packages:
Following are the python packages that are necessary to develop this brilliant use case –
pip install openai==0.25.0
pip install PyAudio==0.2.13
pip install playsound==1.3.0
pip install pandas==1.5.2
pip install rev-ai==2.17.1
pip install six==1.16.0
pip install websocket-client==0.59.0CODE:
Let us now understand the code. For this use case, we will only discuss three python scripts. However, we need more than these three. However, we have already discussed them in some of the early posts. Hence, we will skip them here.
- clsConfigClient.py (Main configuration file)
This file contains hidden or bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
| ################################################ | |
| #### Written By: SATYAKI DE #### | |
| #### Written On: 15-May-2020 #### | |
| #### Modified On: 31-Dec-2022 #### | |
| #### #### | |
| #### Objective: This script is a config #### | |
| #### file, contains all the keys for #### | |
| #### personal AI-driven voice assistant. #### | |
| #### #### | |
| ################################################ | |
| import os | |
| import platform as pl | |
| class clsConfigClient(object): | |
| Curr_Path = os.path.dirname(os.path.realpath(__file__)) | |
| os_det = pl.system() | |
| if os_det == "Windows": | |
| sep = '\\' | |
| else: | |
| sep = '/' | |
| conf = { | |
| 'APP_ID': 1, | |
| 'ARCH_DIR': Curr_Path + sep + 'arch' + sep, | |
| 'PROFILE_PATH': Curr_Path + sep + 'profile' + sep, | |
| 'LOG_PATH': Curr_Path + sep + 'log' + sep, | |
| 'REPORT_PATH': Curr_Path + sep + 'output' + sep, | |
| 'REPORT_DIR': 'output', | |
| 'SRC_PATH': Curr_Path + sep + 'data' + sep, | |
| 'CODE_PATH': Curr_Path + sep + 'Code' + sep, | |
| 'APP_DESC_1': 'Personal Voice Assistant (SJ)!', | |
| 'DEBUG_IND': 'N', | |
| 'INIT_PATH': Curr_Path, | |
| 'TITLE': "Personal Voice Assistant (SJ)!", | |
| 'PATH' : Curr_Path, | |
| 'OPENAI_API_KEY': "sk-aapwfMWDuFE5XXXUr2BH", | |
| 'REVAI_API_KEY': "02ks6kFhEKjdhdure8474JJAJJ945958_h8P_DEKDNkK6DwNNNHU17aRtCw", | |
| 'MODEL_NAME': "code-davinci-002", | |
| "speedSpeech": 170, | |
| "speedPitch": 0.8, | |
| "soundRate": 44100, | |
| "contentType": "audio/x-raw", | |
| "layout": "interleaved", | |
| "format": "S16LE", | |
| "channels": 1 | |
| } |
A few of the essential entries from the above snippet, which one should be looked for, are –
'OPENAI_API_KEY': "sk-aapwfMWDuFE5XXXUr2BH",
'REVAI_API_KEY': "02ks6kFhEKjdhdure8474JJAJJ945958_h8P_DEKDNkK6DwNNNHU17aRtCw",
'MODEL_NAME': "code-davinci-002",
"speedSpeech": 170,
"speedPitch": 0.8,
"soundRate": 44100,
"contentType": "audio/x-raw",
"layout": "interleaved",
"format": "S16LE",
"channels": 1Note that, all the API-key are not real. You need to generate your own key.
