This site mainly deals with various use cases demonstrated using Python, Data Science, Cloud basics, SQL Server, Oracle, Teradata along with SQL & their implementation. Expecting yours active participation & time. This blog can be access from your TP, Tablet & mobile also. Please provide your feedback.
This is a continuation of my previous post, which can be found here. This will be our last post of this series.
Let us recap the key takaways from our previous post –
Two cloud patterns show how MCP standardizes safe AI-to-system work. Azure “agent factory”: You ask in Teams; Azure AI Foundry dispatches a specialist agent (HR/Sales). The agent calls a specific MCP server (Functions/Logic Apps) for CRM, SharePoint, or SQL via API Management. Entra ID enforces access; Azure Monitor audits. AWS “composable serverless agents”: In Bedrock, domain agents (Financial/IT Ops) invoke Lambda-based MCP tools for DynamoDB, S3, or CloudWatch through API Gateway with IAM and optional VPC. In both, agents never hold credentials; tools map one-to-one to systems, improving security, clarity, scalability, and compliance.
In this post, we’ll discuss the GCP factory pattern.
Unified Workbench Pattern (GCP):
The GCP “unified workbench” pattern prioritizes a unified, data-centric platform for AI development, integrating seamlessly with Vertex AI and Google’s expertise in AI and data analytics. This approach is well-suited for AI-first companies and data-intensive organizations that want to build agents that leverage cutting-edge research tools.
Let’s explore the following diagram based on this –
Imagine Mia, a clinical operations lead, opens a simple app and asks: “Which clinics had the longest wait times this week? Give me a quick summary I can share.”
The app quietly sends Mia’s request to Vertex AI Agent Builder—think of it as the switchboard operator.
Vertex AI picks the Data Analysis agent (the “specialist” for questions like Mia’s).
That agent doesn’t go rummaging through databases. Instead, it uses a safe, preapproved tool—an MCP Server—to query BigQuery, where the data lives.
The tool fetches results and returns them to Mia—no passwords in the open, no risky shortcuts—just the answer, fast and safely.
Now meet Ravi, a developer who asks: “Show me the latest app metrics and confirm yesterday’s patch didn’t break the login table.”
The app routes Ravi’s request to Vertex AI.
Vertex AI chooses the Developer agent.
That agent calls a different tool—an MCP Server designed for Cloud SQL—to check the login table and run a safe query.
Results come back with guardrails intact. If the agent ever needs files, there’s also a Cloud Storage tool ready to fetch or store documents.
Let us understand how the underlying flow of activities took place –
User Interface:
Entry point: Vertex AI console or a custom app.
Sends a single request; no direct credentials or system access exposed to the user.
Orchestration: Vertex AI Agent Builder (MCP Host)
Routes the request to the most suitable agent:
Agent A (Data Analysis) for analytics/BI-style questions.
Agent B (Developer) for application/data-ops tasks.
Tooling via MCP Servers on Cloud Run
Each MCP Server is a purpose-built adapter with least-privilege access to exactly one service:
Server1 → BigQuery (analytics/warehouse) — used by Agent A in this diagram.
Server2 → Cloud Storage (GCS) (files/objects) — available when file I/O is needed.
Server3 → Cloud SQL (relational DB) — used by Agent B in this diagram.
Agents never hold database credentials; they request actions from the right tool.
Enterprise Systems
BigQuery, Cloud Storage, and Cloud SQL are the systems of record that the tools interact with.
Security, Networking, and Observability
GCP IAM: AuthN/AuthZ for Vertex AI and each MCP Server (fine-grained roles, least privilege).
GCP VPC: Private network paths for all Cloud Run MCP Servers (isolation, egress control).
Cloud Monitoring: Metrics, logs, and alerts across agents and tools (auditability, SLOs).
Return Path
Results flow back from the service → MCP Server → Agent → Vertex AI → UI.
Policies and logs track who requested what, when, and how.
Why does this design work?
One entry point for questions.
Clear accountability: specialists (agents) act within guardrails.
Built-in safety (IAM/VPC) and visibility (Monitoring) for trust.
Separation of concerns: agents decide what to do; tools (MCP Servers) decide how to do it.
Scalable: add a new tool (e.g., Pub/Sub or Vertex AI Feature Store) without changing the UI or agents.
Auditable & maintainable: each tool maps to one service with explicit IAM and VPC controls.
So, we’ve concluded the series with the above post. I hope you like it.
I’ll bring some more exciting topics in the coming days from the new advanced world of technology.
Till then, Happy Avenging! 🙂
Note: All the data & scenarios posted here are representative of data & scenarios available on the internet for educational purposes only. There is always room for improvement in this kind of model & the solution associated with it. I’ve shown the basic ways to achieve the same for educational purposes only.
This is a continuation of my previous post, which can be found here.
Let us recap the key takaways from our previous post –
The Model Context Protocol (MCP) standardizes how AI agents use tools and data. Instead of fragile, custom connectors (N×M problem), teams build one MCP server per system; any MCP-compatible agent can use it, reducing cost and breakage. Unlike RAG, which retrieves static, unstructured documents for context, MCP enables live, structured, and actionable operations (e.g., query databases, create tickets). Compared with proprietary plugins, MCP is open, model-agnostic (JSON-RPC 2.0), and minimizes vendor lock-in. Cloud patterns: Azure “agent factory,” AWS “serverless agents,” and GCP “unified workbench”—each hosting agents with MCP servers securely fronting enterprise services.
Today, we’ll try to understand some of the popular pattern from the world of cloud & we’ll explore them in this post & the next post.
Agent Factory Pattern (Azure):
The Azure “agent factory” pattern leverages the Azure AI Foundry to serve as a secure, managed hub for creating and orchestrating multiple specialized AI agents. This pattern emphasizes enterprise-grade security, governance, and seamless integration with the Microsoft ecosystem, making it ideal for organizations that use Microsoft products extensively.
Let’s explore the following diagram based on this –
Imagine you ask a question in Microsoft Teams—“Show me the latest HR policy” or “What is our current sales pipeline?” Your message is sent to Azure AI Foundry, which acts as an expert dispatcher. Foundry chooses a specialist AI agent—for example, an HR agent for policies or a Sales agent for the pipeline.
That agent does not rummage through your systems directly. Instead, it uses a safe, preapproved tool (an “MCP Server”) that knows how to talk to one system—such as Dynamics 365/CRM, SharePoint, or an Azure SQL database. The tool gets the information, sends it back to the agent, who then explains the answer clearly to you in Teams.
Throughout the process, three guardrails keep everything safe and reliable:
Microsoft Entra ID checks identity and permissions.
Azure API Management (APIM) is the controlled front door for all tool calls.
Azure Monitor watches performance and creates an audit trail.
Let us now understand the technical events that is going on underlying this request –
Control plane: Azure AI Foundry (MCP Host) orchestrates intent, tool selection, and multi-agent flows.
Execution plane: Agents invoke MCP Servers (Azure Functions/Logic Apps) via APIM; each server encapsulates a single domain integration (CRM, SharePoint, SQL).
Data plane:
MCP Server (CRM) ↔ Dynamics 365/CRM
MCP Server (SharePoint) ↔ SharePoint
MCP Server (SQL) ↔ Azure SQL Database
Identity & access:Entra ID issues tokens and enforces least-privilege access; Foundry, APIM, and MCP Servers validate tokens.
Observability:Azure Monitor for metrics, logs, distributed traces, and auditability across agents and tool calls.
Traffic pattern in diagram:
User → Foundry → Agent (Sales/HR).
Agent —tool call→ MCP Server (CRM/SharePoint/SQL).
MCP Server → Target system; response returns along the same path.
Note: The SQL MCP Server is shown connected to Azure SQL; agents can call it in the same fashion as CRM/SharePoint when a use case requires relational data.
Why does this design work?
Safety by design: Agents never directly touch back-end systems; MCP Servers mediate access with APIM and Entra ID.
Clarity & maintainability: Each tool maps to one system; changes are localized and testable.
Scalability: Add new agents or systems by introducing another MCP Server behind APIM.
Auditability: Every action is observable in Azure Monitor for compliance and troubleshooting.
AWS MCP Architecture:
The AWS “composable serverless agent” pattern focuses on building lightweight, modular, and event-driven AI agents using Bedrock and serverless technologies. It prioritizes customization, scalability, and leveraging AWS’s deep service portfolio, making it a strong choice for enterprises that value flexibility and granular control.
A manager opens a familiar app (the Bedrock console or a simple web app) and types, “Show me last quarter’s approved purchase requests.” The request goes to Amazon Bedrock Agents, which acts like an intelligent dispatcher. It chooses the Financial Agent—a specialist in finance tasks. That agent uses a safe, pre-approved tool to fetch data from the company’s DynamoDB records. Moments later, the manager sees a clear summary, without ever touching databases or credentials.
