
Hi Guys!
As discussed, here is the continuation of the previous post. We’ll explain the regular expression from the library that I’ve created recently.
First, let me share the calling script for regular expression –
##############################################
#### Written By: SATYAKI DE ####
#### Written On: 08-Sep-2019 ####
#### ####
#### Objective: Main calling scripts. ####
##############################################
from dnpr.clsDnpr import clsDnpr
import datetime as dt
import json
# Disbling Warning
def warn(*args, **kwargs):
pass
import warnings
warnings.warn = warn
# Lookup functions from
# Azure cloud SQL DB
def main():
try:
# Initializing the class
t = clsDnpr()
srcJson = [
{"FirstName": "Satyaki", "LastName": "De", "Sal": 1000},
{"FirstName": "Satyaki", "LastName": "De", "Sal": 1000},
{"FirstName": "Archi", "LastName": "Bose", "Sal": 500},
{"FirstName": "Archi", "LastName": "Bose", "Sal": 7000},
{"FirstName": "Deb", "LastName": "Sen", "Sal": 9500}
]
print("4. Checking regular expression functionality!")
print()
var13 = dt.datetime.now().strftime("%Y-%m-%d %H-%M-%S")
print("Start Time: ", str(var13))
print('::Function Regex_Like:: ')
print()
tarColumn = 'FirstName'
print('Target Column for Rexex_Like: ', tarColumn)
inpPattern = r"\bSa"
print('Input Pattern: ', str(inpPattern))
# Invoking the distinct function
tarJson = t.regex_like(srcJson, tarColumn, inpPattern)
print('End of Function Regex_Like!')
print()
print("*" * 157)
print("Output Data: ")
tarJsonFormat = json.dumps(tarJson, indent=1)
print(str(tarJsonFormat))
print("*" * 157)
if not tarJson:
print()
print("No relevant output data!")
print("*" * 157)
else:
print()
print("Relevant output data comes!")
print("*" * 157)
var14 = dt.datetime.now().strftime("%Y-%m-%d %H-%M-%S")
print("End Time: ", str(var14))
var15 = dt.datetime.now().strftime("%Y-%m-%d %H-%M-%S")
print("Start Time: ", str(var15))
print('::Function Regex_Replace:: ')
print()
tarColumn = 'FirstName'
print('Target Column for Rexex_Replace: ', tarColumn)
inpPattern = r"\bSa"
print('Input Pattern: ', str(inpPattern))
replaceString = 'Ka'
print('Replacing Character: ', replaceString)
# Invoking the distinct function
tarJson = t.regex_replace(srcJson, tarColumn, inpPattern, replaceString)
print('End of Function Rexex_Replace!')
print()
print("*" * 157)
print("Output Data: ")
tarJsonFormat = json.dumps(tarJson, indent=1)
print(str(tarJsonFormat))
print("*" * 157)
if not tarJson:
print()
print("No relevant output data!")
print("*" * 157)
else:
print()
print("Relevant output data comes!")
print("*" * 157)
var16 = dt.datetime.now().strftime("%Y-%m-%d %H-%M-%S")
print("End Time: ", str(var16))
var17 = dt.datetime.now().strftime("%Y-%m-%d %H-%M-%S")
print("Start Time: ", str(var17))
print('::Function Regex_Substr:: ')
print()
tarColumn = 'FirstName'
print('Target Column for Regex_Substr: ', tarColumn)
inpPattern = r"\bSa"
print('Input Pattern: ', str(inpPattern))
# Invoking the distinct function
tarJson = t.regex_substr(srcJson, tarColumn, inpPattern)
print('End of Function Regex_Substr!')
print()
print("*" * 157)
print("Output Data: ")
tarJsonFormat = json.dumps(tarJson, indent=1)
print(str(tarJsonFormat))
print("*" * 157)
if not tarJson:
print()
print("No relevant output data!")
print("*" * 157)
else:
print()
print("Relevant output data comes!")
print("*" * 157)
var18 = dt.datetime.now().strftime("%Y-%m-%d %H-%M-%S")
print("End Time: ", str(var18))
print("=" * 157)
print("End of regular expression function!")
print("=" * 157)
except ValueError:
print("No relevant data to proceed!")
except Exception as e:
print("Top level Error: args:{0}, message{1}".format(e.args, e.message))
if __name__ == "__main__":
main()
As per the library, we’ll discuss the following functionalities –
- regex_like
- regex_replace
- regex_substr
Now, let us check how to call these functions.
1. regex_like:
Following is the base skeleton in order to invoke this function –
regex_like(Input Json, Target Column, Pattern To Match) return Output Json
Here are the key lines in the script –
srcJson = [ {"FirstName": "Satyaki", "LastName": "De", "Sal": 1000}, {"FirstName": "Satyaki", "LastName": "De", "Sal": 1000}, {"FirstName": "Archi", "LastName": "Bose", "Sal": 500}, {"FirstName": "Archi", "LastName": "Bose", "Sal": 7000}, {"FirstName": "Deb", "LastName": "Sen", "Sal": 9500} ]# Invoking the distinct function tarJson = t.regex_like(srcJson, tarColumn, inpPattern)
2. regex_replace:
Following is the base skeleton in order to invoke this function –
regex_replace(Input Json, Target Column, Pattern to Replace) return Output Json
Here are the key lines in the script –
tarColumn = 'FirstName' print('Target Column for Rexex_Replace: ', tarColumn) inpPattern = r"\bSa" print('Input Pattern: ', str(inpPattern)) replaceString = 'Ka' print('Replacing Character: ', replaceString) # Invoking the distinct function tarJson = t.regex_replace(srcJson, tarColumn, inpPattern, replaceString)
As you can see, here ‘Sa’ with ‘Ka’ provided it matches the specific pattern in the JSON.
3. regex_replace:
Following is the base skeleton in order to invoke this function –
regex_substr(Input Json, Target Column, Pattern to substring) return Output Json
Here are the key lines –
tarColumn = 'FirstName' print('Target Column for Regex_Substr: ', tarColumn) inpPattern = r"\bSa" print('Input Pattern: ', str(inpPattern)) # Invoking the distinct function tarJson = t.regex_substr(srcJson, tarColumn, inpPattern)
In this case, we’ve subtracted a part of the JSON string & return the final result as JSON.
Let us first see the sample input JSON –

