
Today, I’ll be discussing Oracle Cloud Function interaction with Azure-API through Oracle API Gateway using native python. Again, I want to touch on this subject as I didn’t find lots of relevant material using python over the net.
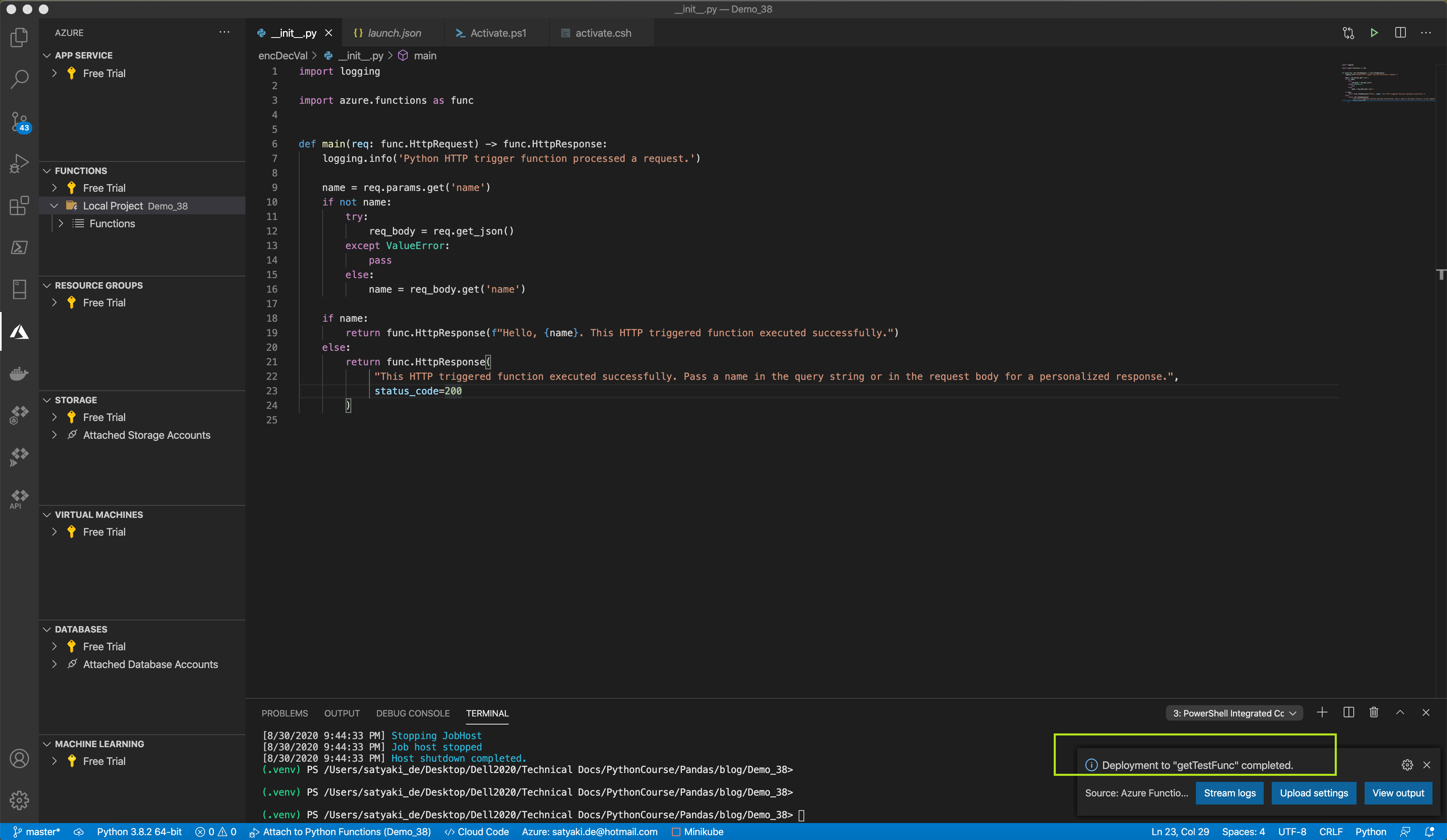
Let’s explore our use case. For this use case, I’ll use an old Azure-API that I’ve developed in early 2019 & shared here during that time.
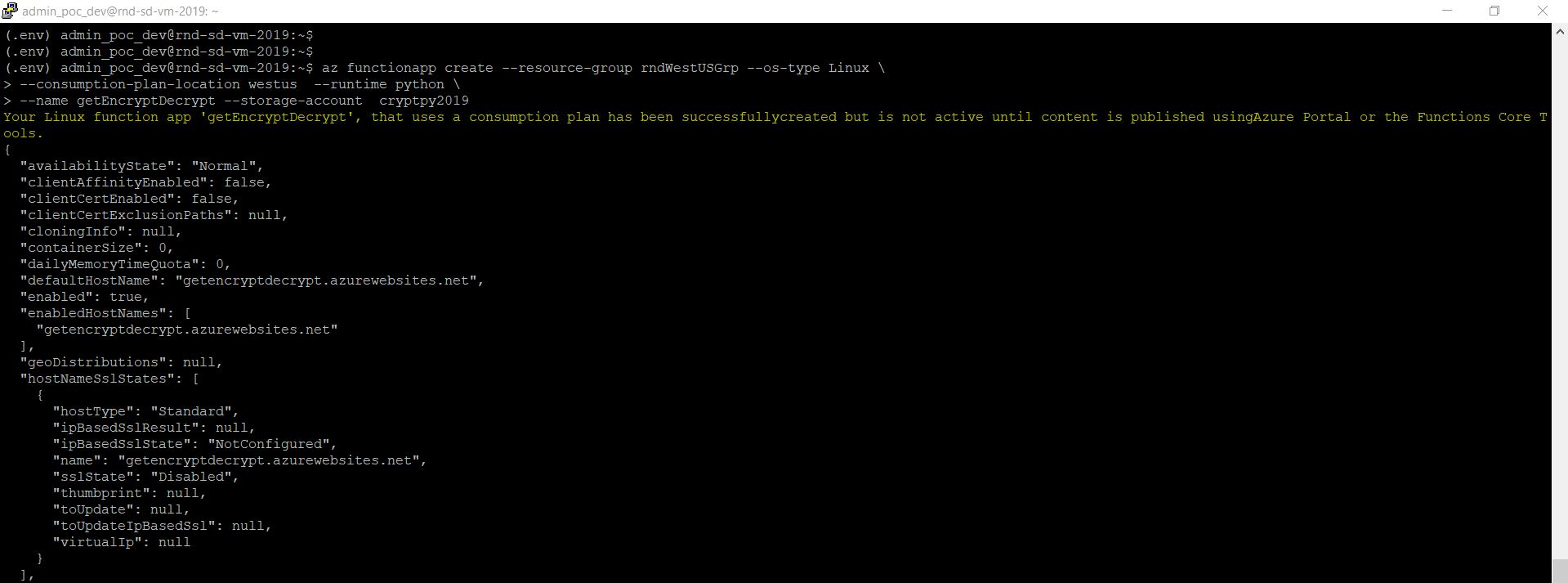
Now, we need to prepare our environment in Oracle-cloud.
Step 1:
We need to configure the virtual network as shown in the below collage picture, which will depict the step-by-step process to create it. For security reasons, I’ve masked sensitive information. It would help if you captured them from your cloud portal.