Actors & guardrails. UI (Bedrock console or custom app) → Amazon Bedrock Agents (MCP host/orchestrator) → Domain Agents (Financial, IT Ops) → MCP Servers on AWS Lambda (one tool per AWS service) → Enterprise Services (DynamoDB, S3, CloudWatch). Access is governed by IAM (least-privilege roles, agent→tool→service), ingress/policy by API Gateway (front door to each Lambda tool), and network isolation by VPC where required.
Agent–tool mappings:
Agent A (Financial) → Lambda MCP (DynamoDB)
Agent B (IT Ops) → Lambda MCP (CloudWatch)
Optional: Lambda MCP (S3) for file/object operations
End-to-end sequence:
UI → Bedrock Agents: User submits a prompt.
Agent selection: Bedrock dispatches to the appropriate domain agent (Financial or IT Ops).
Tool invocation: The agent calls the required Lambda MCP Server via API Gateway.
Authorization: The tool executes only permitted actions under its IAM role (least privilege).
Safer by default: Agents never handle raw credentials; tools enforce least privilege with IAM.
Clear boundaries: Each tool maps to one service, making audits and changes simpler.
Scalable & maintainable:Lambda and API Gateway scale on demand; adding a new tool (e.g., a Cost Explorer tool) does not require changing the UI or existing agents.
Faster delivery: Specialists (agents) focus on logic; tools handle system specifics.
In the next post, we’ll conclude the final thread on this topic.
Till then, Happy Avenging! 🙂
Note: All the data & scenarios posted here are representational data & scenarios & available over the internet & for educational purposes only. There is always room for improvement in this kind of model & the solution associated with it. I’ve shown the basic ways to achieve the same for educational purposes only.
This is a continuation of my previous post, which can be found here.
Let us recap the key takaways from our previous post –
Enterprise AI, utilizing the Model Context Protocol (MCP), leverages an open standard that enables AI systems to securely and consistently access enterprise data and tools. MCP replaces brittle “N×M” integrations between models and systems with a standardized client–server pattern: an MCP host (e.g., IDE or chatbot) runs an MCP client that communicates with lightweight MCP servers, which wrap external systems via JSON-RPC. Servers expose three assets—Resources (data), Tools (actions), and Prompts (templates)—behind permissions, access control, and auditability. This design enables real-time context, reduces hallucinations, supports model- and cloud-agnostic interoperability, and accelerates “build once, integrate everywhere” deployment. A typical flow (e.g., retrieving a customer’s latest order) encompasses intent parsing, authorized tool invocation, query translation/execution, and the return of a normalized JSON result to the model for natural-language delivery. Performance introduces modest overhead (RPC hops, JSON (de)serialization, network transit) and scale considerations (request volume, significant results, context-window pressure). Mitigations include in-memory/semantic caching, optimized SQL with indexing, pagination, and filtering, connection pooling, and horizontal scaling with load balancing. In practice, small latency costs are often outweighed by the benefits of higher accuracy, stronger governance, and a decoupled, scalable architecture.
How does MCP compare with other AI integration approaches?
Compared to other approaches, the Model Context Protocol (MCP) offers a uniquely standardized and secure framework for AI-tool integration, shifting from brittle, custom-coded connections to a universal plug-and-play model. It is not a replacement for underlying systems, such as APIs or databases, but instead acts as an intelligent, secure abstraction layer designed explicitly for AI agents.
MCP vs. Custom API integrations:
This approach was the traditional method for AI integration before standards like MCP emerged.
Custom API integrations (traditional): Each AI application requires a custom-built connector for every external system it needs to access, leading to an N x M integration problem (the number of connectors grows exponentially with the number of models and systems). This approach is resource-intensive, challenging to maintain, and prone to breaking when underlying APIs change.
MCP: The standardized protocol eliminates the N x M problem by creating a universal interface. Tool creators build a single MCP server for their system, and any MCP-compatible AI agent can instantly access it. This process decouples the AI model from the underlying implementation details, drastically reducing integration and maintenance costs.
For more detailed information, please refer to the following link.
MCP vs. Retrieval-Augmented Generation (RAG):
RAG is a technique that retrieves static documents to augment an LLM’s knowledge, while MCP focuses on live interactions. They are complementary, not competing.
RAG:
Focus: Retrieving and summarizing static, unstructured data, such as documents, manuals, or knowledge bases.
Best for: Providing background knowledge and general information, as in a policy lookup tool or customer service bot.
Data type: Unstructured, static knowledge.
MCP:
Focus: Accessing and acting on real-time, structured, and dynamic data from databases, APIs, and business systems.
Best for: Agentic use cases involving real-world actions, like pulling live sales reports from a CRM or creating a ticket in a project management tool.
Data type: Structured, real-time, and dynamic data.
MCP vs. LLM plugins and extensions:
Before MCP, platforms like OpenAI offered proprietary plugin systems to extend LLM capabilities.
LLM plugins:
Proprietary: Tied to a specific AI vendor (e.g., OpenAI).
Limited: Rely on the vendor’s API function-calling mechanism, which focuses on call formatting but not standardized execution.
Centralized: Managed by the AI vendor, creating a risk of vendor lock-in.
MCP:
Open standard: Based on a public, interoperable protocol (JSON-RPC 2.0), making it model-agnostic and usable across different platforms.
Infrastructure layer: Provides a standardized infrastructure for agents to discover and use any compliant tool, regardless of the underlying LLM.
Decentralized: Promotes a flexible ecosystem and reduces the risk of vendor lock-in.
How enterprise AI with MCP has opened up a specific Architecture pattern for Azure, AWS & GCP?
Microsoft Azure:
The “agent factory” pattern: Azure focuses on providing managed services for building and orchestrating AI agents, tightly integrated with its enterprise security and governance features. The MCP architecture is a core component of the Azure AI Foundry, serving as a secure, managed “agent factory.”
Azure architecture pattern with MCP:
AI orchestration layer: The Azure AI Agent Service, within Azure AI Foundry, acts as the central host and orchestrator. It provides the control plane for creating, deploying, and managing multiple specialized agents, and it natively supports the MCP standard.
AI model layer: Agents in the Foundry can be powered by various models, including those from Azure OpenAI Service, commercial models from partners, or open-source models.
MCP server and tool layer: MCP servers are deployed using serverless functions, such as Azure Functions or Azure Logic Apps, to wrap existing enterprise systems. These servers expose tools for interacting with enterprise data sources like SharePoint, Azure AI Search, and Azure Blob Storage.
Data and security layer: Data is secured using Microsoft Entra ID (formerly Azure AD) for authentication and access control, with robust security policies enforced via Azure API Management. Access to data sources, such as databases and storage, is managed securely through private networks and Managed Identity.
Amazon Web Services (AWS):
The “composable serverless agent” pattern: AWS emphasizes a modular, composable, and serverless approach, leveraging its extensive portfolio of services to build sophisticated, flexible, and scalable AI solutions. The MCP architecture here aligns with the principle of creating lightweight, event-driven services that AI agents can orchestrate.
AWS architecture pattern with MCP:
The AI orchestration layer, which includesAmazon Bedrock Agents or custom agent frameworks deployed via AWS Fargate or Lambda, acts as the MCP hosts. Bedrock Agents provide built-in orchestration, while custom agents offer greater flexibility and customization options.
AI model layer: The models are sourced from Amazon Bedrock, which provides a wide selection of foundation models.
MCP server and tool layer: MCP servers are deployed as serverless AWS Lambda functions. AWS offers pre-built MCP servers for many of its services, including the AWS Serverless MCP Server for managing serverless applications and the AWS Lambda Tool MCP Server for invoking existing Lambda functions as tools.
Data and security layer: Access is tightly controlled using AWS Identity and Access Management (IAM) roles and policies, with fine-grained permissions for each MCP server. Private data sources like databases (Amazon DynamoDB) and storage (Amazon S3) are accessed securely within a Virtual Private Cloud (VPC).
Google Cloud Platform (GCP):
The “unified workbench” pattern: GCP focuses on providing a unified, open, and data-centric platform for AI development. The MCP architecture on GCP integrates natively with the Vertex AI platform, treating MCP servers as first-class tools that can be dynamically discovered and used within a single workbench.
GCP architecture pattern with MCP:
AI orchestration layer: The Vertex AI Agent Builder serves as the central environment for building and managing conversational AI and other agents. It orchestrates workflows and manages tool invocation for agents.
AI model layer: Agents use foundation models available through the Vertex AI Model Garden or the Gemini API.
