
Today, I’m very excited to demonstrate an effortless & new way to hack the performance of Python. This post will be a super short & yet crisp presentation of improving the overall performance.
Why not view the demo before going through it?
Isn’t it exciting? Let’s understand the steps to improve your code.
Python Packages:
pip install cythonWhy this way?
Cython is a Python-to-C compiler. It can significantly improve performance for specific tasks, especially those with heavy computation and loops. Also, Cython’s syntax is very similar to Python, which makes it easy to learn.
Let’s consider an example where we calculate the sum of squares for a list of numbers. The code without optimization would look like this:
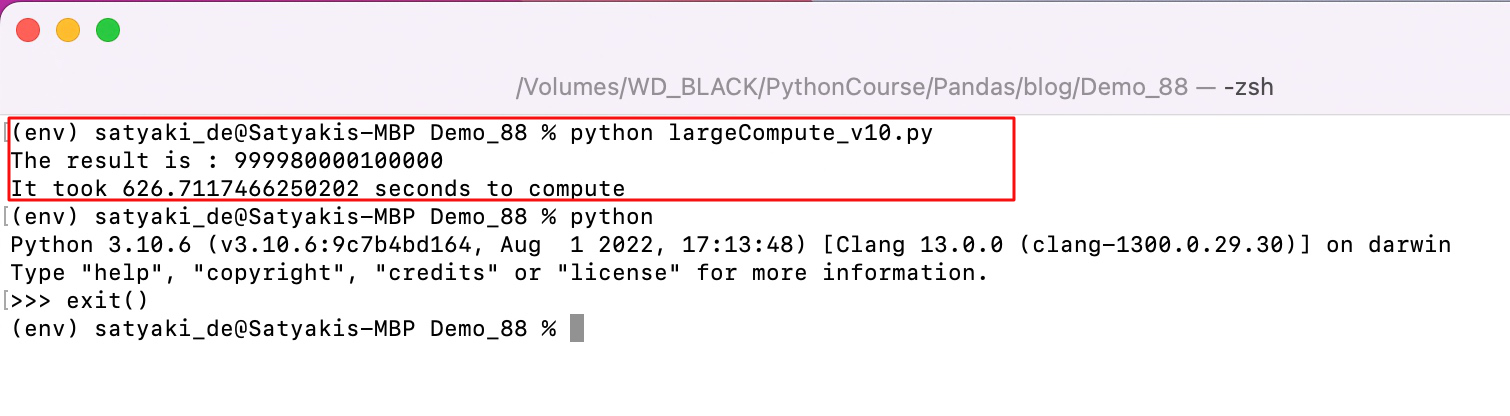
- perfTest_1.py (First untuned Python class.)
#########################################################
#### Written By: SATYAKI DE ####
#### Written On: 31-Jul-2023 ####
#### Modified On 31-Jul-2023 ####
#### ####
#### Objective: This is the main calling ####
#### python script that will invoke the ####
#### first version of accute computation. ####
#### ####
#########################################################
from clsConfigClient import clsConfigClient as cf
import time
start = time.time()
n_val = cf.conf['INPUT_VAL']
def compute_sum_of_squares(n):
return sum([i**2 for i in range(n)])
n = n_val
print(compute_sum_of_squares(n))
print(f"Test - 1: Execution time: {time.time() - start} seconds")
Here, n_val contains the value as – “1000000000”.
Now, let’s optimize it using Cython by installing the abovementioned packages. Then, you will have to create a .pyx file, say “compute.pyx”, with the following code:
cpdef double compute_sum_of_squares(int n):
return sum([i**2 for i in range(n)])
Now, create a setup.py file to compile it:
###########################################################
#### Written By: SATYAKI DE ####
#### Written On: 31-Jul-2023 ####
#### Modified On 31-Jul-2023 ####
#### ####
#### Objective: This is the main calling ####
#### python script that will create the ####
#### compiled library after executing the compute.pyx. ####
#### ####
###########################################################
from setuptools import setup
from Cython.Build import cythonize
setup(
ext_modules = cythonize("compute.pyx")
)
Compile it using the command:
python setup.py build_ext --inplaceThis will look like the following –

Finally, you can import the function from the compiled “.pyx” file inside the improved code.