- clsText2Voice.py (The python script that will convert text to voice)
This file contains hidden or bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
| ############################################### | |
| #### Written By: SATYAKI DE #### | |
| #### Written On: 27-Oct-2019 #### | |
| #### Modified On 28-Jan-2023 #### | |
| #### #### | |
| #### Objective: Main class converting #### | |
| #### text to voice using third-party API. #### | |
| ############################################### | |
| import pyttsx3 | |
| from clsConfigClient import clsConfigClient as cf | |
| class clsText2Voice: | |
| def __init__(self): | |
| self.speedSpeech = cf.conf['speedSpeech'] | |
| self.speedPitch = cf.conf['speedPitch'] | |
| def getAudio(self, srcString): | |
| try: | |
| speedSpeech = self.speedSpeech | |
| speedPitch = self.speedPitch | |
| engine = pyttsx3.init() | |
| # Set the speed of the speech (in words per minute) | |
| engine.setProperty('rate', speedSpeech) | |
| # Set the pitch of the speech (1.0 is default) | |
| engine.setProperty('pitch', speedPitch) | |
| # Converting to MP3 | |
| engine.say(srcString) | |
| engine.runAndWait() | |
| return 0 | |
| except Exception as e: | |
| x = str(e) | |
| print('Error: ', x) | |
| return 1 |
Some of the important snippet will be as follows –
def getAudio(self, srcString):
try:
speedSpeech = self.speedSpeech
speedPitch = self.speedPitch
engine = pyttsx3.init()
# Set the speed of the speech (in words per minute)
engine.setProperty('rate', speedSpeech)
# Set the pitch of the speech (1.0 is default)
engine.setProperty('pitch', speedPitch)
# Converting to MP3
engine.say(srcString)
engine.runAndWait()
return 0The code is a function that generates speech audio from a given string using the Pyttsx3 library in Python. The function sets the speech rate and pitch using the “speedSpeech” and “speedPitch” properties of the calling object, initializes the Pyttsx3 engine, sets the speech rate and pitch on the engine, speaks the given string, and waits for the speech to finish. The function returns 0 after the speech is finished.
- clsChatEngine.py (This python script will invoke the ChatGPT OpenAI class to initiate the response of the queries in python.)
This file contains hidden or bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
| ##################################################### | |
| #### Written By: SATYAKI DE #### | |
| #### Written On: 26-Dec-2022 #### | |
| #### Modified On 28-Jan-2023 #### | |
| #### #### | |
| #### Objective: This is the main calling #### | |
| #### python script that will invoke the #### | |
| #### ChatGPT OpenAI class to initiate the #### | |
| #### response of the queries in python. #### | |
| ##################################################### | |
| import os | |
| import openai | |
| import json | |
| from clsConfigClient import clsConfigClient as cf | |
| import sys | |
| import errno | |
| # Disbling Warning | |
| def warn(*args, **kwargs): | |
| pass | |
| import warnings | |
| warnings.warn = warn | |
| ############################################### | |
| ### Global Section ### | |
| ############################################### | |
| CODE_PATH=str(cf.conf['CODE_PATH']) | |
| MODEL_NAME=str(cf.conf['MODEL_NAME']) | |
| ############################################### | |
| ### End of Global Section ### | |
| ############################################### | |
| class clsChatEngine: | |
| def __init__(self): | |
| self.OPENAI_API_KEY=str(cf.conf['OPENAI_API_KEY']) | |
| def findFromSJ(self, text): | |
| try: | |
| OPENAI_API_KEY = self.OPENAI_API_KEY | |
| # ChatGPT API_KEY | |
| openai.api_key = OPENAI_API_KEY | |
| print('22'*60) | |
| try: | |
| # Getting response from ChatGPT | |
| response = openai.Completion.create( | |
| engine=MODEL_NAME, | |
| prompt=text, | |
| max_tokens=64, | |
| top_p=1.0, | |
| n=3, | |
| temperature=0, | |
| frequency_penalty=0.0, | |
| presence_penalty=0.0, | |
| stop=["\"\"\""] | |
| ) | |
| except IOError as e: | |
| if e.errno == errno.EPIPE: | |
| pass | |
| print('44'*60) | |
| res = response.choices[0].text | |
| return res | |
| except IOError as e: | |
| if e.errno == errno.EPIPE: | |
| pass | |
| except Exception as e: | |
| x = str(e) | |
| print(x) | |
| print('66'*60) | |
| return x |
Key snippets from the above-script are as follows –
def findFromSJ(self, text):
try:
OPENAI_API_KEY = self.OPENAI_API_KEY
# ChatGPT API_KEY
openai.api_key = OPENAI_API_KEY
print('22'*60)
try:
# Getting response from ChatGPT
response = openai.Completion.create(
engine=MODEL_NAME,
prompt=text,
max_tokens=64,
top_p=1.0,
n=3,
temperature=0,
frequency_penalty=0.0,
presence_penalty=0.0,
stop=["\"\"\""]
)
except IOError as e:
if e.errno == errno.EPIPE:
pass
print('44'*60)
res = response.choices[0].text
return res
except IOError as e:
if e.errno == errno.EPIPE:
pass
except Exception as e:
x = str(e)
print(x)
print('66'*60)
return xThe code is a function that uses OpenAI’s ChatGPT model to generate text based on a given prompt text. The function takes the text to be completed as input and uses an API key stored in the OPENAI_API_KEY property of the calling object to request OpenAI’s API. If the request is successful, the function returns the top completion generated by the model, as stored in the text field of the first item in the choices list of the API response.