MCP server and tool layer: MCP servers are deployed as containerized microservices on Cloud Run or managed by services like App Engine. These servers contain tools that interact with GCP services, such as BigQuery, Cloud Storage, and Cloud SQL. GCP offers pre-built MCP server implementations, such as the GCP MCP Toolbox, for integration with its databases.
Data and security layer:Vertex AI Vector Search and other data sources are encapsulated within the MCP server tools to provide contextual information. Access to these services is managed by Identity and Access Management (IAM) and secured through virtual private clouds. The MCP server can leverage Vertex AI Context Caching for improved performance.
Note that all the native technology is referred to in each respective cloud. Hence, some of the better technologies can be used in place of the tool mentioned here. This is more of a concept-level comparison rather than industry-wise implementation approaches.
We’ll go ahead and conclude this post here & continue discussing on a further deep dive in the next post.
Till then, Happy Avenging! 🙂
Note: All the data & scenarios posted here are representational data & scenarios & available over the internet & for educational purposes only. There is always room for improvement in this kind of model & the solution associated with it. I’ve shown the basic ways to achieve the same for educational purposes only.
This is a continuation of my previous post, which can be found here.
Let us recap the key takaways from our previous post –
Agentic AI refers to autonomous systems that pursue goals with minimal supervision by planning, reasoning about next steps, utilizing tools, and maintaining context across sessions. Core capabilities include goal-directed autonomy, interaction with tools and environments (e.g., APIs, databases, devices), multi-step planning and reasoning under uncertainty, persistence, and choiceful decision-making.
Architecturally, three modules coordinate intelligent behavior: Sensing (perception pipelines that acquire multimodal data, extract salient patterns, and recognize entities/events); Observation/Deliberation (objective setting, strategy formation, and option evaluation relative to resources and constraints); and Action (execution via software interfaces, communications, or physical actuation to deliver outcomes). These functions are enabled by machine learning, deep learning, computer vision, natural language processing, planning/decision-making, uncertainty reasoning, and simulation/modeling.
At enterprise scale, open standards align autonomy with governance: the Model Context Protocol (MCP) grants an agent secure, principled access to enterprise tools and data (vertical integration), while Agent-to-Agent (A2A) enables specialized agents to coordinate, delegate, and exchange information (horizontal collaboration). Together, MCP and A2A help organizations transition from isolated pilots to scalable programs, delivering end-to-end automation, faster integration, enhanced security and auditability, vendor-neutral interoperability, and adaptive problem-solving that responds to real-time context.
Great! Let’s dive into this topic now.
Enterprise AI with MCP refers to the application of the Model Context Protocol (MCP), an open standard, to enable AI systems to securely and consistently access external enterprise data and applications.
The problem MCP solves in enterprise AI:
Before MCP, enterprise AI integration was characterized by a “many-to-many” or “N x M” problem. Companies had to build custom, fragile, and costly integrations between each AI model and every proprietary data source, which was not scalable. These limitations left AI agents with limited, outdated, or siloed information, restricting their potential impact. MCP addresses this by offering a standardized architecture for AI and data systems to communicate with each other.
How does MCP work?
The MCP framework uses a client-server architecture to enable communication between AI models and external tools and data sources.
MCP Host: The AI-powered application or environment, such as an AI-enhanced IDE or a generative AI chatbot like Anthropic’s Claude or OpenAI’s ChatGPT, where the user interacts.
MCP Client: A component within the host application that manages the connection to MCP servers.
MCP Server: A lightweight service that wraps around an external system (e.g., a CRM, database, or API) and exposes its capabilities to the AI client in a standardized format, typically using JSON-RPC 2.0.
An MCP server provides AI clients with three key resources:
Resources: Structured or unstructured data that an AI can access, such as files, documents, or database records.
Tools: The functionality to perform specific actions within an external system, like running a database query or sending an email.
Prompts: Pre-defined text templates or workflows to help guide the AI’s actions.
Benefits of MCP for enterprise AI:
Standardized integration: Developers can build integrations against a single, open standard, which dramatically reduces the complexity and time required to deploy and scale AI initiatives.
Enhanced security and governance: MCP incorporates native support for security and compliance measures. It provides permission models, access control, and auditing capabilities to ensure AI systems only access data and tools within specified boundaries.
Real-time contextual awareness: By connecting AI agents to live enterprise data sources, MCP ensures they have access to the most current and relevant information, which reduces hallucinations and improves the accuracy of AI outputs.
Greater interoperability: MCP is model-agnostic & can be used with a variety of AI models (e.g., Anthropic’s Claude or OpenAI’s models) and across different cloud environments. This approach helps enterprises avoid vendor lock-in.
Accelerated development: The “build once, integrate everywhere” approach enables internal teams to focus on innovation instead of writing custom connectors for every system.
Flow of activities:
Let us understand one sample case & the flow of activities.
A customer support agent uses an AI assistant to get information about a customer’s recent orders. The AI assistant utilizes an MCP-compliant client to communicate with an MCP server, which is connected to the company’s PostgreSQL database.
The interaction flow:
1. User request: The support agent asks the AI assistant, “What was the most recent order placed by Priyanka Chopra Jonas?”
2. AI model processes intent: The AI assistant, running on an MCP host, analyzes the natural language query. It recognizes that to answer this question, it needs to perform a database query. It then identifies the appropriate tool from the MCP server’s capabilities.
3. Client initiates tool call: The AI assistant’s MCP client sends a JSON-RPC request to the MCP server connected to the PostgreSQL database. The request specifies the tool to be used, such as get_customer_orders, and includes the necessary parameters:
5. Database returns data: The PostgreSQL database executes the query and returns the requested data to the MCP server.
6. Server formats the response: The MCP server receives the raw database output and formats it into a standardized JSON response that the MCP client can understand.
7. Client returns data to the model: The MCP client receives the JSON response and passes it back to the AI assistant’s language model.
8. AI model generates final response: The language model incorporates this real-time data into its response and presents it to the user in a natural, conversational format.
“Priyanka Chopra Jonas’s most recent order was placed on August 25, 2025, with an order ID of 98765, for a total of $11025.50.”
What are the performance implications of using MCP for database access?
Using the Model Context Protocol (MCP) for database access introduces a layer of abstraction that affects performance in several ways. While it adds some latency and processing overhead, strategic implementation can mitigate these effects. For AI applications, the benefits often outweigh the costs, particularly in terms of improved accuracy, security, and scalability.
Sources of performance implications::
Added latency and processing overhead:
The MCP architecture introduces extra communication steps between the AI agent and the database, each adding a small amount of latency.
RPC overhead: The JSON-RPC call from the AI’s client to the MCP server adds a small processing and network delay. This is an out-of-process request, as opposed to a simple local function call.
JSON serialization: Request and response data must be serialized and deserialized into JSON format, which requires processing time.
Network transit: For remote MCP servers, the data must travel over the network, adding latency. However, for a local or on-premise setup, this is minimal. The physical location of the MCP server relative to the AI model and the database is a significant factor.
Scalability and resource consumption:
The performance impact scales with the complexity and volume of the AI agent’s interactions.
High request volume: A single AI agent working on a complex task might issue dozens of parallel database queries. In high-traffic scenarios, managing numerous simultaneous connections can strain system resources and require robust infrastructure.
Excessive data retrieval: A significant performance risk is an AI agent retrieving a massive dataset in a single query. This process can consume a large number of tokens, fill the AI’s context window, and cause bottlenecks at the database and client levels.
Context window usage: Tool definitions and the results of tool calls consume space in the AI’s context window. If a large number of tools are in use, this can limit the AI’s “working memory,” resulting in slower and less effective reasoning.
Optimizations for high performance::
Caching:
Caching is a crucial strategy for mitigating the performance overhead of MCP.
In-memory caching: The MCP server can cache results from frequent or expensive database queries in memory (e.g., using Redis or Memcached). This approach enables repeat requests to be served almost instantly without requiring a database hit.
Semantic caching: Advanced techniques can cache the results of previous queries and serve them for semantically similar future requests, reducing token consumption and improving speed for conversational applications.
Efficient queries and resource management:
Designing the MCP server and its database interactions for efficiency is critical.
Optimized SQL: The MCP server should generate optimized SQL queries. Database indexes should be utilized effectively to expedite lookups and minimize load.
Pagination and filtering: To prevent a single query from overwhelming the system, the MCP server should implement pagination. The AI agent can be prompted to use filtering parameters to retrieve only the necessary data.
Connection pooling: This technique reuses existing database connections instead of opening a new one for each request, thereby reducing latency and database load.
Load balancing and scaling:
For large-scale enterprise deployments, scaling is essential for maintaining performance.