Make sure you choose the correct options & validate at the end, as shown in the below picture.

If all the information provided is correct, then you should see the following screen.

Step 2:
Now, we need to create an application. As per OCI guidelines, one cannot generate any function or group of functions without the container, known as application.

From the above collage pic, you can see how we create the application by providing all the necessary inputs.
Step 3:
Now, you need to create the registry as shown below –

Your function-container will stay inside it after deployment. To know more about this, click the following link.
Step 4:
If you haven’t generated the auth-token already, then this is the time to render it as shown below –

Step 5:
This next piece of information is highly crucial & on many occasions, you need this piece of information.

Just keep this information handy. I’ll refer to this step whenever we need it. You can get the details here.
Step 6:
Let’s create the gateway now. Please refer to the following collage pics, showing the step-by-step process.

Make sure you have validated it before you proceed to the next step.
Step 7:
Let’s create the function under the application. I find this GUI option is relatively easier than configuring locally & then push it to the OCI. Let’s follow the process shown in the collage of pics mentioned here –

So, you need to click executing series of commands as shown above. And, the good thing is the majority of the critical pieces of commands are automatically generated for you. So, you don’t need to spend lots of time finding out this information.
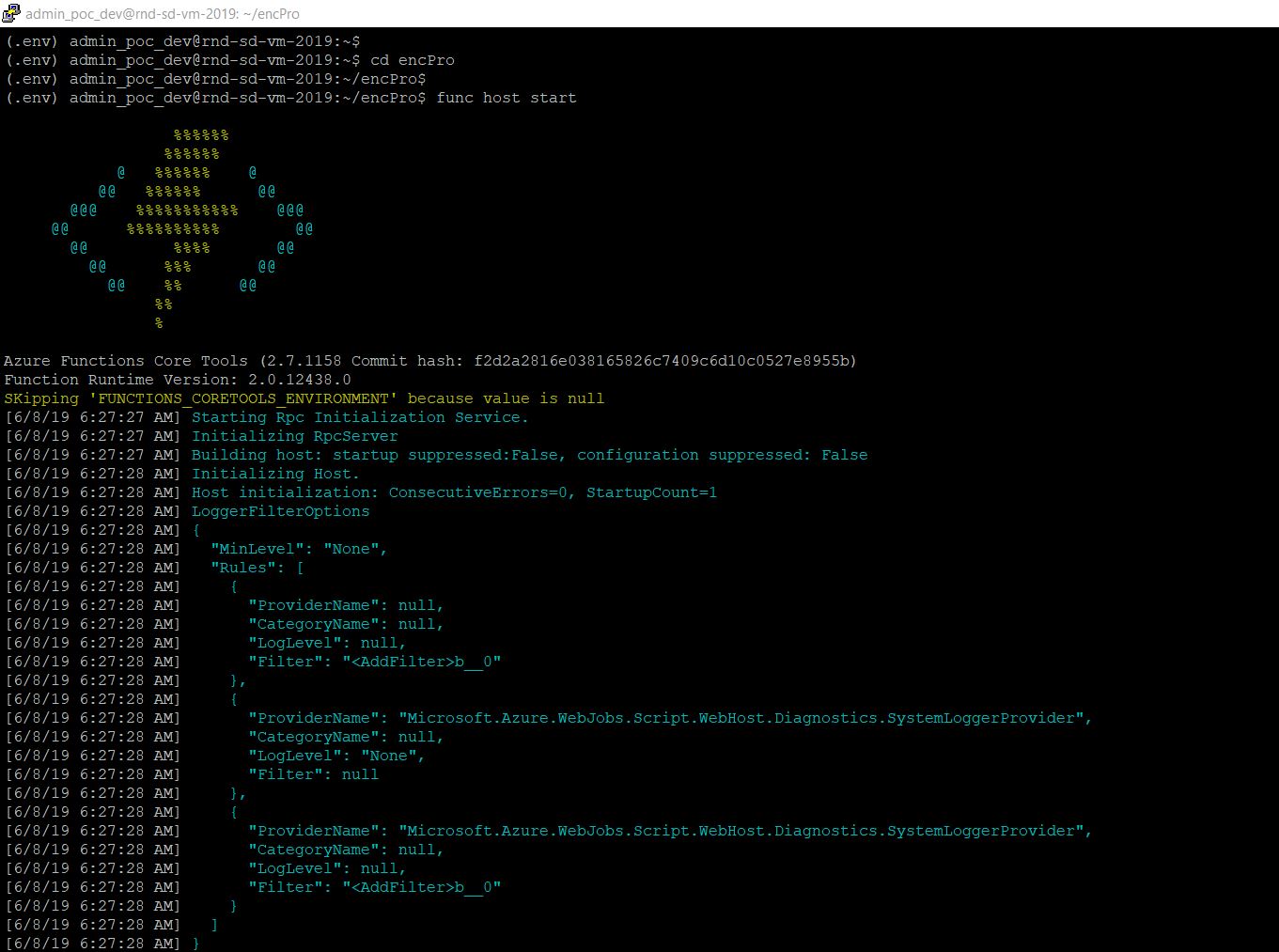
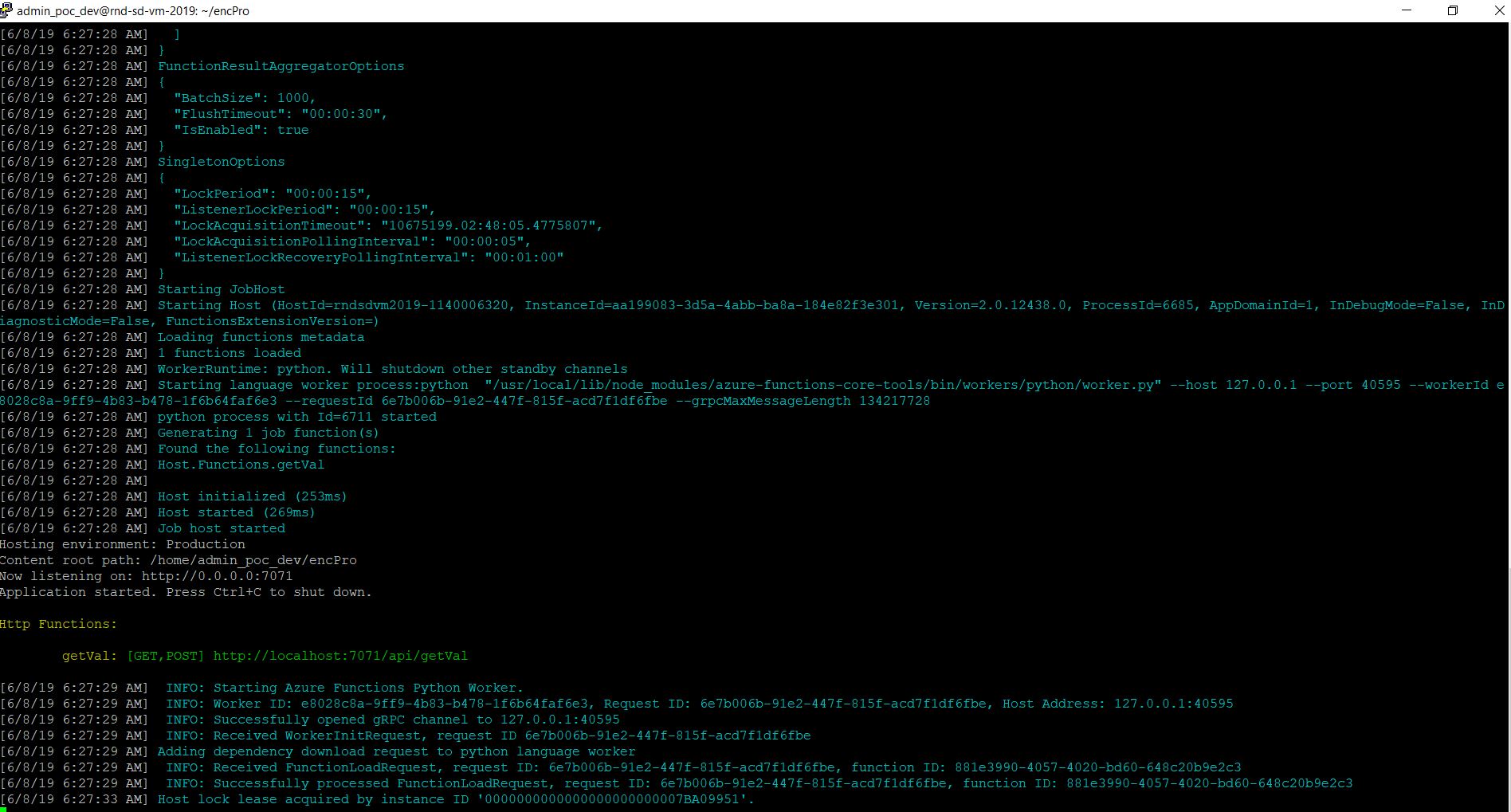
Here, we’ll be executing a series of commands as shown below –

