
Today, I am planning to demonstrate an IoT use case implemented in Python. I was waiting for my Raspberry Pi to arrive. However, the product that I received was not working as expected. Perhaps, some hardware malfunction. Hence, I was looking for a way to continue with my installment even without the hardware.
I was looking for an alternative way to use an online Raspberry Pi emulator. Recently, Microsoft has introduced integrated Raspberry Pi, which you can directly integrate with Azure IoT. However, I couldn’t find any API, which I could leverage on my Python application.
So, I explored all the possible options & finally come-up with the idea of creating my own IoT-Emulator, which can integrate with any application. With the help from the online materials, I have customized & enhanced them as per my use case & finally come up with this clean application that will demonstrate this use case with clarity.
We’ll showcase this real-time use case, where we would try to capture the events generated by IoT in a real-time dashboard, where the values in the visual display points will be affected as soon as the source data changes.
However, I would like to share the run before we dig deep into this.

Isn’t this exciting? How we can use our custom-built IoT emulator & captures real-time events to Ably Queue, then transform those raw events into more meaningful KPIs. Let’s deep dive then.
Architecture:
Let’s explore the architecture –
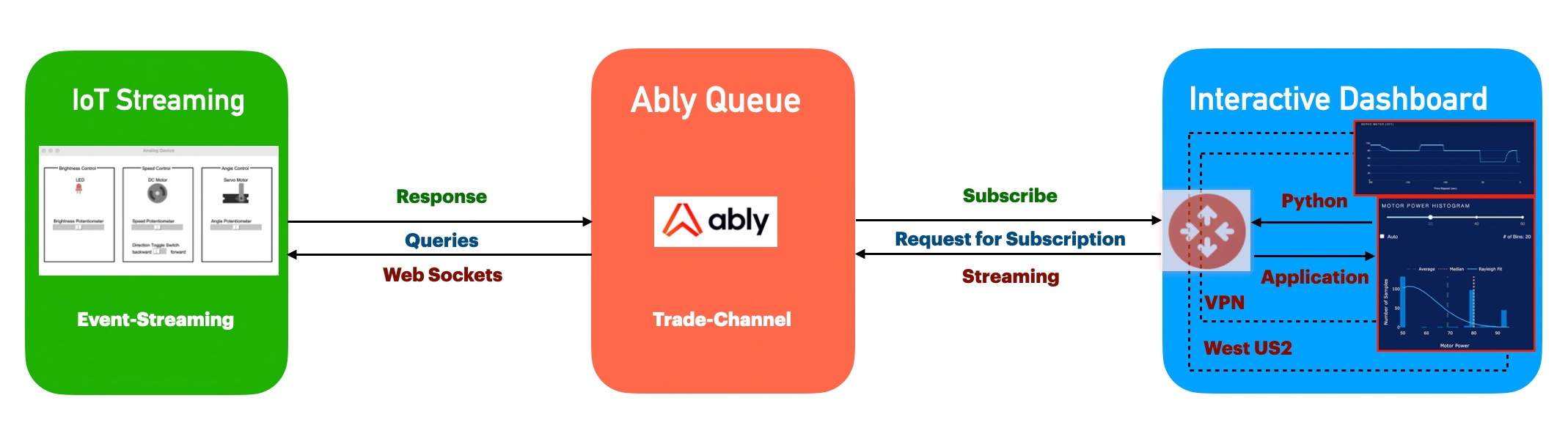
As you can see, the green box is a demo IoT application that generates events & pushes them into the Ably Queue. At the same time, Dashboard consumes the events & transforms them into more meaningful metrics.
Package Installation:
Let us understand the sample packages that require for this task.
Step – 1:
Step – 2:
And, here is the command to install those packages –
pip install dash==1.0.0 pip install numpy==1.16.4 pip install pandas==0.24.2 pip install scipy==1.3.0 pip install gunicorn==19.9.0 pip install ably==1.1.1 pip install tkgpio==0.1
Code:
Since this is an extension to our previous post, we’re not going to discuss other scripts, which we’ve already discussed over there. Instead, we will talk about the enhanced scripts & the new scripts that require for this use case.
1. clsConfig.py (This native Python script contains the configuration entries.)
This file contains hidden or bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
| ################################################ | |
| #### Written By: SATYAKI DE #### | |
| #### Written On: 15-May-2020 #### | |
| #### Modified On: 25-Sep-2021 #### | |
| #### #### | |
| #### Objective: This script is a config #### | |
| #### file, contains all the keys for #### | |
| #### Machine-Learning & streaming dashboard.#### | |
| #### #### | |
| ################################################ | |
| import os | |
| import platform as pl | |
| class clsConfig(object): | |
| Curr_Path = os.path.dirname(os.path.realpath(__file__)) | |
| os_det = pl.system() | |
| if os_det == "Windows": | |
| sep = '\\' | |
| else: | |
| sep = '/' | |
| conf = { | |
| 'APP_ID': 1, | |
| 'ARCH_DIR': Curr_Path + sep + 'arch' + sep, | |
| 'PROFILE_PATH': Curr_Path + sep + 'profile' + sep, | |
| 'LOG_PATH': Curr_Path + sep + 'log' + sep, | |
| 'REPORT_PATH': Curr_Path + sep + 'report', | |
| 'FILE_NAME': Curr_Path + sep + 'data' + sep + 'TradeIn.csv', | |
| 'SRC_PATH': Curr_Path + sep + 'data' + sep, | |
| 'JSONFileNameWithPath': Curr_Path + sep + 'GUI_Config' + sep + 'CircuitConfiguration.json', | |
| 'APP_DESC_1': 'Dash Integration with Ably!', | |
| 'DEBUG_IND': 'N', | |
| 'INIT_PATH': Curr_Path, | |
| 'SUBDIR' : 'data', | |
| 'ABLY_ID': 'WWP309489.93jfkT:32kkdhdJjdued79e', | |
| "URL":"https://corona-api.com/countries/", | |
| "appType":"application/json", | |
| "conType":"keep-alive", | |
| "limRec": 50, | |
| "CACHE":"no-cache", | |
| "MAX_RETRY": 3, | |
| "coList": "DE, IN, US, CA, GB, ID, BR", | |
| "FNC": "NewConfirmed", | |
| "TMS": "ReportedDate", | |
| "FND": "NewDeaths", | |
| "FinData": "Cache.csv" | |
| } |
A few of the new entries, which are essential to this task are -> ABLY_ID, FinData & JSONFileNameWithPath.