Multiple servers: The workload can be distributed across various MCP servers. One server could handle read requests, and another could handle writes.
Load balancing: A reverse proxy or other load-balancing solution can distribute incoming traffic across MCP server instances. Autoscaling can dynamically add or remove servers in response to demand.
The performance trade-off in perspective:
For AI-driven tasks, a slight increase in latency for database access is often a worthwhile trade-off for significant gains.
Improved accuracy: Accessing real-time, high-quality data through MCP leads to more accurate and relevant AI responses, reducing “hallucinations”.
Scalable ecosystem: The standardization of MCP reduces development overhead and allows for a more modular, scalable ecosystem, which saves significant engineering resources compared to building custom integrations.
Decoupled architecture: The MCP server decouples the AI model from the database, allowing each to be optimized and scaled independently.
We’ll go ahead and conclude this post here & continue discussing on a further deep dive in the next post.
Till then, Happy Avenging! 🙂
Note: All the data & scenarios posted here are representational data & scenarios & available over the internet & for educational purposes only. There is always room for improvement in this kind of model & the solution associated with it. I’ve shown the basic ways to achieve the same for educational purposes only.
Today, I’m going to discuss another Computer Vision installment. I’ll use Open CV & Kalman filter to predict a live ball movement of Cricket, one of the most popular sports in the Indian sub-continent, along with the UK & Australia. But before we start a deep dive, why don’t we first watch the demo?
Demo
Isn’t it exciting? Let’s explore it in detail.
Architecture:
Let us understand the flow of events –
The above diagram shows that the application, which uses Open CV, analyzes individual frames. It detects the cricket ball & finally, it tracks every movement by analyzing each frame & then it predicts (pink line) based on the supplied data points.
Python Packages:
Following are the python packages that are necessary to develop this brilliant use case –
Let us now understand the code. For this use case, we will only discuss three python scripts. However, we need more than these three. However, we have already discussed them in some of the early posts. Hence, we will skip them here.
clsPredictBodyLine.py (The main class that will handle the prediction of Cricket balls in the real-time video feed.)
This file contains hidden or bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters. Learn more about bidirectional Unicode characters
Please find the key snippet from the above script –
kf = clsKalmanFilter()
The application is instantiating the modified Kalman filter.
myColorFinder = ColorFinder(False)
This command has more purpose than creating a proper mask in debug mode if you want to isolate the color of any object you want to track. To debug this property, one needs to set the flag to True. And you will see the following screen. Click the next video to get the process to generate the accurate HSV.
In the end, you will get a similar entry to the below one –
And you can see the entry that is available in the config for the following parameter –
The four points mentioned above will help us determine the best region for the ball, forcing the batsman to play the shots & a 90% chance of getting caught behind.
The snippets below will apply the mask & identify the contour of the objects which the program intends to track. In this case, we are talking about the pink cricket ball.
#Find the color ball
imgColor, mask = myColorFinder.update(img, hsvVals)
#Find location of the red_ball
imgContours, contours = cvzone.findContours(img, mask, minArea=500)
if contours:
posListX.append(contours[0]['center'][0])
posListY.append(contours[0]['center'][1])
The next key snippets are as follows –
if posListX:
# Find the Coefficients
A, B, C = np.polyfit(posListX, posListY, 2)
for i, (posX, posY) in enumerate(zip(posListX, posListY)):
pos = (posX, posY)
cv2.circle(imgContours, pos, 10, (0,255,0), cv2.FILLED)
# Using Karman Filter Prediction
predicted = kf.predict(posX, posY)
cv2.circle(imgContours, (predicted[0], predicted[1]), 12, (255,0,255), cv2.FILLED)
ballDetectFlag = True
if ballDetectFlag:
print('Balls Detected!')
if i == 0:
cv2.line(imgContours, pos, pos, (0,255,0), 5)
cv2.line(imgContours, predicted, predicted, (255,0,255), 5)
else:
predictedM = kf.predict(posListX[i-1], posListY[i-1])
cv2.line(imgContours, pos, (posListX[i-1], posListY[i-1]), (0,255,0), 5)
cv2.line(imgContours, predicted, predictedM, (255,0,255), 5)
The above lines will track the original & predicted lines & then it will plot on top of the frame in real time.
The next line will be as follows –
if len(posListX) < 10:
# Calculation for best place to ball
a1 = A
b1 = B
c1 = C - pT1
X1 = int((- b1 - math.sqrt(b1**2 - (4*a1*c1)))/(2*a1))
prediction1 = pT2 < X1 < pT3
a2 = A
b2 = B
c2 = C - pT4
X2 = int((- b2 - math.sqrt(b2**2 - (4*a2*c2)))/(2*a2))
prediction2 = pT2 < X2 < pT3
prediction = prediction1 | prediction2
if prediction:
print('Good Length Ball!')
sMsg = "Good Length Ball - (" + str(FrNo) + ")"
cvzone.putTextRect(imgContours, sMsg, (50,150), scale=5, thickness=5, colorR=(0,200,0), offset=20)
else:
print('Loose Ball!')
sMsg = "Loose Ball - (" + str(FrNo) + ")"
cvzone.putTextRect(imgContours, sMsg, (50,150), scale=5, thickness=5, colorR=(0,0,200), offset=20)
predictBodyLine.py (The main python script that will invoke the class to predict Cricket balls in the real-time video feed.)
This file contains hidden or bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters. Learn more about bidirectional Unicode characters
# Passing source data csv file
x1 = pbdl.clsPredictBodyLine()
# Execute all the pass
r1 = x1.processVideo(debugInd, var)
if (r1 == 0):
print('Successfully predicted body-line deliveries!')
else:
print('Failed to predict body-line deliveries!')
The above lines will first instantiate the main class & then invoke it.
You can find it here if you want to know more about the Kalman filter.
So, finally, we’ve done it.
FOLDER STRUCTURE:
You will get the complete codebase in the following GitHub link.
I’ll bring some more exciting topics in the coming days from the Python verse. Please share & subscribe to my post & let me know your feedback.
Till then, Happy Avenging! 🙂
Note: All the data & scenarios posted here are representational data & scenarios & available over the internet & for educational purposes only. Some of the images (except my photo) we’ve used are available over the net. We don’t claim ownership of these images. There is always room for improvement & especially in the prediction quality.
This week we’re going to extend one of our earlier posts & trying to read an entire text from streaming using computer vision. If you want to view the previous post, please click the following link.
But, before we proceed, why don’t we view the demo first?
Demo
Architecture:
Let us understand the architecture flow –
Architecture flow
The above diagram shows that the application, which uses the Open-CV, analyzes individual frames from the source & extracts the complete text within the video & displays it on top of the target screen besides prints the same in the console.
Let us now understand the code. For this use case, we will only discuss three python scripts. However, we need more than these three. However, we have already discussed them in some of the early posts. Hence, we will skip them here.
clsReadingTextFromStream.py (This is the main class of python script that will extract the text from the WebCAM streaming in real-time.)
This file contains hidden or bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters. Learn more about bidirectional Unicode characters
Please find the key snippet from the above script –
# Two output layer names for the text detector model
lNames = cf.conf['LAYER_DET']
# Tesseract OCR text param values
strVal = "-l " + str(cf.conf['LANG']) + " --oem " + str(cf.conf['OEM_VAL']) + " --psm " + str(cf.conf['PSM_VAL']) + ""
config = (strVal)
The first line contains the two output layers’ names for the text detector model. Among them, the first one indicates the outcome possibilities & the second one use to derive the bounding box coordinates of the predicted text.
The second line contains various options for the tesseract APIs. You need to understand the opportunities in detail to make them work. These are the essential options for our use case –
Language – The intended language, for example, English, Spanish, Hindi, Bengali, etc.
OEM flag – In this case, the application will use 4 to indicate LSTM neural net model for OCR.
OEM Value – In this case, the selected value is 7, indicating that the application treats the ROI as a single line of text.
For more details, please refer to the config file.
print("[INFO] Loading Text Detector...")
net = cv2.dnn.readNet(modelPath)
The above lines bring the already created model & load it to memory for evaluation.
# Setting new width and height and then determine the ratio in change
# for both the width and height
(newW, newH) = (wt, ht)
rW = origW / float(newW)
rH = origH / float(newH)
# Resize the frame and grab the new frame dimensions
frame = cv2.resize(frame, (newW, newH))
(H, W) = frame.shape[:2]
# Construct a blob from the frame and then perform a forward pass of
# the model to obtain the two output layer sets
blob = cv2.dnn.blobFromImage(frame, 1.0, (W, H), sParam, swapRB=True, crop=False)
net.setInput(blob)
(confScore, imgGeo) = net.forward(lNames)
# Decode the predictions, then apply non-maxima suppression to
# suppress weak, overlapping bounding boxes
(rects, confidences) = self.predictText(confScore, imgGeo)
boxes = non_max_suppression(np.array(rects), probs=confidences)
The above lines are more of preparing individual frames to get the bounding box by resizing the height & width followed by a forward pass of the model to obtain two output layer sets. And then apply the non-maxima suppression to remove the weak, overlapping bounding box by interpreting the prediction. In short, this will identify the potential text region & put the bounding box surrounding it.