Let us check how it looks when we run the calling script –
- regex_like:

This function will retrieve the elements, which will start with ‘Sa‘. As a result, we’ll see the following two elements in the Payload.
- regex_replace:
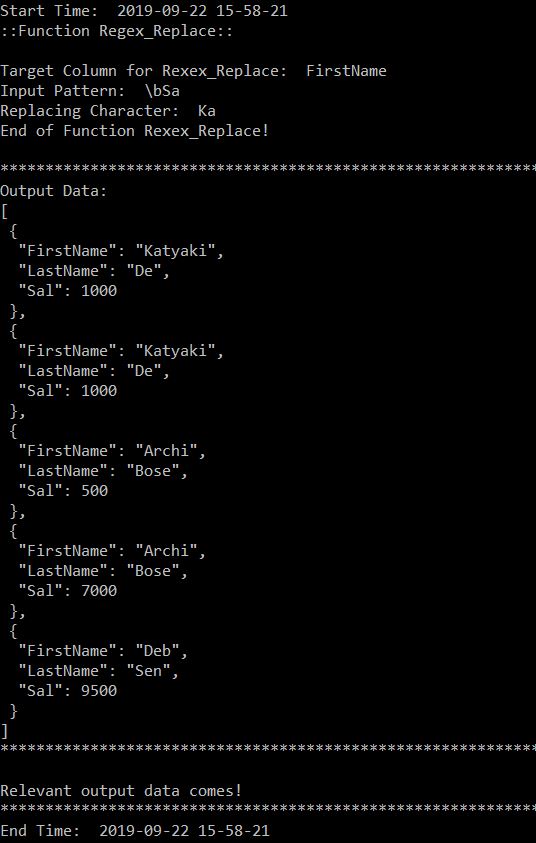
In this case, we’re replacing any string which starts with ‘Sa‘ & replaced with the ‘Ka‘.
- regex_substr:

As you can see that the first element FirstName changed the name from “Satyaki” to “tyaki“.
So, finally, we’ve achieved our target.
I’ll post the next exciting concept very soon.
Till then! Happy Avenging! 😀
N.B.: This is demonstrated for RnD/study purposes. All the data posted here are representational data & available over the internet.
You must be logged in to post a comment.