The function includes error handling for IOError and Exception. If an IOError occurs, the function checks if the error number is errno.EPIPE and, if it is, returns without doing anything. If an Exception occurs, the function converts the error message to a string and prints it, then returns the string.
- clsVoice2Text.py (This python script will invoke the Rev-AI class to initiate the transformation of audio into the text.)
This file contains hidden or bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
| ##################################################### | |
| #### Written By: SATYAKI DE #### | |
| #### Written On: 26-Dec-2022 #### | |
| #### Modified On 28-Jan-2023 #### | |
| #### #### | |
| #### Objective: This is the main calling #### | |
| #### python script that will invoke the #### | |
| #### Rev-AI class to initiate the transformation #### | |
| #### of audio into the text. #### | |
| ##################################################### | |
| import pyaudio | |
| from rev_ai.models import MediaConfig | |
| from rev_ai.streamingclient import RevAiStreamingClient | |
| from six.moves import queue | |
| import ssl | |
| import json | |
| import pandas as p | |
| import clsMicrophoneStream as ms | |
| import clsL as cl | |
| from clsConfigClient import clsConfigClient as cf | |
| import datetime | |
| # Initiating Log class | |
| l = cl.clsL() | |
| # Bypassing SSL Authentication | |
| try: | |
| _create_unverified_https_context = ssl._create_unverified_context | |
| except AttributeError: | |
| # Legacy python that doesn't verify HTTPS certificates by default | |
| pass | |
| else: | |
| # Handle target environment that doesn't support HTTPS verification | |
| ssl._create_default_https_context = _create_unverified_https_context | |
| # Disbling Warning | |
| def warn(*args, **kwargs): | |
| pass | |
| import warnings | |
| warnings.warn = warn | |
| ###################################### | |
| ### Insert your access token here #### | |
| ###################################### | |
| debug_ind = 'Y' | |
| ################################################################ | |
| ### Sampling rate of your microphone and desired chunk size #### | |
| ################################################################ | |
| class clsVoice2Text: | |
| def __init__(self): | |
| self.OPENAI_API_KEY=str(cf.conf['OPENAI_API_KEY']) | |
| self.rate = cf.conf['soundRate'] | |
| def processVoice(self, var): | |
| try: | |
| OPENAI_API_KEY = self.OPENAI_API_KEY | |
| accessToken = cf.conf['REVAI_API_KEY'] | |
| rate = self.rate | |
| chunk = int(rate/10) | |
| ################################################################ | |
| ### Creates a media config with the settings set for a raw #### | |
| ### microphone input #### | |
| ################################################################ | |
| sampleMC = MediaConfig('audio/x-raw', 'interleaved', 44100, 'S16LE', 1) | |
| streamclient = RevAiStreamingClient(accessToken, sampleMC) | |
| ##################################################################### | |
| ### Opens microphone input. The input will stop after a keyboard #### | |
| ### interrupt. #### | |
| ##################################################################### | |
| with ms.clsMicrophoneStream(rate, chunk) as stream: | |
| ##################################################################### | |
| ### Uses try method to enable users to manually close the stream #### | |
| ##################################################################### | |
| try: | |
| response_gen = '' | |
| response = '' | |
| finalText = '' | |
| ######################################################################### | |
| ### Starts the server connection and thread sending microphone audio #### | |
| ######################################################################### | |
| response_gen = streamclient.start(stream.generator()) | |
| ################################################### | |
| ### Iterates through responses and prints them #### | |
| ################################################### | |
| for response in response_gen: | |
| try: | |
| print('JSON:') | |
| print(response) | |
| r = json.loads(response) | |
| df = p.json_normalize(r["elements"]) | |
| l.logr('1.df_' + var + '.csv', debug_ind, df, 'log') | |