2. clsPublishStream.py (This script will publish real-time streaming data coming out from a hosted API sources using another popular third-party service named Ably. Ably mimics pubsub Streaming concept, which might be extremely useful for any start-ups.)
This file contains hidden or bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
| ############################################################### | |
| #### #### | |
| #### Written By: Satyaki De #### | |
| #### Written Date: 26-Jul-2021 #### | |
| #### Modified Date: 08-Sep-2021 #### | |
| #### #### | |
| #### Objective: This script will publish real-time #### | |
| #### streaming data coming out from a hosted API #### | |
| #### sources using another popular third-party service #### | |
| #### named Ably. Ably mimics pubsub Streaming concept, #### | |
| #### which might be extremely useful for any start-ups. #### | |
| #### #### | |
| ############################################################### | |
| from ably import AblyRest | |
| import logging | |
| import json | |
| from random import seed | |
| from random import random | |
| import json | |
| import math | |
| import random | |
| from clsConfig import clsConfig as cf | |
| seed(1) | |
| # Global Section | |
| logger = logging.getLogger('ably') | |
| logger.addHandler(logging.StreamHandler()) | |
| ably_id = str(cf.conf['ABLY_ID']) | |
| ably = AblyRest(ably_id) | |
| channel = ably.channels.get('sd_channel') | |
| # End Of Global Section | |
| class clsPublishStream: | |
| def __init__(self): | |
| self.msgSize = cf.conf['limRec'] | |
| def pushEvents(self, srcJSON, debugInd, varVa): | |
| try: | |
| msgSize = self.msgSize | |
| # Capturing the inbound dataframe | |
| jdata_fin = json.dumps(srcJSON) | |
| print('IOT Events: ') | |
| print(str(jdata_fin)) | |
| # Publish rest of the messages to the sd_channel channel | |
| channel.publish('event', jdata_fin) | |
| jdata_fin = '' | |
| return 0 | |
| except Exception as e: | |
| x = str(e) | |
| print(x) | |
| logging.info(x) | |
| return 1 |
We’re not going to discuss this as we’ve already discussed in my previous post.
3. clsStreamConsume.py (Consuming Streaming data from Ably channels.)
This file contains hidden or bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
| ############################################## | |
| #### Written By: SATYAKI DE #### | |
| #### Written On: 26-Jul-2021 #### | |
| #### Modified On 08-Sep-2021 #### | |
| #### #### | |
| #### Objective: Consuming Streaming data #### | |
| #### from Ably channels published by the #### | |
| #### playIOTDevice.py #### | |
| #### #### | |
| ############################################## | |
| import json | |
| from clsConfig import clsConfig as cf | |
| import requests | |
| import logging | |
| import time | |
| import pandas as p | |
| import clsL as cl | |
| from ably import AblyRest | |
| # Initiating Log class | |
| l = cl.clsL() | |
| class clsStreamConsume: | |
| def __init__(self): | |
| self.ably_id = str(cf.conf['ABLY_ID']) | |
| self.fileName = str(cf.conf['FinData']) | |
| def conStream(self, varVa, debugInd): | |
| try: | |
| ably_id = self.ably_id | |
| fileName = self.fileName | |
| var = varVa | |
| debug_ind = debugInd | |
| # Fetching the data | |
| client = AblyRest(ably_id) | |
| channel = client.channels.get('sd_channel') | |
| message_page = channel.history() | |
| # Counter Value | |
| cnt = 0 | |
| # Declaring Global Data-Frame | |
| df_conv = p.DataFrame() | |
| for i in message_page.items: | |
| print('Last Msg: {}'.format(i.data)) | |
| json_data = json.loads(i.data) | |
| #jdata = json.dumps(json_data) | |
| # Converting String to Dictionary | |
| dict_json = eval(json_data) | |
| # Converting JSON to Dataframe | |
| #df = p.json_normalize(json_data) | |
| #df.columns = df.columns.map(lambda x: x.split(".")[-1]) | |
| df = p.DataFrame.from_dict(dict_json, orient='index') | |
| #print('DF Inside:') | |
| #print(df) | |
| if cnt == 0: | |
| df_conv = df | |
| else: | |
| d_frames = [df_conv, df] | |
| df_conv = p.concat(d_frames) | |
| cnt += 1 | |
| # Resetting the Index Value | |
| df_conv.reset_index(drop=True, inplace=True) | |
| # This will check whether the current load is happening | |
| # or not. Based on that, it will capture the old events | |
| # from cache. | |
| if df_conv.empty: | |
| df_conv = p.read_csv(fileName, index = True) | |
| else: | |
| l.logr(fileName, debug_ind, df_conv, 'log') | |
| return df_conv | |
| except Exception as e: | |
| x = str(e) | |
| print('Error: ', x) | |
| logging.info(x) | |
| # This will handle the error scenaio as well. | |
| # Based on that, it will capture the old events | |
| # from cache. | |
| try: | |
| df_conv = p.read_csv(fileName, index = True) | |
| except: | |
| df = p.DataFrame() | |
| return df |
We’re not going to discuss this as we’ve already discussed in my previous post.