# Initialize the list of results
res = []
# Getting BoundingBox boundaries
res = self.findBoundBox(boxes, res, rW, rH, orig, origW, origH, pad)
The above function will create the bounding box surrounding the predicted text regions. Also, we will capture the expected text inside the result variable.
for (spX, spY, epX, epY) in boxes:
# Scale the bounding box coordinates based on the respective
# ratios
spX = int(spX * rW)
spY = int(spY * rH)
epX = int(epX * rW)
epY = int(epY * rH)
# To obtain a better OCR of the text we can potentially
# apply a bit of padding surrounding the bounding box.
# And, computing the deltas in both the x and y directions
dX = int((epX - spX) * pad)
dY = int((epY - spY) * pad)
# Apply padding to each side of the bounding box, respectively
spX = max(0, spX - dX)
spY = max(0, spY - dY)
epX = min(origW, epX + (dX * 2))
epY = min(origH, epY + (dY * 2))
# Extract the actual padded ROI
roi = orig[spY:epY, spX:epX]
Now, the application will scale the bounding boxes based on the previously computed ratio for actual text recognition. In this process, the application also padded the bounding boxes & then extracted the padded region of interest.
# Choose the proper OCR Config
text = pytesseract.image_to_string(roi, config=config)
# Add the bounding box coordinates and OCR'd text to the list
# of results
res.append(((spX, spY, epX, epY), text))
Using OCR options, the application extracts the text within the video frame & adds that to the res list.
# Sort the results bounding box coordinates from top to bottom
res = sorted(res, key=lambda r:r[0][1])
It then sends a sorted output to the primary calling functions.
for ((spX, spY, epX, epY), text) in res:
# Display the text OCR by using Tesseract APIs
print("Reading Text::")
print("=" *60)
print(text)
print("=" *60)
# Removing the non-ASCII text so it can draw the text on the frame
# using OpenCV, then draw the text and a bounding box surrounding
# the text region of the input frame
text = "".join([c if ord(c) < aRange else "" for c in text]).strip()
output = orig.copy()
cv2.rectangle(output, (spX, spY), (epX, epY), drawTag, 2)
cv2.putText(output, text, (spX, spY - 20), cv2.FONT_HERSHEY_SIMPLEX, 1.2, drawTag, 3)
# Show the output frame
cv2.imshow(title, output)
Finally, it fetches the potential text region along with the text & then prints on top of the source video. Also, it removed some non-printable characters during this time to avoid any cryptic texts.
readingVideo.py (Main calling script.)
This file contains hidden or bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters. Learn more about bidirectional Unicode characters
# Instantiating all the main class
x1 = rtfs.clsReadingTextFromStream()
# Execute all the pass
r1 = x1.processStream(debugInd, var)
if (r1 == 0):
print('Successfully read text from the Live Stream!')
else:
print('Failed to read text from the Live Stream!')
The above lines instantiate the main calling class & then invoke the function to get the desired extracted text from the live streaming video if that is successful.
FOLDER STRUCTURE:
Here is the folder structure that contains all the files & directories in MAC O/S –
You will get the complete codebase in the following Github link.
Unfortunately, I cannot upload the model due to it’s size. I will share on the need basis.
I’ll bring some more exciting topic in the coming days from the Python verse. Please share & subscribe my post & let me know your feedback.
Till then, Happy Avenging! 🙂
Note: All the data & scenario posted here are representational data & scenarios & available over the internet & for educational purpose only. Some of the images (except my photo) that we’ve used are available over the net. We don’t claim the ownership of these images. There is an always room for improvement & especially the prediction quality.
Today, I’m going to discuss another Computer Vision installment. I’ll discuss how to implement Augmented Reality using Open-CV Computer Vision with full audio. We will be using part of a Bengali OTT Series called “Feludar Goendagiri” entirely for educational purposes & also as a tribute to the great legendary director, late Satyajit Roy. To know more about him, please click the following link.
Why don’t we see the demo first before jumping into the technical details?
Demo
Architecture:
Let us understand the architecture –
Process Flow
The above diagram shows that the application, which uses the Open-CV, analyzes individual frames from the source & blends that with the video trailer. Finally, it creates another video by correctly mixing the source audio.
Python Packages:
Following are the python packages that are necessary to develop this brilliant use case –
pip install opencv-python
pip install pygame
CODE:
Let us now understand the code. For this use case, we will only discuss three python scripts. However, we need more than these three. However, we have already discussed them in some of the early posts. Hence, we will skip them here.
clsAugmentedReality.py (This is the main class of python script that will embed the source video with the WebCAM streams in real-time.)
This file contains hidden or bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters. Learn more about bidirectional Unicode characters
Identifying the Aruco markers are key here. The above lines help the program detect all four corners.
However, let us discuss more on the Aruco markers & strategies that I’ve used for several different surfaces.
Aruco Markers
As you can see, the right-hand side Aruco marker is tiny compared to the left one. Hence, that one will be ideal for a curve surface like Coffee Mug, Bottle rather than a flat surface.
Also, we’ve demonstrated the zoom capability with the smaller Aruco marker that will Augment almost double the original surface area.
Let us understand why we need that; as you know, any spherical surface like a bottle is round-shaped. Hence, detecting relatively more significant Aruco markers in four corners will be difficult for any camera to identify.
Hence, we need a process where close four corners can be extrapolated mathematically to relatively larger projected areas easily detectable by any WebCAM.
Let’s observe the following figure –
Simulated Extrapolated corners
As you can see that the original position of the four corners is represented using the following points, i.e., (x1, y1), (x2, y2), (x3, y3) & (x4, y4).
And these positions are very close to each other. Hence, it will be easier for the camera to detect all the points (like a plain surface) without many retries.
And later, you can add specific values of x & y to them to get the derived four corners as shown in the above figures through the following points, i.e. (x1.1, y1.1), (x2.1, y2.1), (x3.1, y3.1) & (x4.1, y4.1).
# Loop over the IDs of the ArUco markers in Top-Left, Top-Right,
# Bottom-Right, and Bottom-Left order
for i in cornerIDs:
# Grab the index of the corner with the current ID
j = np.squeeze(np.where(ids == i))
# If we receive an empty list instead of an integer index,
# then we could not find the marker with the current ID
if j.size == 0:
continue
# Otherwise, append the corner (x, y)-coordinates to our list
# of reference points
corner = np.squeeze(corners[j])
refPts.append(corner)
# Check to see if we failed to find the four ArUco markers
if len(refPts) != 4:
# If we are allowed to use cached reference points, fall
# back on them
if useCache and CACHED_REF_PTS is not None:
refPts = CACHED_REF_PTS
# Otherwise, we cannot use the cache and/or there are no
# previous cached reference points, so return early
else:
return None
# If we are allowed to use cached reference points, then update
# the cache with the current set
if useCache:
CACHED_REF_PTS = refPts
# Unpack our Aruco reference points and use the reference points
# to define the Destination transform matrix, making sure the
# points are specified in Top-Left, Top-Right, Bottom-Right, and
# Bottom-Left order
(refPtTL, refPtTR, refPtBR, refPtBL) = refPts
dstMat = [refPtTL[0], refPtTR[1], refPtBR[2], refPtBL[3]]
dstMat = np.array(dstMat)
In the above snippet, the application will scan through all the points & try to detect Aruco markers & then create a list of reference points, which will later be used to define the destination transformation matrix.
The above snippets calculate the revised points for the zoom-out capabilities as discussed in one of the earlier figures.
# Define the transform matrix for the *source* image in Top-Left,
# Top-Right, Bottom-Right, and Bottom-Left order
srcMat = np.array([[0, 0], [srcW, 0], [srcW, srcH], [0, srcH]])
The above snippet will create a transformation matrix for the video trailer.