| column_name = "confidence" | |
| if column_name in df.columns: | |
| print('DF:: ') | |
| print(df) | |
| finalText = "".join(df["value"]) | |
| print("TEXT:") | |
| print(finalText) | |
| df = p.DataFrame() | |
| raise Exception | |
| except Exception as e: | |
| x = str(e) | |
| break | |
| streamclient.end() | |
| return finalText | |
| except Exception as e: | |
| x = str(e) | |
| ####################################### | |
| ### Ends the WebSocket connection. #### | |
| ####################################### | |
| streamclient.end() | |
| return '' | |
| except Exception as e: | |
| x = str(e) | |
| print('Error: ', x) | |
| streamclient.end() | |
| return x |
Here is the important snippet from the above code –
def processVoice(self, var):
try:
OPENAI_API_KEY = self.OPENAI_API_KEY
accessToken = cf.conf['REVAI_API_KEY']
rate = self.rate
chunk = int(rate/10)
################################################################
### Creates a media config with the settings set for a raw ####
### microphone input ####
################################################################
sampleMC = MediaConfig('audio/x-raw', 'interleaved', 44100, 'S16LE', 1)
streamclient = RevAiStreamingClient(accessToken, sampleMC)
#####################################################################
### Opens microphone input. The input will stop after a keyboard ####
### interrupt. ####
#####################################################################
with ms.clsMicrophoneStream(rate, chunk) as stream:
#####################################################################
### Uses try method to enable users to manually close the stream ####
#####################################################################
try:
response_gen = ''
response = ''
finalText = ''
############################################
### Starts the server connection ####
### and thread sending microphone audio ####
############################################
response_gen = streamclient.start(stream.generator())
###################################################
### Iterates through responses and prints them ####
###################################################
for response in response_gen:
try:
print('JSON:')
print(response)
r = json.loads(response)
df = p.json_normalize(r["elements"])
l.logr('1.df_' + var + '.csv', debug_ind, df, 'log')
column_name = "confidence"
if column_name in df.columns:
print('DF:: ')
print(df)
finalText = "".join(df["value"])
print("TEXT:")
print(finalText)
df = p.DataFrame()
raise Exception
except Exception as e:
x = str(e)
break
streamclient.end()
return finalText
except Exception as e:
x = str(e)
#######################################
### Ends the WebSocket connection. ####
#######################################
streamclient.end()
return ''
except Exception as e:
x = str(e)
print('Error: ', x)
streamclient.end()
return xThe code is a python function called processVoice() that processes a user’s voice input using the Rev.AI API. The function takes in one argument, “var,” which is not used in the code.
- Let us understand the code –
- First, the function sets several variables, including the Rev.AI API access token, the sample rate, and the chunk size for the audio input.
- Then, it creates a media configuration object for raw microphone input.
- A RevAiStreamingClient object is created using the access token and the media configuration.
- The code opens the microphone input using a statement and the microphone stream class.
- Within the statement, the code starts the server connection and a thread that sends microphone audio to the server.
- The code then iterates through the responses from the server, normalizing the JSON response and storing the values in a pandas data-frame.
- If the “confidence” column exists in the data-frame, the code joins all the values to form the final text and raises an exception.
- If there is an exception, the WebSocket connection is ended, and the final text is returned.
- If there is any error, the WebSocket connection is also ended, and an empty string or the error message is returned.
- clsMicrophoneStream.py (This python script invoke the rev_ai template to capture the chunk voice data & stream it to the service for text translation & return the response to app.)