4. CircuitConfiguration.json (Configuration file for GUI Interface for IoT Simulator.)
This file contains hidden or bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
| { | |
| "name":"Analog Device", | |
| "width":700, | |
| "height":350, | |
| "leds":[ | |
| { | |
| "x":105, | |
| "y":80, | |
| "name":"LED", | |
| "pin":21 | |
| } | |
| ], | |
| "motors":[ | |
| { | |
| "x":316, | |
| "y":80, | |
| "name":"DC Motor", | |
| "forward_pin":22, | |
| "backward_pin":23 | |
| } | |
| ], | |
| "servos":[ | |
| { | |
| "x":537, | |
| "y":80, | |
| "name":"Servo Motor", | |
| "pin":24, | |
| "min_angle":-180, | |
| "max_angle":180, | |
| "initial_angle":20 | |
| } | |
| ], | |
| "adc":{ | |
| "mcp_chip":3008, | |
| "potenciometers":[ | |
| { | |
| "x":40, | |
| "y":200, | |
| "name":"Brightness Potentiometer", | |
| "channel":0 | |
| }, | |
| { | |
| "x":270, | |
| "y":200, | |
| "name":"Speed Potentiometer", | |
| "channel":2 | |
| }, | |
| { | |
| "x":500, | |
| "y":200, | |
| "name":"Angle Potentiometer", | |
| "channel":6 | |
| } | |
| ] | |
| }, | |
| "toggles":[ | |
| { | |
| "x":270, | |
| "y":270, | |
| "name":"Direction Toggle Switch", | |
| "pin":15, | |
| "off_label":"backward", | |
| "on_label":"forward", | |
| "is_on":false | |
| } | |
| ], | |
| "labels":[ | |
| { | |
| "x":15, | |
| "y":35, | |
| "width":25, | |
| "height":18, | |
| "borderwidth":2, | |
| "relief":"solid" | |
| }, | |
| { | |
| "x":56, | |
| "y":26, | |
| "text":"Brightness Control" | |
| }, | |
| { | |
| "x":245, | |
| "y":35, | |
| "width":25, | |
| "height":18, | |
| "borderwidth":2, | |
| "relief":"solid" | |
| }, | |
| { | |
| "x":298, | |
| "y":26, | |
| "text":"Speed Control" | |
| }, | |
| { | |
| "x":475, | |
| "y":35, | |
| "width":25, | |
| "height":18, | |
| "borderwidth":2, | |
| "relief":"solid" | |
| }, | |
| { | |
| "x":531, | |
| "y":26, | |
| "text":"Angle Control" | |
| } | |
| ] | |
| } |
This json configuration will be used by the next python class.
5. clsBuildCircuit.py (Calling Tk Circuit API.)
This file contains hidden or bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
| ############################################## | |
| #### Written By: SATYAKI DE #### | |
| #### Written On: 25-Sep-2021 #### | |
| #### Modified On 25-Sep-2021 #### | |
| #### #### | |
| #### Objective: Calling Tk Circuit API #### | |
| ############################################## | |
| from tkgpio import TkCircuit | |
| from json import load | |
| from clsConfig import clsConfig as cf | |
| fileName = str(cf.conf['JSONFileNameWithPath']) | |
| print('File Name: ', str(fileName)) | |
| # initialize the circuit inside the GUI | |
| with open(fileName, "r") as file: | |
| config = load(file) | |
| class clsBuildCircuit: | |
| def __init__(self): | |
| self.config = config | |
| def genCir(self, main_function): | |
| try: | |
| config = self.config | |
| circuit = TkCircuit(config) | |
| circuit.run(main_function) | |
| return circuit | |
| except Exception as e: | |
| x = str(e) | |
| print(x) | |
| return '' |
Key snippets from the above script –
config = self.config circuit = TkCircuit(config) circuit.run(main_function)
The above lines will create an instance of simulated IoT circuits & then it will use the json file to start the GUI class.
6. playIOTDevice.py (Main Circuit GUI script to create an IoT Device to generate the events, which will consumed.)
This file contains hidden or bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
| ############################################### | |
| #### Written By: SATYAKI DE #### | |
| #### Written On: 25-Sep-2021 #### | |
| #### Modified On 25-Sep-2021 #### | |
| #### #### | |
| #### Objective: Main Tk Circuit GUI script #### | |
| #### to create an IOT Device to generate #### | |
| #### the events, which will consumed. #### | |
| ############################################### | |
| # We keep the setup code in a different class as shown below. | |
| import clsBuildCircuit as csb | |
| import json | |
| import clsPublishStream as cps | |
| import datetime | |
| from clsConfig import clsConfig as cf | |
| import logging | |
| ############################################### | |
| ### Global Section ### | |
| ############################################### | |
| # Initiating Ably class to push events | |
| x1 = cps.clsPublishStream() | |
| # Create the instance of the Tk Circuit API Class. | |
| circuit = csb.clsBuildCircuit() | |
| ############################################### | |
| ### End of Global Section ### | |
| ############################################### | |
| # Invoking the IOT Device Generator. | |
| @circuit.genCir | |
| def main(): | |
| from gpiozero import PWMLED, Motor, Servo, MCP3008, Button | |
| from time import sleep | |
| # Circuit Components | |
| ledAlert = PWMLED(21) | |
| dcMotor = Motor(22, 23) | |
| servoMotor = Servo(24) | |
| ioMeter1 = MCP3008(0) | |
| ioMeter2 = MCP3008(2) | |
| ioMeter3 = MCP3008(6) | |
| switch = Button(15) | |
| # End of circuit components | |
| # Other useful variables | |
| cnt = 1 | |
| idx = 0 | |
| debugInd = 'Y' | |
| var = datetime.datetime.now().strftime("%Y-%m-%d_%H-%M-%S") | |
| # End of useful variables | |
| # Initiating Log Class | |
| general_log_path = str(cf.conf['LOG_PATH']) | |
| msgSize = int(cf.conf['limRec']) | |
| # Enabling Logging Info | |
| logging.basicConfig(filename=general_log_path + 'IOTDevice.log', level=logging.INFO) | |
| while True: | |
| ledAlert.value = ioMeter1.value | |
| if switch.is_pressed: | |
| dcMotor.forward(ioMeter2.value) | |
| xVal = 'Motor Forward' | |
| else: | |
| dcMotor.backward(ioMeter2.value) | |
| xVal = 'Motor Backward' | |
| servoMotor.value = 1 – 2 * ioMeter3.value | |
| srcJson = { | |
| "LedMeter": ledAlert.value, | |
| "DCMeter": ioMeter2.value, | |
| "ServoMeter": ioMeter3.value, | |
| "SwitchStatus": switch.is_pressed, | |
| "DCMotorPos": xVal, | |
| "ServoMotor": servoMotor.value | |
| } | |
| tmpJson = str(srcJson) | |
| if cnt == 1: | |
| srcJsonMast = '{' + '"' + str(idx) + '":'+ tmpJson | |
| elif cnt == msgSize: | |
| srcJsonMast = srcJsonMast + '}' | |
| print('JSON: ') | |
| print(str(srcJsonMast)) | |
| # Pushing both the Historical Confirmed Cases | |
| retVal_1 = x1.pushEvents(srcJsonMast, debugInd, var) | |
| if retVal_1 == 0: | |
| print('Successfully IOT event pushed!') | |
| else: | |
| print('Failed to push IOT events!') | |
| srcJsonMast = '' | |
| tmpJson = '' | |
| cnt = 0 | |
| idx = -1 | |
| srcJson = {} | |
| retVal_1 = 0 | |
| else: | |
| srcJsonMast = srcJsonMast + ',' + '"' + str(idx) + '":'+ tmpJson | |
| cnt += 1 | |
| idx += 1 | |
| sleep(0.05) |
Lets’ explore the key snippets –
ledAlert = PWMLED(21) dcMotor = Motor(22, 23) servoMotor = Servo(24)
It defines three motors that include Servo, DC & LED.