# Compute the homography matrix and then warp the source image to
# the destination based on the homography depending upon the
# zoom flag
if zoomFlag == 1:
(H, _) = cv2.findHomography(srcMat, dstMat)
else:
(H, _) = cv2.findHomography(srcMat, dstMatMod)
warped = cv2.warpPerspective(source, H, (imgW, imgH))
# Construct a mask for the source image now that the perspective
# warp has taken place (we'll need this mask to copy the source
# image into the destination)
mask = np.zeros((imgH, imgW), dtype="uint8")
if zoomFlag == 1:
cv2.fillConvexPoly(mask, dstMat.astype("int32"), (255, 255, 255), cv2.LINE_AA)
else:
cv2.fillConvexPoly(mask, dstMatMod.astype("int32"), (255, 255, 255), cv2.LINE_AA)
# This optional step will give the source image a black
# border surrounding it when applied to the source image, you
# can apply a dilation operation
rect = cv2.getStructuringElement(cv2.MORPH_RECT, (3, 3))
mask = cv2.dilate(mask, rect, iterations=2)
# Create a three channel version of the mask by stacking it
# depth-wise, such that we can copy the warped source image
# into the input image
maskScaled = mask.copy() / 255.0
maskScaled = np.dstack([maskScaled] * 3)
# Copy the warped source image into the input image by
# (1) Multiplying the warped image and masked together,
# (2) Then multiplying the original input image with the
# mask (giving more weight to the input where there
# are not masked pixels), and
# (3) Adding the resulting multiplications together
warpedMultiplied = cv2.multiply(warped.astype("float"), maskScaled)
imageMultiplied = cv2.multiply(frame.astype(float), 1.0 - maskScaled)
output = cv2.add(warpedMultiplied, imageMultiplied)
output = output.astype("uint8")
Finally, depending upon the zoom flag, the application will create a warped image surrounded by an optionally black border.
clsEmbedVideoWithStream.py (This is the main class of python script that will invoke the clsAugmentedReality class to initiate augment reality after splitting the audio & video & then project them via the Web-CAM with a seamless broadcast.)
This file contains hidden or bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters. Learn more about bidirectional Unicode characters
Please find the key snippet from the above script –
def playAudio(self, audioFile, audioLen, freq, stopFlag=False):
try:
pygame.mixer.init()
pygame.init()
pygame.mixer.music.load(audioFile)
pygame.mixer.music.set_volume(10)
val = int(audioLen)
i = 0
while i < val:
pygame.mixer.music.play(loops=0, start=float(i))
time.sleep(freq)
i = i + 1
if (i >= val):
raise BreakLoop
if (stopFlag==True):
raise BreakLoop
return 0
except BreakLoop as s:
return 0
except Exception as e:
x = str(e)
print(x)
return 1
The above function will initiate the pygame library to run the sound of the video file that has been extracted as part of a separate process.
def extractAudio(self, video_file, output_ext="mp3"):
try:
"""Converts video to audio directly using `ffmpeg` command
with the help of subprocess module"""
filename, ext = os.path.splitext(video_file)
subprocess.call(["ffmpeg", "-y", "-i", video_file, f"{filename}.{output_ext}"],
stdout=subprocess.DEVNULL,
stderr=subprocess.STDOUT)
return 0
except Exception as e:
x = str(e)
print('Error: ', x)
return 1
The above function temporarily extracts the audio file from the source trailer video.
# Initialize the video file stream
print("[INFO] accessing video stream...")
vf = cv2.VideoCapture(videoFile)
x = self.extractAudio(videoFile)
if x == 0:
print('Successfully Audio extracted from the source file!')
else:
print('Failed to extract the source audio!')
# Initialize a queue to maintain the next frame from the video stream
Q = deque(maxlen=128)
# We need to have a frame in our queue to start our augmented reality
# pipeline, so read the next frame from our video file source and add
# it to our queue
(grabbed, source) = vf.read()
Q.appendleft(source)
# Initialize the video stream and allow the camera sensor to warm up
print("[INFO] starting video stream...")
vs = VideoStream(src=0).start()
time.sleep(2.0)
flg = 0
The above snippets read the frames from the video file after invoking the audio extraction. Then, it uses a Queue method to store all the video frames for better performance. And finally, it starts consuming the standard streaming video from the WebCAM to augment the trailer video on top of it.
t = threading.Thread(target=self.playAudio, args=(audioFile, audioLen, audioFreq, stopFlag,))
t.daemon = True
Now, the application has instantiated an orphan thread to spin off the audio play function. The reason is to void the performance & video frame frequency impact on top of it.
while len(Q) > 0:
try:
# Grab the frame from our video stream and resize it
frame = vs.read()
frame = imutils.resize(frame, width=1020)
# Attempt to find the ArUCo markers in the frame, and provided
# they are found, take the current source image and warp it onto
# input frame using our augmented reality technique
warped = x1.getWarpImages(
frame, source,
cornerIDs=(923, 1001, 241, 1007),
arucoDict=arucoDict,
arucoParams=arucoParams,
zoomFlag=zFlag,
useCache=CacheL > 0)
# If the warped frame is not None, then we know (1) we found the
# four ArUCo markers and (2) the perspective warp was successfully
# applied
if warped is not None:
# Set the frame to the output augment reality frame and then
# grab the next video file frame from our queue
frame = warped
source = Q.popleft()
if flg == 0:
t.start()
flg = flg + 1
# For speed/efficiency, we can use a queue to keep the next video
# frame queue ready for us -- the trick is to ensure the queue is
# always (or nearly full)
if len(Q) != Q.maxlen:
# Read the next frame from the video file stream
(grabbed, nextFrame) = vf.read()
# If the frame was read (meaning we are not at the end of the
# video file stream), add the frame to our queue
if grabbed:
Q.append(nextFrame)
# Show the output frame
cv2.imshow(title, frame)
time.sleep(videoFrame)
# If the `q` key was pressed, break from the loop
if cv2.waitKey(2) & 0xFF == ord('q'):
stopFlag = True
break
except BreakLoop:
raise BreakLoop
except Exception as e:
pass
if (len(Q) == Q.maxlen):
time.sleep(2)
break
The final segment will call the getWarpImages function to get the Augmented image on top of the video. It also checks for the upcoming frames & whether the source video is finished or not. In case of the end, the application will initiate a break method to come out from the infinite WebCAM read. Also, there is a provision for manual exit by pressing the ‘Q’ from the MacBook keyboard.
# Performing cleanup at the end
cv2.destroyAllWindows()
vs.stop()
It is always advisable to close your camera & remove any temporarily available windows that are still left once the application finishes the process.
augmentedMovieTrailer.py (Main calling script)
This file contains hidden or bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters. Learn more about bidirectional Unicode characters
The above script will initially instantiate the main calling class & then invoke the processStream function to create the Augmented Reality.
FOLDER STRUCTURE:
Here is the folder structure that contains all the files & directories in MAC O/S –
Directory Structure
You will get the complete codebase in the following Github link.
If you want to know more about this legendary director & his famous work, please visit the following link.
I’ll bring some more exciting topic in the coming days from the Python verse. Please share & subscribe my post & let me know your feedback.
Till then, Happy Avenging! 🙂
Note: All the data & scenario posted here are representational data & scenarios & available over the internet & for educational purpose only. Some of the images (except my photo) that we’ve used are available over the net. We don’t claim the ownership of these images. There is an always room for improvement & especially the prediction quality.
This week we’re planning to touch on one of the exciting posts of visually reading characters from WebCAM & predict the letters using CNN methods. Before we dig deep, why don’t we see the demo run first?
Demo
Isn’t it fascinating? As we can see, the computer can record events and read like humans. And, thanks to the brilliant packages available in Python, which can help us predict the correct letter out of an Image.
What do we need to test it out?
Preferably an external WebCAM.
A moderate or good Laptop to test out this.
Python
And a few other packages that we’ll mention next block.
What Python packages do we need?
Some of the critical packages that we must need to test out this application are –
In deep learning, a convolutional neural network (CNN/ConvNet) is a class of deep neural networks most commonly applied to analyze visual imagery.
Different Steps of CNN
We can understand from the above picture that a CNN generally takes an image as input. The neural network analyzes each pixel separately. The weights and biases of the model are then tweaked to detect the desired letters (In our use case) from the image. Like other algorithms, the data also has to pass through pre-processing stage. However, a CNN needs relatively less pre-processing than most other Deep Learning algorithms.
If you want to know more about this, there is an excellent article on CNN with some on-point animations explaining this concept. Please read it here.
Where do we get the data sets for our testing?
For testing, we are fortunate enough to have Kaggle with us. We have received a wide variety of sample data, which you can get from here.
Our use-case:
Architecture
From the above diagram, one can see that the python application will consume a live video feed of any random letters (both printed & handwritten) & predict the character as part of the machine learning model that we trained.
Code:
clsConfig.py (Configuration file for the entire application.)
This file contains hidden or bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters. Learn more about bidirectional Unicode characters
Since we have 26 letters, we have classified it as 26 in the numOfClasses.
