
Today, I’m very excited to demonstrate an effortless & new way to integrate SIRI with a controlled Open-AI exposed through a proxy API. So, why this is important; this will give you options to control your ChatGPT environment as per your principles & then you can use a load-balancer (if you want) & exposed that through proxy.

In this post, I’ve directly subscribed to OpenAI & I’m not using OpenAI from Azure. However, I’ll explore that in the future as well.
Before I explain the process to invoke this new library, why not view the demo first & then discuss it?
Isn’t it fascinating? This approach will lead to a whole new ballgame, where you can add SIRI with an entirely new world of knowledge as per your requirements & expose them in a controlled way.
FLOW OF EVENTS:
Let us look at the flow diagram as it captures the sequence of events that unfold as part of the process.
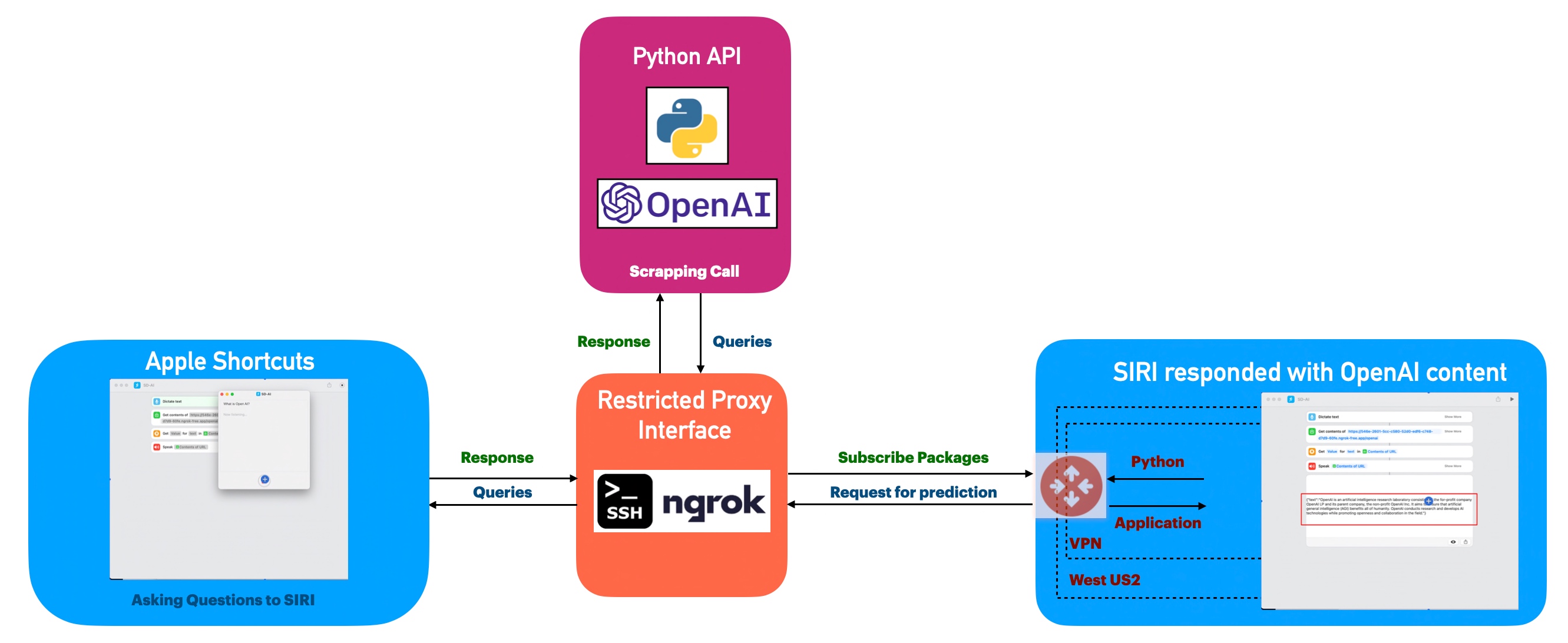
As you can see, Apple Shortcuts triggered the requests through its voice app, which then translates the question to text & then it will invoke the ngrok proxy API, which will eventually trigger the controlled custom API built using Flask & Python to start the Open AI API.