Now, we can see the following sets of the critical snippet –
ledAlert.value = ioMeter1.value
if switch.is_pressed:
dcMotor.forward(ioMeter2.value)
xVal = 'Motor Forward'
else:
dcMotor.backward(ioMeter2.value)
xVal = 'Motor Backward'
servoMotor.value = 1 - 2 * ioMeter3.value
srcJson = {
"LedMeter": ledAlert.value,
"DCMeter": ioMeter2.value,
"ServoMeter": ioMeter3.value,
"SwitchStatus": switch.is_pressed,
"DCMotorPos": xVal,
"ServoMotor": servoMotor.value
}
Following lines will dynamically generates JSON that will be passed into the Ably queue –
tmpJson = str(srcJson)
if cnt == 1:
srcJsonMast = '{' + '"' + str(idx) + '":'+ tmpJson
elif cnt == msgSize:
srcJsonMast = srcJsonMast + '}'
print('JSON: ')
print(str(srcJsonMast))
Final line from the above script –
# Pushing both the Historical Confirmed Cases retVal_1 = x1.pushEvents(srcJsonMast, debugInd, var)
This code will now push the events into the Ably Queue.
7. app.py (Consuming Streaming data from Ably channels & captured IOT events from the simulator & publish them in Dashboard through measured KPIs.)
This file contains hidden or bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
| ############################################## | |
| #### Updated By: SATYAKI DE #### | |
| #### Updated On: 02-Oct-2021 #### | |
| #### #### | |
| #### Objective: Consuming Streaming data #### | |
| #### from Ably channels & captured IOT #### | |
| #### events from the simulator & publish #### | |
| #### them in Dashboard through measured #### | |
| #### KPIs. #### | |
| #### #### | |
| ############################################## | |
| import os | |
| import pathlib | |
| import numpy as np | |
| import datetime as dt | |
| import dash | |
| from dash import dcc | |
| from dash import html | |
| import datetime | |
| import dash_daq as daq | |
| from dash.exceptions import PreventUpdate | |
| from dash.dependencies import Input, Output, State | |
| from scipy.stats import rayleigh | |
| # Consuming data from Ably Queue | |
| from ably import AblyRest | |
| # Main Class to consume streaming | |
| import clsStreamConsume as ca | |
| # Create the instance of the Covid API Class | |
| x1 = ca.clsStreamConsume() | |
| var1 = datetime.datetime.now().strftime("%Y-%m-%d_%H-%M-%S") | |
| print('*' *60) | |
| DInd = 'Y' | |
| GRAPH_INTERVAL = os.environ.get("GRAPH_INTERVAL", 5000) | |
| app = dash.Dash( | |
| __name__, | |
| meta_tags=[{"name": "viewport", "content": "width=device-width, initial-scale=1"}], | |
| ) | |
| app.title = "IOT Device Dashboard" | |
| server = app.server | |
| app_color = {"graph_bg": "#082255", "graph_line": "#007ACE"} | |
| app.layout = html.Div( | |
| [ | |
| # header | |
| html.Div( | |
| [ | |
| html.Div( | |
| [ | |
| html.H4("IOT DEVICE STREAMING", className="app__header__title"), | |
| html.P( | |
| "This app continually consumes streaming data from IOT-Device and displays live charts of various metrics & KPI associated with it.", | |
| className="app__header__title–grey", | |
| ), | |
| ], | |
| className="app__header__desc", | |
| ), | |
| html.Div( | |
| [ | |
| html.A( | |
| html.Button("SOURCE CODE", className="link-button"), | |
| href="https://github.com/SatyakiDe2019/IOTStream", | |
| ), | |
| html.A( | |
| html.Button("VIEW DEMO", className="link-button"), | |
| href="https://github.com/SatyakiDe2019/IOTStream/blob/main/demo.gif", | |
| ), | |
| html.A( | |
| html.Img( | |
| src=app.get_asset_url("dash-new-logo.png"), | |
| className="app__menu__img", | |
| ), | |
| href="https://plotly.com/dash/", | |
| ), | |
| ], | |
| className="app__header__logo", | |
| ), | |
| ], | |
| className="app__header", | |
| ), | |
| html.Div( | |
| [ | |
| # Motor Speed | |
| html.Div( | |
| [ | |
| html.Div( | |
| [html.H6("SERVO METER (IOT)", className="graph__title")] | |
| ), | |
| dcc.Graph( | |
| id="iot-measure", | |
| figure=dict( | |
| layout=dict( | |
| plot_bgcolor=app_color["graph_bg"], | |
| paper_bgcolor=app_color["graph_bg"], | |
| ) | |
| ), | |
| ), | |
| dcc.Interval( | |
| id="iot-measure-update", | |
| interval=int(GRAPH_INTERVAL), | |
| n_intervals=0, | |
| ), | |
| # Second Panel | |
| html.Div( | |
| [html.H6("DC-MOTOR (IOT)", className="graph__title")] | |
| ), | |
| dcc.Graph( | |
| id="iot-measure-1", | |
| figure=dict( | |
| layout=dict( | |
| plot_bgcolor=app_color["graph_bg"], | |
| paper_bgcolor=app_color["graph_bg"], | |
| ) | |
| ), | |
| ), | |
| dcc.Interval( | |
| id="iot-measure-update-1", | |
| interval=int(GRAPH_INTERVAL), | |
| n_intervals=0, | |
| ) | |
| ], | |
| className="two-thirds column motor__speed__container", | |
| ), | |
| html.Div( | |
| [ | |
| # histogram | |
| html.Div( | |
| [ | |
| html.Div( | |
| [ | |
| html.H6( | |
| "MOTOR POWER HISTOGRAM", | |