This file contains hidden or bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
| ##################################################### | |
| #### Modified By: SATYAKI DE #### | |
| #### Modified On 28-Jan-2023 #### | |
| #### #### | |
| #### Objective: This is the main calling #### | |
| #### python script that will invoke the #### | |
| #### rev_ai template to capture the chunk voice #### | |
| #### data & stream it to the service for text #### | |
| #### translation & return the response to app. #### | |
| ##################################################### | |
| import pyaudio | |
| from rev_ai.models import MediaConfig | |
| from six.moves import queue | |
| # Disbling Warning | |
| def warn(*args, **kwargs): | |
| pass | |
| import warnings | |
| warnings.warn = warn | |
| class clsMicrophoneStream(object): | |
| ############################################# | |
| ### Opens a recording stream as a #### | |
| ### generator yielding the audio chunks. #### | |
| ############################################# | |
| def __init__(self, rate, chunk): | |
| self._rate = rate | |
| self._chunk = chunk | |
| ################################################## | |
| ### Create a thread-safe buffer of audio data #### | |
| ################################################## | |
| self._buff = queue.Queue() | |
| self.closed = True | |
| def __enter__(self): | |
| self._audio_interface = pyaudio.PyAudio() | |
| self._audio_stream = self._audio_interface.open( | |
| format=pyaudio.paInt16, | |
| ######################################################### | |
| ### The API currently only supports 1-channel (mono) #### | |
| ### audio. #### | |
| ######################################################### | |
| channels=1, rate=self._rate, | |
| input=True, frames_per_buffer=self._chunk, | |
| #################################################################### | |
| ### Run the audio stream asynchronously to fill the buffer #### | |
| ### object. Run the audio stream asynchronously to fill the #### | |
| ### buffer object. This is necessary so that the input device's #### | |
| ### buffer doesn't overflow while the calling thread makes #### | |
| ### network requests, etc. #### | |
| #################################################################### | |
| stream_callback=self._fill_buffer, | |
| ) | |
| self.closed = False | |
| return self | |
| def __exit__(self, type, value, traceback): | |
| self._audio_stream.stop_stream() | |
| self._audio_stream.close() | |
| self.closed = True | |
| ############################################################### | |
| ### Signal the generator to terminate so that the client's #### | |
| ### streaming_recognize method will not block the process #### | |
| ### termination. #### | |
| ############################################################### | |
| self._buff.put(None) | |
| self._audio_interface.terminate() | |
| def _fill_buffer(self, in_data, frame_count, time_info, status_flags): | |
| ############################################################## | |
| ### Continuously collect data from the audio stream, into #### | |
| ### the buffer. #### | |
| ############################################################## | |
| self._buff.put(in_data) | |
| return None, pyaudio.paContinue | |
| def generator(self): | |
| while not self.closed: | |
| ###################################################################### | |
| ### Use a blocking get() to ensure there's at least one chunk of #### | |
| ### data, and stop iteration if the chunk is None, indicating the #### | |
| ### end of the audio stream. #### | |
| ###################################################################### | |
| chunk = self._buff.get() | |
| if chunk is None: | |
| return | |
| data = [chunk] | |
| ########################################################## | |
| ### Now consume whatever other data's still buffered. #### | |
| ########################################################## | |
| while True: | |
| try: | |
| chunk = self._buff.get(block=False) | |
| if chunk is None: | |
| return | |
| data.append(chunk) | |
| except queue.Empty: | |
| break | |
| yield b''.join(data) |
The key snippet from the above script are as follows –
def __enter__(self):
self._audio_interface = pyaudio.PyAudio()
self._audio_stream = self._audio_interface.open(
format=pyaudio.paInt16,
#########################################################
### The API currently only supports 1-channel (mono) ####
### audio. ####
#########################################################
channels=1, rate=self._rate,
input=True, frames_per_buffer=self._chunk,
####################################################################
### Run the audio stream asynchronously to fill the buffer ####
### object. Run the audio stream asynchronously to fill the ####
### buffer object. This is necessary so that the input device's ####
### buffer doesn't overflow while the calling thread makes ####
### network requests, etc. ####
####################################################################
stream_callback=self._fill_buffer,
)
self.closed = False
return selfThis code is a part of a context manager class (clsMicrophoneStream) and implements the __enter__ method of the class. The method sets up a PyAudio object and opens an audio stream using the PyAudio object. The audio stream is configured to have the following properties:
- Format: 16-bit integer (paInt16)
- Channels: 1 (mono)
- Rate: The rate specified in the instance of the ms.clsMicrophoneStream class.
- Input: True, meaning the audio stream is an input stream, not an output stream.
- Frames per buffer: The chunk specified in the instance of the ms.clsMicrophoneStream class.
- Stream callback: The method self._fill_buffer will be called when the buffer needs more data.
The self.closed attribute is set to False to indicate that the stream is open. The method returns the instance of the class (self).
def __exit__(self, type, value, traceback):
self._audio_stream.stop_stream()
self._audio_stream.close()
self.closed = True
###############################################################
### Signal the generator to terminate so that the client's ####
### streaming_recognize method will not block the process ####
### termination. ####
###############################################################
self._buff.put(None)
self._audio_interface.terminate()The exit method implements the “exit” behavior of a Python context manager. It is automatically called when the context manager is exited using the statement.