Few necessary commands that I want to discuss here –
fn init --runtime python <function-name>
This command will create a template of scripts based on your supplied language. You need to modify the main script (func.py) later, with your appropriate logic. You can add other scripts as class & refer to that class inside your func.py as well.
For a better deployment & control environment, it is always wise to create a virtual env.
Just like the Azure function, you need to update your requirements.txt file before your deployment command.
pip freeze>requirements.txt
Once we are satisfied with our development; we’ll deploy the application as shown below –

Again, few relevant command that I want to discuss it here –
fn -v deploy --app <Application-Name>
This command will deploy all the oracle functions if they have any changes & push them to the OCI. During this time, it will check all the dependant packages that you are using & tried to install them one-by-one.
If you have already deployed & you want to upgrade your logic, then the deployment option will show something like this –

All the commands are pretty standard & marked with a red-square box. Few necessary commands to discuss –
fn invoke <Application-Name> <Function-Name>
And if you are not using any external API. Ideally, the above command should return the output with the default value. But, for our case, we have used Azure-API, which is outside the OCI. Hence, we need to update few more settings before it works.
Unlike, Azure-Function, you won’t get the link by default when running them locally using Visual Studio Code editor.
Here, you need to execute the following commands as shown in the above picture –
fn inspect function <Application-Name> <Function-Name>
If your deployment is successful, you will see your function docker-image inside your registry as shown below –

To know more about fn-commands, click the following link.
Step 8:
Now, you need to update some policies, which will help API-Gateway to work.