| className="graph__title", | |
| ) | |
| ] | |
| ), | |
| html.Div( | |
| [ | |
| dcc.Slider( | |
| id="bin-slider", | |
| min=1, | |
| max=60, | |
| step=1, | |
| value=20, | |
| updatemode="drag", | |
| marks={ | |
| 20: {"label": "20"}, | |
| 40: {"label": "40"}, | |
| 60: {"label": "60"}, | |
| }, | |
| ) | |
| ], | |
| className="slider", | |
| ), | |
| html.Div( | |
| [ | |
| dcc.Checklist( | |
| id="bin-auto", | |
| options=[ | |
| {"label": "Auto", "value": "Auto"} | |
| ], | |
| value=["Auto"], | |
| inputClassName="auto__checkbox", | |
| labelClassName="auto__label", | |
| ), | |
| html.P( | |
| "# of Bins: Auto", | |
| id="bin-size", | |
| className="auto__p", | |
| ), | |
| ], | |
| className="auto__container", | |
| ), | |
| dcc.Graph( | |
| id="motor-histogram", | |
| figure=dict( | |
| layout=dict( | |
| plot_bgcolor=app_color["graph_bg"], | |
| paper_bgcolor=app_color["graph_bg"], | |
| ) | |
| ), | |
| ), | |
| ], | |
| className="graph__container first", | |
| ), | |
| # motor direction | |
| html.Div( | |
| [ | |
| html.Div( | |
| [ | |
| html.H6( | |
| "SERVO MOTOR DIRECTION", className="graph__title" | |
| ) | |
| ] | |
| ), | |
| dcc.Graph( | |
| id="servo-motor-direction", | |
| figure=dict( | |
| layout=dict( | |
| plot_bgcolor=app_color["graph_bg"], | |
| paper_bgcolor=app_color["graph_bg"], | |
| ) | |
| ), | |
| ), | |
| ], | |
| className="graph__container second", | |
| ), | |
| ], | |
| className="one-third column histogram__direction", | |
| ), | |
| ], | |
| className="app__content", | |
| ), | |
| ], | |
| className="app__container", | |
| ) | |
| def toPositive(row, flag): | |
| try: | |
| if flag == 'ServoMeter': | |
| x_val = abs(float(row['ServoMotor'])) | |
| elif flag == 'DCMotor': | |
| x_val = abs(float(row['DCMotor'])) * 0.001 | |
| return x_val | |
| except Exception as e: | |
| x = str(e) | |
| print(x) | |
| val = 0 | |
| return val | |
| def toPositiveInflated(row, flag): | |
| try: | |
| if flag == 'ServoMeter': | |
| x_val = abs(float(row['ServoMeter'])) * 100 | |
| elif flag == 'DCMotor': | |
| x_val = abs(float(row['DCMeter'])) * 100 | |
| return x_val | |
| except Exception as e: | |
| x = str(e) | |
| print(x) | |
| val = 0 | |
| return val | |
| def getData(var, Ind): | |
| try: | |
| # Let's pass this to our map section | |
| df = x1.conStream(var, Ind) | |
| df['ServoMeterNew'] = df.apply(lambda row: toPositiveInflated(row, 'ServoMeter'), axis=1) | |
| df['ServoMotorNew'] = df.apply(lambda row: toPositive(row, 'ServoMeter'), axis=1) | |
| df['DCMotor'] = df.apply(lambda row: toPositiveInflated(row, 'DCMotor'), axis=1) | |
| df['DCMeterNew'] = df.apply(lambda row: toPositive(row, 'DCMotor'), axis=1) | |
| # Dropping old columns | |
| df.drop(columns=['ServoMeter','ServoMotor','DCMeter'], axis=1, inplace=True) | |
| #Rename New Columns to Old Columns | |
| df.rename(columns={'ServoMeterNew':'ServoMeter'}, inplace=True) | |
| df.rename(columns={'ServoMotorNew':'ServoMotor'}, inplace=True) | |
| df.rename(columns={'DCMeterNew':'DCMeter'}, inplace=True) | |
| return df | |
| except Exception as e: | |
| x = str(e) | |
| print(x) | |
| df = p.DataFrame() | |
| return df | |
| @app.callback( | |
| Output("iot-measure-1", "figure"), [Input("iot-measure-update", "n_intervals")] | |
| ) | |
| def gen_iot_speed(interval): | |
| """ | |
| Generate the DC Meter graph. | |
| :params interval: update the graph based on an interval | |
| """ | |
| # Let's pass this to our map section | |
| df = getData(var1, DInd) | |
| trace = dict( | |
| type="scatter", | |
| y=df["DCMotor"], | |
| line={"color": "#42C4F7"}, | |
| hoverinfo="skip", | |
| error_y={ | |
| "type": "data", | |
| "array": df["DCMeter"], | |
| "thickness": 1.5, | |
| "width": 2, | |
| "color": "#B4E8FC", | |
| }, | |
| mode="lines", | |
| ) | |
| layout = dict( | |
| plot_bgcolor=app_color["graph_bg"], | |
| paper_bgcolor=app_color["graph_bg"], | |
| font={"color": "#fff"}, | |
| height=400, | |
| xaxis={ | |
| "range": [0, 200], | |
| "showline": True, | |
| "zeroline": False, | |
| "fixedrange": True, | |
| "tickvals": [0, 50, 100, 150, 200], | |
| "ticktext": ["200", "150", "100", "50", "0"], | |
| "title": "Time Elapsed (sec)", | |
| }, | |
| yaxis={ | |
| "range": [ | |
| min(0, min(df["DCMotor"])), | |
| max(100, max(df["DCMotor"]) + max(df["DCMeter"])), | |
| ], | |
| "showgrid": True, | |
| "showline": True, | |
| "fixedrange": True, | |
| "zeroline": False, | |
| "gridcolor": app_color["graph_line"], | |
| "nticks": max(6, round(df["DCMotor"].iloc[-1] / 10)), | |
| }, | |
| ) | |
| return dict(data=[trace], layout=layout) | |
| @app.callback( | |
| Output("iot-measure", "figure"), [Input("iot-measure-update", "n_intervals")] | |