CODE:
Why don’t we go through the code made accessible due to this new library for this particular use case?
- clsConfigClient.py (This is the main calling Python script for the input parameters.)
This file contains hidden or bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
| ################################################ | |
| #### Written By: SATYAKI DE #### | |
| #### Written On: 15-May-2020 #### | |
| #### Modified On: 27-Jun-2023 #### | |
| #### #### | |
| #### Objective: This script is a config #### | |
| #### file, contains all the keys for #### | |
| #### personal OpenAI-based MAC-shortcuts #### | |
| #### enable bot. #### | |
| #### #### | |
| ################################################ | |
| import os | |
| import platform as pl | |
| class clsConfigClient(object): | |
| Curr_Path = os.path.dirname(os.path.realpath(__file__)) | |
| os_det = pl.system() | |
| if os_det == "Windows": | |
| sep = '\\' | |
| else: | |
| sep = '/' | |
| conf = { | |
| 'APP_ID': 1, | |
| 'ARCH_DIR': Curr_Path + sep + 'arch' + sep, | |
| 'PROFILE_PATH': Curr_Path + sep + 'profile' + sep, | |
| 'LOG_PATH': Curr_Path + sep + 'log' + sep, | |
| 'DATA_PATH': Curr_Path + sep + 'data' + sep, | |
| 'MODEL_PATH': Curr_Path + sep + 'model' + sep, | |
| 'TEMP_PATH': Curr_Path + sep + 'temp' + sep, | |
| 'MODEL_DIR': 'model', | |
| 'APP_DESC_1': 'LangChain Demo!', | |
| 'DEBUG_IND': 'N', | |
| 'INIT_PATH': Curr_Path, | |
| 'FILE_NAME': 'Output.csv', | |
| 'MODEL_NAME': 'gpt-3.5-turbo', | |
| 'OPEN_AI_KEY': "sk-Jdhfdyruru9383474HHFJFJFJO6jrlxPKbv6Bgvv", | |
| 'TITLE': "LangChain Demo!", | |
| 'TEMP_VAL': 0.2, | |
| 'PATH' : Curr_Path, | |
| 'MAX_TOKEN' : 60, | |
| 'OUT_DIR': 'data' | |
| } |
Some of the important entries from the above snippet are as follows –
'MODEL_NAME': 'gpt-3.5-turbo',
'OPEN_AI_KEY': "sk-Jdhfdyruru9383474HHFJFJFJO6jrlxPKbv6Bgvv",
'TEMP_VAL': 0.2,TEMP_VAL will help you to control the response in a more authentic manner. It varies between 0 to 1.
- clsJarvis.py (This is the main calling Python script for the input parameters.)
This file contains hidden or bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
| ##################################################### | |
| #### Written By: SATYAKI DE #### | |
| #### Written On: 27-Jun-2023 #### | |
| #### Modified On 28-Jun-2023 #### | |
| #### #### | |
| #### Objective: This is the main calling #### | |
| #### python class that will invoke the #### | |
| #### Flask framework to expose the OpenAI #### | |
| #### API with more control & encapsulate the #### | |
| #### server IPs with proxy layers. #### | |
| #### #### | |
| ##################################################### | |
| import openai | |
| from flask import request, jsonify | |
| from clsConfigClient import clsConfigClient as cf | |
| import os | |
| import clsTemplate as ct | |
| ############################################### | |
| ### Global Section ### | |
| ############################################### | |
| open_ai_Key = cf.conf['OPEN_AI_KEY'] | |
| openai.api_key = open_ai_Key | |
| # Disbling Warning | |
| def warn(*args, **kwargs): | |
| pass | |
| import warnings | |
| warnings.warn = warn | |
| ############################################### | |
| ### End of Global Section ### | |
| ############################################### | |
| class clsJarvis: | |
| def __init__(self): | |
| self.model_name = cf.conf['MODEL_NAME'] | |
| self.max_token = cf.conf['MAX_TOKEN'] | |
| self.temp_val = cf.conf['TEMP_VAL'] | |
| def extractContentInText(self, query): | |
| try: | |
| model_name = self.model_name | |
| max_token = self.max_token | |
| temp_val = self.temp_val | |
| template = ct.templateVal_1 | |
| response = openai.ChatCompletion.create(model=model_name, temperature=temp_val, messages=[{"role": "system", "content": template},{"role": "user", "content": query}]) | |
| inputJson = {"text": response['choices'][0]['message']['content']} | |
| return jsonify(inputJson) | |
| except Exception as e: | |
| discussedTopic = [] | |
| x = str(e) | |
| print('Error: ', x) | |
| template = ct.templateVal_2 | |
| inputJson = {"text": template} | |
| return jsonify(inputJson) |
The key snippets from the above script are as follows –
def extractContentInText(self, query):
try:
model_name = self.model_name
max_token = self.max_token
temp_val = self.temp_val
template = ct.templateVal_1
response = openai.ChatCompletion.create(model=model_name, temperature=temp_val, messages=[{"role": "system", "content": template},{"role": "user", "content": query}])