Also, you need to configure your default log for your function, as shown above.
Apart from that, we need to whitelist the port 443 as shown below –

Finally, we need to deploy our existing function into Oracle-Gateway. It would help if you prepared a deployable json object, which will create a channel for the function to interact through the API-gateway deployment.

The deployment json file should looks something like this –
spec.json
This file contains hidden or bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
| { | |
| "routes": [ | |
| { | |
| "path": "/getdata", | |
| "methods": [ | |
| "GET","POST" | |
| ], | |
| "backend": { | |
| "type": "ORACLE_FUNCTIONS_BACKEND", | |
| "functionId": "ocid1.fnfunc.oc1.us-sanjose-1.aaaaxxxxxxxjdjfjfjfjfjfjfjfjfjfjfjfjfjfjfjdsssssss2dfjdfjdjd33376dq" | |
| } | |
| } | |
| ] | |
| } |
You will get more on this from this link.
Make sure that your path prefix should be unique, as shown in the above picture. And, if you want to know the complete steps to prepare your oracle function, you need to go through this master link.
Now, we’re ready to test the application. But, before that, we want to explore the code-base.
Let us explore the codebase now.
1. clsConfig.py ( This is the configuration file for this demo-application)
This file contains hidden or bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
| ############################################### | |
| #### Written By: SATYAKI DE #### | |
| #### Written On: 04-Apr-2020 #### | |
| #### #### | |
| #### Objective: This script is a config #### | |
| #### file, contains all the keys for #### | |
| #### Azure 2 OCI API. Application will #### | |
| #### process these information & perform #### | |
| #### the call to our newly developed Azure #### | |
| #### API in OCI. #### | |
| ############################################### | |
| import os | |
| import platform as pl | |
| class clsConfig(object): | |
| Curr_Path = os.path.dirname(os.path.realpath(__file__)) | |
| os_det = pl.system() | |
| if os_det == "Windows": | |
| sep = '\\' | |
| else: | |
| sep = '/' | |
| conf = { | |
| 'APP_ID': 1, | |
| "comp": "ocid1.compartment.oc1..xxxxxxxxxxxxxxxxxxxxxxxxyyyyyyyyyyyyyyyyyyxxxxxx", | |
| "URL":"https://xxxxxxxxxx.yyyyyyyyyyyyyyyy.net/api/getDynamicCovidStats", | |
| "appType":"application/json", | |
| "conType":"keep-alive", | |
| "limRec":10, | |
| "CACHE":"no-cache", | |
| "colList": "date, state, positive, negative", | |
| "typSel": "Cols", | |
| "LOG_PATH":Curr_Path + sep + 'log' + sep, | |
| "STREAM_NAME":"Covid19-Stream", | |
| "PARTITIONS":1 | |
| } |
2. clsAzureAPI.py ( This is the modified version of old AzureAPI class. We’ve added a new logger, which works inside OCI. No other changes in the man logic. )
This file contains hidden or bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
| ############################################## | |
| #### Written By: SATYAKI DE #### | |
| #### Written On: 07-Mar-2021 #### | |
| #### Modified On 07-Mar-2021 #### | |
| #### #### | |
| #### Objective: Calling Azure dynamic API #### | |
| ############################################## | |
| import json | |
| from clsConfig import clsConfig as cf | |
| import requests | |
| import logging | |
| class clsAzureAPI: | |
| def __init__(self): | |
| self.url = cf.conf['URL'] | |
| self.azure_cache = cf.conf['CACHE'] | |
| self.azure_con = cf.conf['conType'] | |
| self.type = cf.conf['appType'] | |
| self.typSel = cf.conf['typSel'] | |
| self.typVal = cf.conf['colList'] | |
| def searchQry(self): | |
| try: | |
| url = self.url | |
| api_cache = self.azure_cache | |
| api_con = self.azure_con | |
| type = self.type | |
| typSel = self.typSel | |
| typVal = self.typVal | |
| querystring = {"typeSel": typSel, "typeVal": typVal} | |
| strMsg = 'Input JSON: ' + str(querystring) | |
| logging.getLogger().info(strMsg) | |
| headers = { | |
| 'content-type': type, | |
| 'Cache-Control': api_cache, | |
| 'Connection': api_con | |
| } | |
| response = requests.request("GET", url, headers=headers, params=querystring) | |
| ResJson = response.text | |
| jdata = json.dumps(ResJson) | |
| ResJson = json.loads(jdata) | |
| return ResJson | |
| except Exception as e: | |
| ResJson = '' | |
| x = str(e) | |
| print(x) | |