| ) | |
| def gen_iot_speed(interval): | |
| """ | |
| Generate the Motor Speed graph. | |
| :params interval: update the graph based on an interval | |
| """ | |
| # Let's pass this to our map section | |
| df = getData(var1, DInd) | |
| trace = dict( | |
| type="scatter", | |
| y=df["ServoMeter"], | |
| line={"color": "#42C4F7"}, | |
| hoverinfo="skip", | |
| error_y={ | |
| "type": "data", | |
| "array": df["ServoMotor"], | |
| "thickness": 1.5, | |
| "width": 2, | |
| "color": "#B4E8FC", | |
| }, | |
| mode="lines", | |
| ) | |
| layout = dict( | |
| plot_bgcolor=app_color["graph_bg"], | |
| paper_bgcolor=app_color["graph_bg"], | |
| font={"color": "#fff"}, | |
| height=400, | |
| xaxis={ | |
| "range": [0, 200], | |
| "showline": True, | |
| "zeroline": False, | |
| "fixedrange": True, | |
| "tickvals": [0, 50, 100, 150, 200], | |
| "ticktext": ["200", "150", "100", "50", "0"], | |
| "title": "Time Elapsed (sec)", | |
| }, | |
| yaxis={ | |
| "range": [ | |
| min(0, min(df["ServoMeter"])), | |
| max(100, max(df["ServoMeter"]) + max(df["ServoMotor"])), | |
| ], | |
| "showgrid": True, | |
| "showline": True, | |
| "fixedrange": True, | |
| "zeroline": False, | |
| "gridcolor": app_color["graph_line"], | |
| "nticks": max(6, round(df["ServoMeter"].iloc[-1] / 10)), | |
| }, | |
| ) | |
| return dict(data=[trace], layout=layout) | |
| @app.callback( | |
| Output("servo-motor-direction", "figure"), [Input("iot-measure-update", "n_intervals")] | |
| ) | |
| def gen_motor_direction(interval): | |
| """ | |
| Generate the Servo direction graph. | |
| :params interval: update the graph based on an interval | |
| """ | |
| df = getData(var1, DInd) | |
| val = df["ServoMeter"].iloc[-1] | |
| direction = [0, (df["ServoMeter"][0]*100 – 20), (df["ServoMeter"][0]*100 + 20), 0] | |
| traces_scatterpolar = [ | |
| {"r": [0, val, val, 0], "fillcolor": "#084E8A"}, | |
| {"r": [0, val * 0.65, val * 0.65, 0], "fillcolor": "#B4E1FA"}, | |
| {"r": [0, val * 0.3, val * 0.3, 0], "fillcolor": "#EBF5FA"}, | |
| ] | |
| data = [ | |
| dict( | |
| type="scatterpolar", | |
| r=traces["r"], | |
| theta=direction, | |
| mode="lines", | |
| fill="toself", | |
| fillcolor=traces["fillcolor"], | |
| line={"color": "rgba(32, 32, 32, .6)", "width": 1}, | |
| ) | |
| for traces in traces_scatterpolar | |
| ] | |
| layout = dict( | |
| height=350, | |
| plot_bgcolor=app_color["graph_bg"], | |
| paper_bgcolor=app_color["graph_bg"], | |
| font={"color": "#fff"}, | |
| autosize=False, | |
| polar={ | |
| "bgcolor": app_color["graph_line"], | |
| "radialaxis": {"range": [0, 45], "angle": 45, "dtick": 10}, | |
| "angularaxis": {"showline": False, "tickcolor": "white"}, | |
| }, | |
| showlegend=False, | |
| ) | |
| return dict(data=data, layout=layout) | |
| @app.callback( | |
| Output("motor-histogram", "figure"), | |
| [Input("iot-measure-update", "n_intervals")], | |
| [ | |
| State("iot-measure", "figure"), | |
| State("bin-slider", "value"), | |
| State("bin-auto", "value"), | |
| ], | |
| ) | |
| def gen_motor_histogram(interval, iot_speed_figure, slider_value, auto_state): | |
| """ | |
| Genererate iot histogram graph. | |
| :params interval: upadte the graph based on an interval | |
| :params iot_speed_figure: current Motor Speed graph | |
| :params slider_value: current slider value | |
| :params auto_state: current auto state | |
| """ | |
| motor_val = [] | |
| try: | |
| print('Inside gen_motor_histogram:') | |
| print('iot_speed_figure::') | |
| print(iot_speed_figure) | |
| # Check to see whether iot-measure has been plotted yet | |
| if iot_speed_figure is not None: | |
| motor_val = iot_speed_figure["data"][0]["y"] | |
| if "Auto" in auto_state: | |
| bin_val = np.histogram( | |
| motor_val, | |
| bins=range(int(round(min(motor_val))), int(round(max(motor_val)))), | |
| ) | |
| else: | |
| bin_val = np.histogram(motor_val, bins=slider_value) | |
| except Exception as error: | |
| raise PreventUpdate | |
| avg_val = float(sum(motor_val)) / len(motor_val) | |
| median_val = np.median(motor_val) | |
| pdf_fitted = rayleigh.pdf( | |
| bin_val[1], loc=(avg_val) * 0.55, scale=(bin_val[1][-1] – bin_val[1][0]) / 3 | |
| ) | |
| y_val = (pdf_fitted * max(bin_val[0]) * 20,) | |
| y_val_max = max(y_val[0]) | |
| bin_val_max = max(bin_val[0]) | |
| trace = dict( | |
| type="bar", | |
| x=bin_val[1], | |
| y=bin_val[0], | |
| marker={"color": app_color["graph_line"]}, | |
| showlegend=False, | |
| hoverinfo="x+y", | |
| ) | |
| traces_scatter = [ | |
| {"line_dash": "dash", "line_color": "#2E5266", "name": "Average"}, | |
| {"line_dash": "dot", "line_color": "#BD9391", "name": "Median"}, | |
| ] | |
| scatter_data = [ | |
| dict( | |
| type="scatter", | |
| x=[bin_val[int(len(bin_val) / 2)]], | |