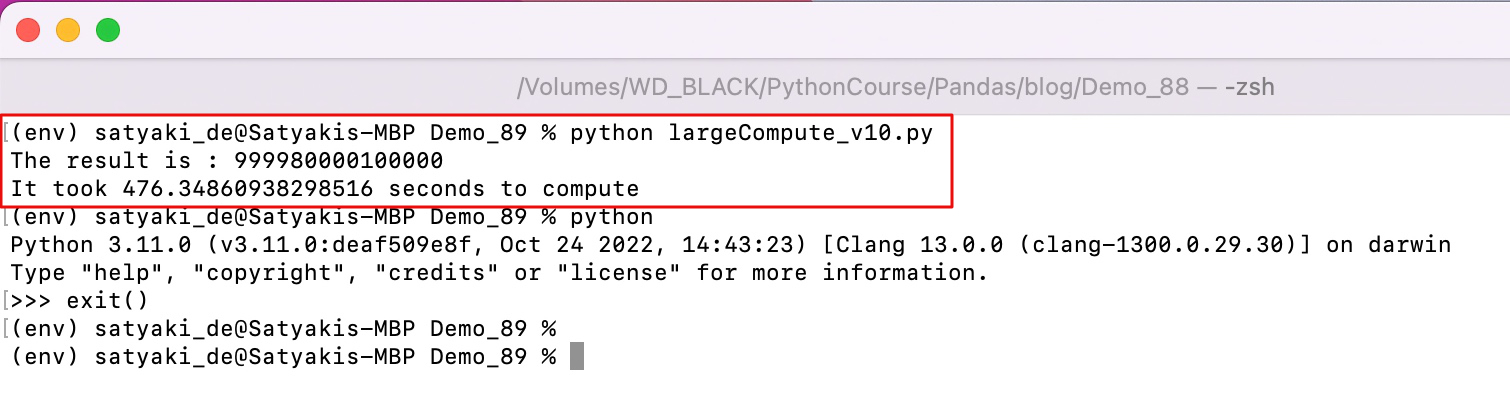
- perfTest_2.py (First untuned Python class.)
#########################################################
#### Written By: SATYAKI DE ####
#### Written On: 31-Jul-2023 ####
#### Modified On 31-Jul-2023 ####
#### ####
#### Objective: This is the main calling ####
#### python script that will invoke the ####
#### optimized & precompiled custom library, which ####
#### will significantly improve the performance. ####
#### ####
#########################################################
from clsConfigClient import clsConfigClient as cf
from compute import compute_sum_of_squares
import time
start = time.time()
n_val = cf.conf['INPUT_VAL']
n = n_val
print(compute_sum_of_squares(n))
print(f"Test - 2: Execution time with multiprocessing: {time.time() - start} seconds")
By compiling to C, Cython can speed up loop and function calls, leading to significant speedup for CPU-bound tasks.
Please note that while Cython can dramatically improve performance, it can make the code more complex and harder to debug. Therefore, starting with regular Python and switching to Cython for the performance-critical parts of the code is recommended.
So, finally, we’ve done it. I know that this post is relatively smaller than my earlier post. But, I think, you can get a good hack to improve some of your long-running jobs by applying this trick.
I’ll bring some more exciting topics in the coming days from the Python verse. Please share & subscribe to my post & let me know your feedback.
Till then, Happy Avenging! 🙂
Note: All the data & scenarios posted here are representational data & scenarios & available over the internet & for educational purposes only. Some of the images (except my photo) we’ve used are available over the net. We don’t claim ownership of these images. There is always room for improvement & especially in the prediction quality.









You must be logged in to post a comment.