| logging.info(x) | |
| ResJson = {'errorDetails': x} | |
| return ResJson |
3. func.py ( Main calling script. This one auto-genarated by OCI, while creating the functions. We’ve modified it as per our logic. )
This file contains hidden or bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
| ############################################## | |
| #### Written By: SATYAKI DE #### | |
| #### Written On: 20-Mar-2021 #### | |
| #### Modified On 20-Mar-2021 #### | |
| #### #### | |
| #### Objective: Calling Azure dynamic API #### | |
| ############################################## | |
| import io | |
| import json | |
| import logging | |
| from fdk import response | |
| import clsAzureAPI as ca | |
| # Disbling Warning | |
| def warn(*args, **kwargs): | |
| pass | |
| import warnings | |
| warnings.warn = warn | |
| def handler(ctx, data: io.BytesIO = None): | |
| try: | |
| email = "default@gmail.com" | |
| # Checking individual elements | |
| try: | |
| body = json.loads(data.getvalue()) | |
| email = body.get("email") | |
| except (Exception, ValueError) as ex: | |
| logging.getLogger().info('error parsing json payload: ' + str(ex)) | |
| logging.getLogger().info("Calling Oracle Python getCovidData function!") | |
| # Create the instance of the Mock Mulesoft API Class | |
| x1 = ca.clsAzureAPI() | |
| # Let's pass this to our map section | |
| retJson = x1.searchQry() | |
| # Converting JSon to Pandas Dataframe for better readability | |
| # Capturing the JSON Payload | |
| resJson = json.loads(retJson) | |
| return response.Response( | |
| ctx, response_data=json.dumps( | |
| {"status":"Success", "message": resJson}), | |
| headers={"Content-Type": "application/json"} | |
| ) | |
| except Exception as e: | |
| x = str(e) | |
| return response.Response( | |
| ctx, response_data=json.dumps( | |
| {"status":"Failed", "message": x}), | |
| headers={"Content-Type": "application/json"} | |
| ) |
Key snippet that we want to discuss here –
# Checking individual elements
try:
body = json.loads(data.getvalue())
email = body.get("email")
except (Exception, ValueError) as ex:
logging.getLogger().info('error parsing json payload: ' + str(ex))
Checking the individual element in the input payload.
# Create the instance of the Mock Mulesoft API Class
x1 = ca.clsAzureAPI()
# Let's pass this to our map section
retJson = x1.searchQry()
# Converting JSon to Pandas Dataframe for better readability
# Capturing the JSON Payload
resJson = json.loads(retJson)
Now, we’re calling the azure-API class & receiving the response into a JSON variable.
return response.Response(
ctx, response_data=json.dumps(
{"status":"Success", "message": resJson}),
headers={"Content-Type": "application/json"}
)
Sending final response to the client.
4. func.yaml ( Main configuration script. This one auto-genarated by OCI, while creating the functions. )
This file contains hidden or bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
| schema_version: 20180708 | |
| name: getcoviddata | |
| version: 0.0.1 | |
| runtime: python | |
| entrypoint: /python/bin/fdk /function/func.py handler | |
| memory: 256 |
Let’s run it from postman –

During this demo, I’ve realized that the Oracle function yet to get maturity compared to AWS Lambda or Azure function using python. I almost faced similar challenges, which I faced nearly two years back when I tried to implement Azure function using python. However, I’m optimistic that the Oracle Cloud function will mature itself & share an integrated GUI environment to deploy python-based components straight from the IDE, rather than implementing through a CLI-driven approach. Correct me in case if I missed the IDE, which supports this feature.
You can explore my Git associated with this project & download the code from here.
So, finally, we’ve done it. 😀
I’ll bring some more exciting topic in the coming days from the Python verse.
Till then, Happy Avenging! 😀
Note: All the data & scenarios posted here are representational data & scenarios that are available over the internet & for educational purpose only. Also, I’ve used template SDK provided by Oracle & customized it to satisfy our business cases.



































































You must be logged in to post a comment.