Since we are talking about characters, we had to come up with a process of identifying each character as numbers & then processing our entire logic. Hence, the above parameter named word_dict captured all the characters in a python dictionary & stored them. Moreover, the application translates the final number output to more appropriate characters as the prediction.
2. clsAlphabetReading.py (Main training class to teach the model to predict alphabets from visual reader.)
This file contains hidden or bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters. Learn more about bidirectional Unicode characters
We are splitting the data into Train, Test & Validation sets to get more accurate predictions and reshaping the raw data into the image by consuming the 784 data columns to 28×28 pixel images.
Since we are talking about characters, we had to come up with a process of identifying The following snippet will plot the character equivalent number into a matplotlib chart & showcase the overall distribution trend after splitting.
Y_Train_Num = np.int0(y)
count = np.zeros(numOfClasses, dtype='int')
for i in Y_Train_Num:
count[i] +=1
alphabets = []
for i in word_dict.values():
alphabets.append(i)
fig, ax = plt.subplots(1,1, figsize=(7,7))
ax.barh(alphabets, count)
plt.xlabel("Number of elements ")
plt.ylabel("Alphabets")
plt.grid()
plt.show(block=False)
plt.pause(sleepTime)
plt.close()
Note that we have tweaked the plt.show property with (block=False). This property will enable us to continue execution without human interventions after the initial pause.
# Model reshaping the training & test dataset
X_Train = X_Train.reshape(X_Train.shape[0],X_Train.shape[1],X_Train.shape[2],1)
print("Shape of Train Data: ", X_Train.shape)
X_Test = X_Test.reshape(X_Test.shape[0], X_Test.shape[1], X_Test.shape[2],1)
print("Shape of Test Data: ", X_Test.shape)
X_Validation = X_Validation.reshape(X_Validation.shape[0], X_Validation.shape[1], X_Validation.shape[2],1)
print("Shape of Validation data: ", X_Validation.shape)
# Converting the labels to categorical values
Y_Train_Catg = to_categorical(Y_Train, num_classes = numOfClasses, dtype='int')
print("Shape of Train Labels: ", Y_Train_Catg.shape)
Y_Test_Catg = to_categorical(Y_Test, num_classes = numOfClasses, dtype='int')
print("Shape of Test Labels: ", Y_Test_Catg.shape)
Y_Validation_Catg = to_categorical(Y_Validation, num_classes = numOfClasses, dtype='int')
print("Shape of validation labels: ", Y_Validation_Catg.shape)
In the above diagram, the application did reshape all three categories of data before calling the primary CNN function.
In the above snippet, the convolution layers are followed by maxpool layers, which reduce the number of features extracted. The output of the maxpool layers and convolution layers are flattened into a vector of a single dimension and supplied as an input to the Dense layer—the CNN model prepared for training the model using the training dataset.
We have used optimization parameters like Adam, RMSProp & the application we trained for eight epochs for better accuracy & predictions.
# Displaying the accuracies & losses for train & validation set
print("Validation Accuracy :", history.history['val_accuracy'])
print("Training Accuracy :", history.history['accuracy'])
print("Validation Loss :", history.history['val_loss'])
print("Training Loss :", history.history['loss'])
# Displaying the Loss Graph
plt.figure(1)
plt.plot(history.history['loss'])
plt.plot(history.history['val_loss'])
plt.legend(['training','validation'])
plt.title('Loss')
plt.xlabel('epoch')
plt.show(block=False)
plt.pause(sleepTime1)
plt.close()
# Dsiplaying the Accuracy Graph
plt.figure(2)
plt.plot(history.history['accuracy'])
plt.plot(history.history['val_accuracy'])
plt.legend(['training','validation'])
plt.title('Accuracy')
plt.xlabel('epoch')
plt.show(block=False)
plt.pause(sleepTime1)
plt.close()
Also, we have captured the validation Accuracy & Loss & plot them into two separate graphs for better understanding.
Also, the application is trying to get the accuracy of the model that we trained & validated with the training & validation data. This time we have used test data to predict the confidence score.
# Displaying some of the test images & their predicted labels
fig, ax = plt.subplots(3,3, figsize=(8,9))
axes = ax.flatten()
for i in range(9):
axes[i].imshow(np.reshape(X_Test[i], reshapeVal1), cmap="Greys")
pred = word_dict[np.argmax(Y_Test_Catg[i])]
print('Prediction: ', pred)
axes[i].set_title("Test Prediction: " + pred)
axes[i].grid()
plt.show(block=False)
plt.pause(sleepTime1)
plt.close()
Finally, the application testing with some random test data & tried to plot the output & prediction assessment.
As a part of the last step, the application will generate the models using a pickle package & save them under a specific location, which the reader application will use.
3. trainingVisualDataRead.py (Main application that will invoke the training class to predict alphabet through WebCam using Convolutional Neural Network (CNN).)
This file contains hidden or bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters. Learn more about bidirectional Unicode characters
The python application will invoke the class & capture the returned value inside the r1 variable.
4. readingVisualData.py (Reading the model to predict Alphabet using WebCAM.)
This file contains hidden or bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters. Learn more about bidirectional Unicode characters
We have initially cloned the original video frame & then it converted from BGR2GRAYSCALE while applying the threshold on it doe better prediction outcomes. Then the image has resized & reshaped for model input. Finally, the np.argmax function extracted the class index with the highest predicted probability. Furthermore, it is translated using the word_dict dictionary to an Alphabet & displayed on top of the Live View.
Also, derive the confidence score of that probability & display that on top of the Live View.
if cv2.waitKey(1) & 0xFF == ord('q'):
r1=0
break
The above code will let the developer exit from this application by pressing the “Esc” or “q”-key from the keyboard & the program will terminate.
So, we’ve done it.
You will get the complete codebase in the following Github link.
I’ll bring some more exciting topic in the coming days from the Python verse. Please share & subscribe my post & let me know your feedback.
Till then, Happy Avenging! 😀
Note: All the data & scenario posted here are representational data & scenarios & available over the internet & for educational purpose only. Some of the images (except my photo) that we’ve used are available over the net. We don’t claim the ownership of these images. There is an always room for improvement & especially the prediction quality of Alphabet.
Today, I’ll be demonstrating some scenarios based on open-source data from Canada. In this post, I will only explain some of the significant parts of the code. Not the entire range of scripts here.
Let’s explore a couple of sample source data –
I would like to explore how much this disease caused an impact on the elderly in Canada.
Let’s explore the source directory structure –
For this, you need to install the following packages –
In this case, we’ve downloaded the data from Canada’s site. However, they have created API. So, you can consume the data through that way as well. Since the volume is a little large. I decided to download that in CSV & then use that for my analysis.
Before I start, let me explain a couple of critical assumptions that I had to make due to data impurities or availabilities.
If there is no data available for a specific case, my application will consider that patient as COVID-Active.
We will consider the patient is affected through Community-spreading until we have data to find it otherwise.
If there is no data available for gender, we’re marking these records as “Other.” So, that way, we’re making it into that category, where the patient doesn’t want to disclose their sexual orientation.
If we don’t have any data, then by default, the application is considering the patient is alive.
Lastly, my application considers the middle point of the age range data for all the categories, i.e., the patient’s age between 20 & 30 will be considered as 25.
1. clsCovidAnalysisByCountryAdv (This is the main script, which will invoke the Machine-Learning API & return 0 if successful.)