| y=[0], | |
| mode="lines", | |
| line={"dash": traces["line_dash"], "color": traces["line_color"]}, | |
| marker={"opacity": 0}, | |
| visible=True, | |
| name=traces["name"], | |
| ) | |
| for traces in traces_scatter | |
| ] | |
| trace3 = dict( | |
| type="scatter", | |
| mode="lines", | |
| line={"color": "#42C4F7"}, | |
| y=y_val[0], | |
| x=bin_val[1][: len(bin_val[1])], | |
| name="Rayleigh Fit", | |
| ) | |
| layout = dict( | |
| height=350, | |
| plot_bgcolor=app_color["graph_bg"], | |
| paper_bgcolor=app_color["graph_bg"], | |
| font={"color": "#fff"}, | |
| xaxis={ | |
| "title": "Motor Power", | |
| "showgrid": False, | |
| "showline": False, | |
| "fixedrange": True, | |
| }, | |
| yaxis={ | |
| "showgrid": False, | |
| "showline": False, | |
| "zeroline": False, | |
| "title": "Number of Samples", | |
| "fixedrange": True, | |
| }, | |
| autosize=True, | |
| bargap=0.01, | |
| bargroupgap=0, | |
| hovermode="closest", | |
| legend={ | |
| "orientation": "h", | |
| "yanchor": "bottom", | |
| "xanchor": "center", | |
| "y": 1, | |
| "x": 0.5, | |
| }, | |
| shapes=[ | |
| { | |
| "xref": "x", | |
| "yref": "y", | |
| "y1": int(max(bin_val_max, y_val_max)) + 0.5, | |
| "y0": 0, | |
| "x0": avg_val, | |
| "x1": avg_val, | |
| "type": "line", | |
| "line": {"dash": "dash", "color": "#2E5266", "width": 5}, | |
| }, | |
| { | |
| "xref": "x", | |
| "yref": "y", | |
| "y1": int(max(bin_val_max, y_val_max)) + 0.5, | |
| "y0": 0, | |
| "x0": median_val, | |
| "x1": median_val, | |
| "type": "line", | |
| "line": {"dash": "dot", "color": "#BD9391", "width": 5}, | |
| }, | |
| ], | |
| ) | |
| return dict(data=[trace, scatter_data[0], scatter_data[1], trace3], layout=layout) | |
| @app.callback( | |
| Output("bin-auto", "value"), | |
| [Input("bin-slider", "value")], | |
| [State("iot-measure", "figure")], | |
| ) | |
| def deselect_auto(slider_value, iot_speed_figure): | |
| """ Toggle the auto checkbox. """ | |
| # prevent update if graph has no data | |
| if "data" not in iot_speed_figure: | |
| raise PreventUpdate | |
| if not len(iot_speed_figure["data"]): | |
| raise PreventUpdate | |
| if iot_speed_figure is not None and len(iot_speed_figure["data"][0]["y"]) > 5: | |
| return [""] | |
| return ["Auto"] | |
| @app.callback( | |
| Output("bin-size", "children"), | |
| [Input("bin-auto", "value")], | |
| [State("bin-slider", "value")], | |
| ) | |
| def show_num_bins(autoValue, slider_value): | |
| """ Display the number of bins. """ | |
| if "Auto" in autoValue: | |
| return "# of Bins: Auto" | |
| return "# of Bins: " + str(int(slider_value)) | |
| if __name__ == "__main__": | |
| app.run_server(debug=True) |
Here are the key snippets –
html.Div(
[
html.Div(
[html.H6("SERVO METER (IOT)", className="graph__title")]
),
dcc.Graph(
id="iot-measure",
figure=dict(
layout=dict(
plot_bgcolor=app_color["graph_bg"],
paper_bgcolor=app_color["graph_bg"],
)
),
),
dcc.Interval(
id="iot-measure-update",
interval=int(GRAPH_INTERVAL),
n_intervals=0,
),
# Second Panel
html.Div(
[html.H6("DC-MOTOR (IOT)", className="graph__title")]
),
dcc.Graph(
id="iot-measure-1",
figure=dict(
layout=dict(
plot_bgcolor=app_color["graph_bg"],
paper_bgcolor=app_color["graph_bg"],
)
),
),
dcc.Interval(
id="iot-measure-update-1",
interval=int(GRAPH_INTERVAL),
n_intervals=0,
)
],
className="two-thirds column motor__speed__container",
The following line creates two panels, where the application will consume the streaming data by the app’s call-back feature & refresh the data & graphs as & when the application receives the streaming data.
A similar approach was adopted for other vital aspects/components inside the dashboard.
def getData(var, Ind):
try:
# Let's pass this to our map section
df = x1.conStream(var, Ind)
df['ServoMeterNew'] = df.apply(lambda row: toPositiveInflated(row, 'ServoMeter'), axis=1)
df['ServoMotorNew'] = df.apply(lambda row: toPositive(row, 'ServoMeter'), axis=1)
df['DCMotor'] = df.apply(lambda row: toPositiveInflated(row, 'DCMotor'), axis=1)
df['DCMeterNew'] = df.apply(lambda row: toPositive(row, 'DCMotor'), axis=1)
# Dropping old columns
df.drop(columns=['ServoMeter','ServoMotor','DCMeter'], axis=1, inplace=True)
#Rename New Columns to Old Columns
df.rename(columns={'ServoMeterNew':'ServoMeter'}, inplace=True)
df.rename(columns={'ServoMotorNew':'ServoMotor'}, inplace=True)
df.rename(columns={'DCMeterNew':'DCMeter'}, inplace=True)
return df
except Exception as e:
x = str(e)
print(x)
df = p.DataFrame()
return df
The application is extracting streaming data & consuming it from the Ably queue.
@app.callback(
Output("iot-measure", "figure"), [Input("iot-measure-update", "n_intervals")]
)
def gen_iot_speed(interval):
"""
Generate the Motor Speed graph.