inputJson = {"text": response['choices'][0]['message']['content']}
return jsonify(inputJson)
except Exception as e:
discussedTopic = []
x = str(e)
print('Error: ', x)
template = ct.templateVal_2
inputJson = {"text": template}
return jsonify(inputJson)The provided Python code snippet defines a method extractContentInText, which interacts with OpenAI’s API to generate a response from OpenAI’s chat model to a user’s query. Here’s a summary of what it does:
- It fetches some predefined model configurations (model_name, max_token, temp_val). These are class attributes defined elsewhere.
- It sets a system message template (initial instruction for the AI model) using ct.templateVal_1. The ct object isn’t defined within this snippet but is likely another predefined object or module in the more extensive program.
- It then calls openai.ChatCompletion.create() to send messages to the AI model and generate a response. The statements include an initial system message and a user’s query.
- The model’s response is extracted and formatted into a JSON object inputJson where the ‘text’ field holds the AI’s response.
- The input JSON object returns a JSON response.
If an error occurs at any stage of this process (caught in the except block), it prints the error, sets a fallback message template using ct.templateVal_2, formats this into a JSON object, and returns it as a JSON response.
Note: The max_token variable is fetched but not used within the function; it might be a remnant of previous code or meant to be used in further development. The code also assumes a predefined ct object and a method called jsonify(), possibly from Flask, for formatting Python dictionaries into JSON format.
- testJarvis.py (This is the main calling Python script.)
This file contains hidden or bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
| ######################################################### | |
| #### Written By: SATYAKI DE #### | |
| #### Written On: 27-Jun-2023 #### | |
| #### Modified On 28-Jun-2023 #### | |
| #### #### | |
| #### Objective: This is the main calling #### | |
| #### python script that will invoke the #### | |
| #### shortcut application created inside MAC #### | |
| #### enviornment including MacBook, IPad or IPhone. #### | |
| #### #### | |
| ######################################################### | |
| import clsL as cl | |
| from clsConfigClient import clsConfigClient as cf | |
| import clsJarvis as jv | |
| import datetime | |
| from flask import Flask, request, jsonify | |
| app = Flask(__name__) | |
| # Disbling Warning | |
| def warn(*args, **kwargs): | |
| pass | |
| import warnings | |
| warnings.warn = warn | |
| ###################################### | |
| ### Get your global values #### | |
| ###################################### | |
| debug_ind = 'Y' | |
| # Initiating Logging Instances | |
| clog = cl.clsL() | |
| cJarvis = jv.clsJarvis() | |
| ###################################### | |
| #### Global Flag ######## | |
| ###################################### | |
| @app.route('/openai', methods=['POST']) | |
| def openai_call(): | |
| try: | |
| var = datetime.datetime.now().strftime("%Y-%m-%d_%H-%M-%S") | |
| print('*'*120) | |
| print('Start Time: ' + str(var)) | |
| print('*'*120) | |
| data = request.get_json() | |
| print('Data::') | |
| print(data) | |
| prompt = data.get('prompt', '') | |
| print('Prompt::') | |
| print(prompt) | |
| res = cJarvis.extractContentInText(str(prompt)) | |
| return res | |
| print('*'*120) | |
| var1 = datetime.datetime.now().strftime("%Y-%m-%d_%H-%M-%S") | |
| print('End Time: ' + str(var1)) | |
| except Exception as e: | |
| x = str(e) | |
| print('Error: ', x) | |
| if __name__ == "__main__": | |
| app.run(host='0.0.0.0') |
Please find the key snippets –
@app.route('/openai', methods=['POST'])
def openai_call():
try:
var = datetime.datetime.now().strftime("%Y-%m-%d_%H-%M-%S")
print('*'*120)
print('Start Time: ' + str(var))
print('*'*120)
data = request.get_json()
print('Data::')
print(data)
prompt = data.get('prompt', '')
print('Prompt::')
print(prompt)
res = cJarvis.extractContentInText(str(prompt))
return res
print('*'*120)
var1 = datetime.datetime.now().strftime("%Y-%m-%d_%H-%M-%S")
print('End Time: ' + str(var1))
except Exception as e:
x = str(e)
print('Error: ', x)The provided Python code defines a route in a Flask web server that listens for POST requests at the ‘/openai’ endpoint. Here’s what it does in detail:
- It records and prints the current time, marking the start of the request handling.