The method stops and closes the audio stream, sets the closed attribute to True, and places None in the buffer. The terminate method of the PyAudio interface is then called to release any resources used by the audio stream.
def _fill_buffer(self, in_data, frame_count, time_info, status_flags):
##############################################################
### Continuously collect data from the audio stream, into ####
### the buffer. ####
##############################################################
self._buff.put(in_data)
return None, pyaudio.paContinueThe _fill_buffer method is a callback function that runs asynchronously to continuously collect data from the audio stream and add it to the buffer.
The _fill_buffer method takes four arguments:
- in_data: the raw audio data collected from the audio stream.
- frame_count: the number of frames of audio data that was collected.
- time_info: information about the timing of the audio data.
- status_flags: flags that indicate the status of the audio stream.
The method adds the collected in_data to the buffer using the put method of the buffer object. It returns a tuple of None and pyaudio.paContinue to indicate that the audio stream should continue.
def generator(self):
while not self.closed:
######################################################################
### Use a blocking get() to ensure there's at least one chunk of ####
### data, and stop iteration if the chunk is None, indicating the ####
### end of the audio stream. ####
######################################################################
chunk = self._buff.get()
if chunk is None:
return
data = [chunk]
##########################################################
### Now consume whatever other data's still buffered. ####
##########################################################
while True:
try:
chunk = self._buff.get(block=False)
if chunk is None:
return
data.append(chunk)
except queue.Empty:
break
yield b''.join(data)The logic of the code “def generator(self):” is as follows:
The function generator is an infinite loop that runs until self.closed is True. Within the loop, it uses a blocking get() method of the buffer object (self._buff) to retrieve a chunk of audio data. If the retrieved chunk is None, it means the end of the audio stream has been reached, and the function returns.
If the retrieved chunk is not None, it appends it to the data list. The function then enters another inner loop that continues to retrieve chunks from the buffer using the non-blocking get() method until there are no more chunks left. Finally, the function yields the concatenated chunks of data as a single-byte string.
- SJVoiceAssistant.py (Main calling python script)
This file contains hidden or bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
| ##################################################### | |
| #### Written By: SATYAKI DE #### | |
| #### Written On: 26-Dec-2022 #### | |
| #### Modified On 31-Jan-2023 #### | |
| #### #### | |
| #### Objective: This is the main calling #### | |
| #### python script that will invoke the #### | |
| #### multiple classes to initiate the #### | |
| #### AI-enabled personal assistant, which would #### | |
| #### display & answer the queries through voice. #### | |
| ##################################################### | |
| import pyaudio | |
| from six.moves import queue | |
| import ssl | |
| import json | |
| import pandas as p | |
| import clsMicrophoneStream as ms | |
| import clsL as cl | |
| from clsConfigClient import clsConfigClient as cf | |
| import datetime | |
| import clsChatEngine as ce | |
| import clsText2Voice as tv | |
| import clsVoice2Text as vt | |
| #from signal import signal, SIGPIPE, SIG_DFL | |
| #signal(SIGPIPE,SIG_DFL) | |
| ################################################### | |
| ##### Adding the Instantiating Global classes ##### | |
| ################################################### | |
| x2 = ce.clsChatEngine() | |
| x3 = tv.clsText2Voice() | |
| x4 = vt.clsVoice2Text() | |
| # Initiating Log class | |
| l = cl.clsL() | |
| ################################################### | |
| ##### End of Global Classes ####### | |
| ################################################### | |
| # Bypassing SSL Authentication | |
| try: | |
| _create_unverified_https_context = ssl._create_unverified_context | |
| except AttributeError: | |
| # Legacy python that doesn't verify HTTPS certificates by default | |
| pass | |
| else: | |
| # Handle target environment that doesn't support HTTPS verification | |
| ssl._create_default_https_context = _create_unverified_https_context | |
| # Disbling Warning | |