:params interval: update the graph based on an interval
"""
# Let's pass this to our map section
df = getData(var1, DInd)
trace = dict(
type="scatter",
y=df["ServoMeter"],
line={"color": "#42C4F7"},
hoverinfo="skip",
error_y={
"type": "data",
"array": df["ServoMotor"],
"thickness": 1.5,
"width": 2,
"color": "#B4E8FC",
},
mode="lines",
)
layout = dict(
plot_bgcolor=app_color["graph_bg"],
paper_bgcolor=app_color["graph_bg"],
font={"color": "#fff"},
height=400,
xaxis={
"range": [0, 200],
"showline": True,
"zeroline": False,
"fixedrange": True,
"tickvals": [0, 50, 100, 150, 200],
"ticktext": ["200", "150", "100", "50", "0"],
"title": "Time Elapsed (sec)",
},
yaxis={
"range": [
min(0, min(df["ServoMeter"])),
max(100, max(df["ServoMeter"]) + max(df["ServoMotor"])),
],
"showgrid": True,
"showline": True,
"fixedrange": True,
"zeroline": False,
"gridcolor": app_color["graph_line"],
"nticks": max(6, round(df["ServoMeter"].iloc[-1] / 10)),
},
)
return dict(data=[trace], layout=layout)
Capturing all the relevant columns & transform them into a graph, where the application will consume data into both the axis (x-axis & y-axis).
There are many other useful snippets, which creates separate useful widgets inside the dashboard.
Run:
Let us run the application –
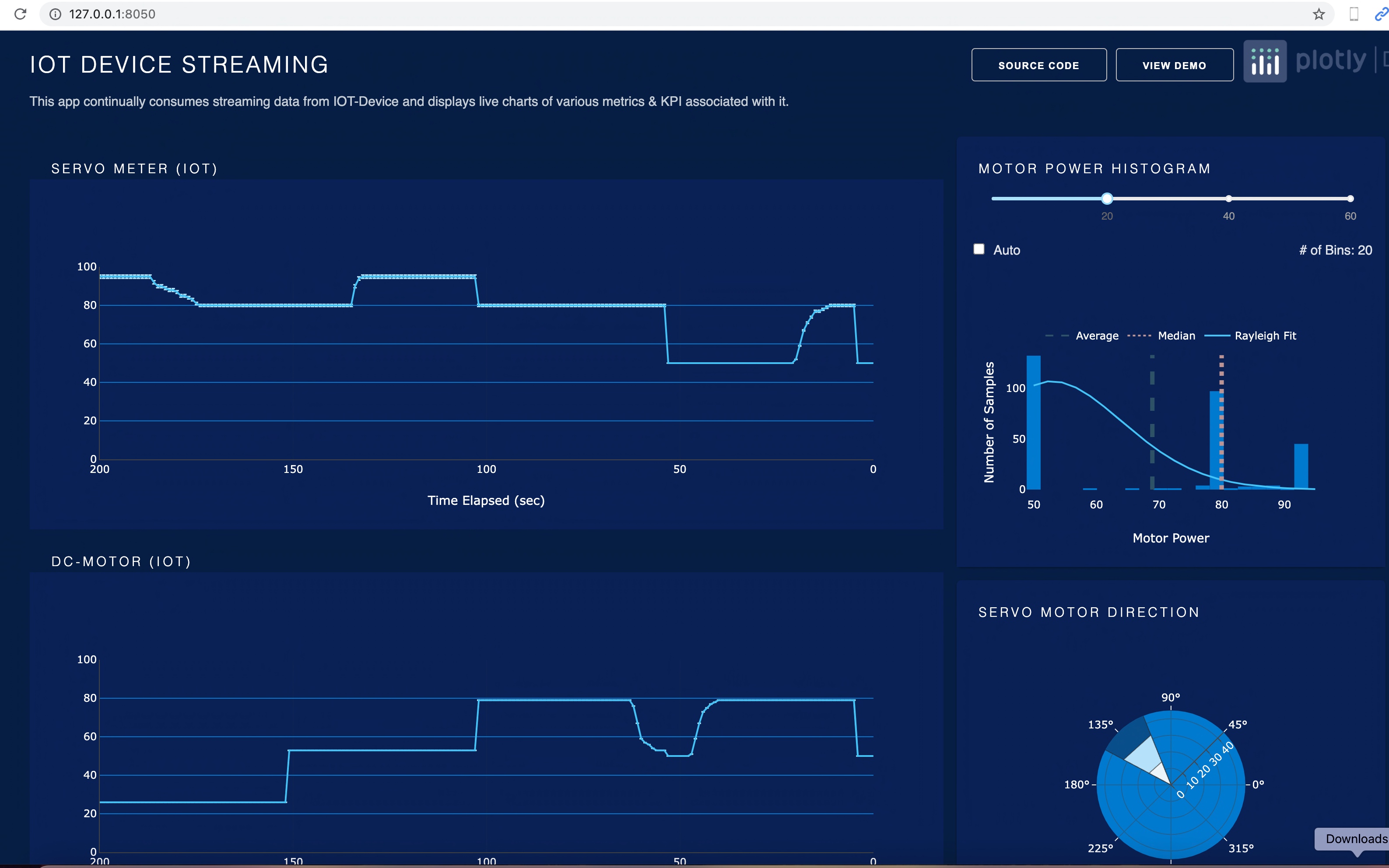
So, we’ve done it.
You will get the complete codebase in the following Github link.
There is an excellent resource from the dash framework, which you should explore. The following link would be handy for developers who want to get some meaningful pre-built dashboard template, which you can customize as per your need through Python or R. Please find the link here.
I’ll bring some more exciting topic in the coming days from the Python verse.
Till then, Happy Avenging! 😀
Note: All the data & scenario posted here are representational data & scenarios & available over the internet & for educational purpose only.
One more thing you need to understand is that this prediction based on limited data points. The actual event may happen differently. Ideally, countries are taking a cue from this kind of analysis & are initiating appropriate measures to avoid the high-curve. And, that is one of the main objective of time series analysis.
There is always a room for improvement of this kind of models & the solution associated with it. I’ve shown the basic ways to achieve the same for the education purpose only.
















































































































{kind=link}
You must be logged in to post a comment.