- It retrieves the incoming data from the POST request as JSON with the request.get_json().
- It then extracts the ‘prompt’ from the JSON data. The request defaults to an empty string if no ‘prompt’ is provided in the request.
- The prompt is passed as an argument to the method extractContentInText() object cJarvis. This method is expected to use OpenAI’s API to generate a response from a model given the prompt (as discussed in your previous question). The result of this method call is stored in the variable res.
- The res variable (the model’s response) returns the answer to the client requesting the POST.
- It prints the current time again, marking the end of the request handling (However, this part of the code will never be executed as it places after a return statement).
- If an error occurs during this process, it catches the exception, converts it to a string, and prints the error message.
The cJarvis object used in the cJarvis.extractContentInText(str(prompt)) call is not defined within this code snippet. It is a global object likely defined elsewhere in the more extensive program. The extractContentInText method is the one you shared in your previous question.
Apple Shortcuts:
Now, let us understand the steps in Apple Shortcuts.
You can now set up a Siri Shortcut to call the URL provided by ngrok:
- Open the Shortcuts app on your iPhone.
- Tap the ‘+’ to create a new Shortcut.
- Add an action, search for “URL,” and select the URL action. Enter your ngrok URL here, with the /openai endpoint.
- Add another action, search for “Get Contents of URL.” This step will send a POST request to the URL from the previous activity. Set the method to POST and add a request body with type ‘JSON,’ containing a key ‘prompt’ and a value being the input you want to send to your OpenAI model.
- Optionally, you can add another action, “Show Result” or “Speak Text” to see/hear the result returned from your server.
- Save your Shortcut and give it a name.
You should now be able to activate Siri and say the name of your Shortcut to have it send a request to your server, which will then send a prompt to the OpenAI API and return the response.

Let us understand the “Get contents of” with easy postman screenshots –

As you can see that the newly exposed proxy-API will receive an input named prompt, which will be passed from “Dictate Text.”
So, finally, we’ve done it.
I know that this post is relatively bigger than my earlier post. But, I think, you can get all the details once you go through it.
You will get the complete codebase in the following GitHub link.
I’ll bring some more exciting topics in the coming days from the Python verse. Please share & subscribe to my post & let me know your feedback.
Till then, Happy Avenging! 🙂
Note: All the data & scenarios posted here are representational data & scenarios & available over the internet & for educational purposes only. Some of the images (except my photo) we’ve used are available over the net. We don’t claim ownership of these images. There is always room for improvement & especially in the prediction quality.


























































































































































You must be logged in to post a comment.