| def warn(*args, **kwargs): | |
| pass | |
| import warnings | |
| warnings.warn = warn | |
| ###################################### | |
| ### Insert your access token here #### | |
| ###################################### | |
| debug_ind = 'Y' | |
| ###################################### | |
| #### Global Flag ######## | |
| ###################################### | |
| def main(): | |
| try: | |
| spFlag = True | |
| var = datetime.datetime.now().strftime("%Y-%m-%d_%H-%M-%S") | |
| print('*'*120) | |
| print('Start Time: ' + str(var)) | |
| print('*'*120) | |
| exitComment = 'THANKS.' | |
| while True: | |
| try: | |
| finalText = '' | |
| if spFlag == True: | |
| finalText = x4.processVoice(var) | |
| else: | |
| pass | |
| val = finalText.upper().strip() | |
| print('Main Return: ', val) | |
| print('Exit Call: ', exitComment) | |
| print('Length of Main Return: ', len(val)) | |
| print('Length of Exit Call: ', len(exitComment)) | |
| if val == exitComment: | |
| break | |
| elif finalText == '': | |
| spFlag = True | |
| else: | |
| print('spFlag::',spFlag) | |
| print('Inside: ', finalText) | |
| resVal = x2.findFromSJ(finalText) | |
| print('ChatGPT Response:: ') | |
| print(resVal) | |
| resAud = x3.getAudio(resVal) | |
| spFlag = False | |
| except Exception as e: | |
| pass | |
| var1 = datetime.datetime.now().strftime("%Y-%m-%d_%H-%M-%S") | |
| print('*'*120) | |
| print('End Time: ' + str(var1)) | |
| print('SJ Voice Assistant exited successfully!') | |
| print('*'*120) | |
| except Exception as e: | |
| x = str(e) | |
| print('Error: ', x) | |
| if __name__ == "__main__": | |
| main() |
And, the key snippet from the above script –
def main():
try:
spFlag = True
var = datetime.datetime.now().strftime("%Y-%m-%d_%H-%M-%S")
print('*'*120)
print('Start Time: ' + str(var))
print('*'*120)
exitComment = 'THANKS.'
while True:
try:
finalText = ''
if spFlag == True:
finalText = x4.processVoice(var)
else:
pass
val = finalText.upper().strip()
print('Main Return: ', val)
print('Exit Call: ', exitComment)
print('Length of Main Return: ', len(val))
print('Length of Exit Call: ', len(exitComment))
if val == exitComment:
break
elif finalText == '':
spFlag = True
else:
print('spFlag::',spFlag)
print('Inside: ', finalText)
resVal = x2.findFromSJ(finalText)
print('ChatGPT Response:: ')
print(resVal)
resAud = x3.getAudio(resVal)
spFlag = False
except Exception as e:
pass
var1 = datetime.datetime.now().strftime("%Y-%m-%d_%H-%M-%S")
print('*'*120)
print('End Time: ' + str(var1))
print('SJ Voice Assistant exited successfully!')
print('*'*120)
except Exception as e:
x = str(e)
print('Error: ', x)The code is a Python script that implements a voice-based chatbot (likely named “SJ Voice Assistant”). The code performs the following operations:
- Initialize the string “exitComment” to “THANKS.” and set the “spFlag” to True.
- Start an infinite loop until a specific condition breaks the loop.
- In the loop, try to process the input voice with a function called “processVoice()” from an object “x4”. Store the result in “finalText.”
- Convert “finalText” to upper case, remove leading/trailing whitespaces, and store it in “val.” Print “Main Return” and “Exit Call” with their length.
- If “val” equals “exitComment,” break the loop. Suppose “finalText” is an empty string; set “spFlag” to True. Otherwise, perform further processing: a. Call the function “findFromSJ()” from an object “x2” with the input “finalText.” Store the result in “resVal.” b. Call the function “getAudio()” from an object “x3” with the input “resVal.” Store the result in “resAud.” Set “spFlag” to False.
- If an exception occurs, catch it and pass (do nothing).
- Finally the application will exit by displaying the following text – “SJ Voice Assistant exited successfully!”
- If an exception occurs outside the loop, catch it and print the error message.
So, finally, we’ve done it.
I know that this post is relatively bigger than my earlier post. But, I think, you can get all the details once you go through it.
You will get the complete codebase in the following GitHub link.
I’ll bring some more exciting topics in the coming days from the Python verse. Please share & subscribe to my post & let me know your feedback.
Till then, Happy Avenging! 🙂
Note: All the data & scenarios posted here are representational data & scenarios & available over the internet & for educational purposes only. Some of the images (except my photo) we’ve used are available over the net. We don’t claim ownership of these images. There is always room for improvement & especially in the prediction quality.
You must be logged in to post a comment.