################################################## Written By: SATYAKI DE ######## Written On: 01-Jun-2020 ######## Modified On 01-Jun-2020 ######## ######## Objective: Main scripts for Logistic ######## Regression. ##################################################importpandasaspimportclsLaslogimportdatetimeimportmatplotlib.pyplotaspltimportseabornassnsfromclsConfigimport clsConfig as cf
# %matplotlib inline -- for Jupyter NotebookclassclsCovidAnalysisByCountryAdv:
def__init__(self):
self.fileName_1 = cf.config['FILE_NAME_1']
self.fileName_2 = cf.config['FILE_NAME_2']
self.Ind = cf.config['DEBUG_IND']
self.subdir =str(cf.config['LOG_DIR_NAME'])
defsetDefaultActiveCases(self, row):
try:
str_status =str(row['case_status'])
if str_status =='Not Reported':
return'Active'else:
return str_status
except:
return'Active'defsetDefaultExposure(self, row):
try:
str_exposure =str(row['exposure'])
if str_exposure =='Not Reported':
return'Community'else:
return str_exposure
except:
return'Community'defsetGender(self, row):
try:
str_gender =str(row['gender'])
if str_gender =='Not Reported':
return'Other'else:
return str_gender
except:
return'Other'defsetSurviveStatus(self, row):
try:
# 0 - Deceased# 1 - Alive
str_active =str(row['ActiveCases'])
if str_active =='Deceased':
return0else:
return1except:
return1defgetAgeFromGroup(self, row):
try:
# We'll take the middle of the Age group# If a age range falls with 20, we'll# consider this as 10.# Similarly, a age group between 20 & 30,# should reflect by 25.# Anything above 80 will be considered as# 85
str_age_group =str(row['AgeGroup'])
if str_age_group =='<20':
return10elif str_age_group =='20-29':
return25elif str_age_group =='30-39':
return35elif str_age_group =='40-49':
return45elif str_age_group =='50-59':
return55elif str_age_group =='60-69':
return65elif str_age_group =='70-79':
return75else:
return85except:
return100defpredictResult(self):
try:
# Initiating Logging Instances
clog = log.clsL()
# Important variables
var = datetime.datetime.now().strftime(".%H.%M.%S")
print('Target File Extension will contain the following:: ', var)
Ind =self.Ind
subdir =self.subdir
######################################## ## Using Logistic Regression to ## Idenitfy the following scenarios - ## ## Age wise Infection Vs Deaths ## ########################################
inputFileName_2 =self.fileName_2
# Reading from Input File
df_2 = p.read_csv(inputFileName_2)
# Fetching only relevant columns
df_2_Mod = df_2[['date_reported','age_group','gender','exposure','case_status']]
df_2_Mod['State'] = df_2['province_abbr']
print()
print('Projecting 2nd file sample rows: ')
print(df_2_Mod.head())
print()
x_row_1 = df_2_Mod.shape[0]
x_col_1 = df_2_Mod.shape[1]
print('Total Number of Rows: ', x_row_1)
print('Total Number of columns: ', x_col_1)
########################################################################################## Few Assumptions ########################################################################################### By default, if there is no data on exposure - We'll treat that as community spreading ## By default, if there is no data on case_status - We'll consider this as active ## By default, if there is no data on gender - We'll put that under a separate Gender ## category marked as the "Other". This includes someone who doesn't want to identify ## his/her gender or wants to be part of LGBT community in a generic term. ## ## We'll transform our data accordingly based on the above logic. ##########################################################################################
df_2_Mod['ActiveCases'] = df_2_Mod.apply(lambda row: self.setDefaultActiveCases(row), axis=1)
df_2_Mod['ExposureStatus'] = df_2_Mod.apply(lambda row: self.setDefaultExposure(row), axis=1)
df_2_Mod['Gender'] = df_2_Mod.apply(lambda row: self.setGender(row), axis=1)
# Filtering all other records where we don't get any relevant information# Fetching Data for
df_3 = df_2_Mod[(df_2_Mod['age_group'] !='Not Reported')]
# Dropping unwanted columns
df_3.drop(columns=['exposure'], inplace=True)
df_3.drop(columns=['case_status'], inplace=True)
df_3.drop(columns=['date_reported'], inplace=True)
df_3.drop(columns=['gender'], inplace=True)
# Renaming one existing column
df_3.rename(columns={"age_group": "AgeGroup"}, inplace=True)
# Creating important feature# 0 - Deceased# 1 - Alive
df_3['Survived'] = df_3.apply(lambda row: self.setSurviveStatus(row), axis=1)
clog.logr('2.df_3'+ var +'.csv', Ind, df_3, subdir)
print()
print('Projecting Filter sample rows: ')
print(df_3.head())
print()
x_row_2 = df_3.shape[0]
x_col_2 = df_3.shape[1]
print('Total Number of Rows: ', x_row_2)
print('Total Number of columns: ', x_col_2)
# Let's do some basic checkings
sns.set_style('whitegrid')
#sns.countplot(x='Survived', hue='Gender', data=df_3, palette='RdBu_r')# Fixing Gender Column# This will check & indicate yellow for missing entries#sns.heatmap(df_3.isnull(), yticklabels=False, cbar=False, cmap='viridis')#sex = p.get_dummies(df_3['Gender'], drop_first=True)
sex = p.get_dummies(df_3['Gender'])
df_4 = p.concat([df_3, sex], axis=1)
print('After New addition of columns: ')
print(df_4.head())
clog.logr('3.df_4'+ var +'.csv', Ind, df_4, subdir)
# Dropping unwanted columns for our Machine Learning
df_4.drop(columns=['Gender'], inplace=True)
df_4.drop(columns=['ActiveCases'], inplace=True)
df_4.drop(columns=['Male','Other','Transgender'], inplace=True)
clog.logr('4.df_4_Mod'+ var +'.csv', Ind, df_4, subdir)
# Fixing Spread Columns
spread = p.get_dummies(df_4['ExposureStatus'], drop_first=True)
df_5 = p.concat([df_4, spread], axis=1)
print('After Spread columns:')
print(df_5.head())
clog.logr('5.df_5'+ var +'.csv', Ind, df_5, subdir)
# Dropping unwanted columns for our Machine Learning
df_5.drop(columns=['ExposureStatus'], inplace=True)
clog.logr('6.df_5_Mod'+ var +'.csv', Ind, df_5, subdir)
# Fixing Age Columns
df_5['Age'] = df_5.apply(lambda row: self.getAgeFromGroup(row), axis=1)
df_5.drop(columns=["AgeGroup"], inplace=True)
clog.logr('7.df_6'+ var +'.csv', Ind, df_5, subdir)
# Fixing Dummy Columns Name# Renaming one existing column Travel-Related with Travel_Related
df_5.rename(columns={"Travel-Related": "TravelRelated"}, inplace=True)
clog.logr('8.df_7'+ var +'.csv', Ind, df_5, subdir)
# Removing state for temporary basis
df_5.drop(columns=['State'], inplace=True)
# df_5.drop(columns=['State','Other','Transgender','Pending','TravelRelated','Male'], inplace=True)# Casting this entire dataframe into Integer# df_5_temp.apply(p.to_numeric)print('Info::')
print(df_5.info())
print("*"*60)
print(df_5.describe())
print("*"*60)
clog.logr('9.df_8'+ var +'.csv', Ind, df_5, subdir)
print('Intermediate Sample Dataframe for Age::')
print(df_5.head())
# Plotting it to Graphsns.jointplot(x="Age", y='Survived', data=df_5)
sns.jointplot(x="Age", y='Survived', data=df_5, kind='kde', color='red')
plt.xlabel("Age")
plt.ylabel("Data Point (0 - Died Vs 1 - Alive)")# Another check with Age Group
sns.countplot(x='Survived', hue='Age', data=df_5, palette='RdBu_r')
plt.xlabel("Survived(0 - Died Vs 1 - Alive)")
plt.ylabel("Total No Of Patient")
df_6 = df_5.drop(columns=['Survived'], axis=1)
clog.logr('10.df_9'+ var +'.csv', Ind, df_6, subdir)
# Train & Split Data
x_1 = df_6
y_1 = df_5['Survived']
# Now Train-Test Split of your source datafromsklearn.model_selectionimport train_test_split
# test_size => % of allocated data for your test cases# random_state => A specific set of random split on your data
X_train_1, X_test_1, Y_train_1, Y_test_1 = train_test_split(x_1, y_1, test_size=0.3, random_state=101)
# Importing Modelfromsklearn.linear_modelimport LogisticRegression
logmodel = LogisticRegression()
logmodel.fit(X_train_1, Y_train_1)
# Adding Predictions to it
predictions_1 = logmodel.predict(X_test_1)
fromsklearn.metricsimport classification_report
print('Classification Report:: ')
print(classification_report(Y_test_1, predictions_1))
fromsklearn.metricsimport confusion_matrix
print('Confusion Matrix:: ')
print(confusion_matrix(Y_test_1, predictions_1))
# This is require when you are trying to print from conventional# front & not using Jupyter notebook.
plt.show()
return0exceptExceptionas e:
x =str(e)
print('Error : ', x)
return1
Key snippets from the above script –
df_2_Mod['ActiveCases'] = df_2_Mod.apply(lambda row: self.setDefaultActiveCases(row), axis=1)df_2_Mod['ExposureStatus'] = df_2_Mod.apply(lambda row: self.setDefaultExposure(row), axis=1)df_2_Mod['Gender'] = df_2_Mod.apply(lambda row: self.setGender(row), axis=1)# Filtering all other records where we don't get any relevant information# Fetching Data fordf_3 = df_2_Mod[(df_2_Mod['age_group'] != 'Not Reported')]# Dropping unwanted columnsdf_3.drop(columns=['exposure'], inplace=True)df_3.drop(columns=['case_status'], inplace=True)df_3.drop(columns=['date_reported'], inplace=True)df_3.drop(columns=['gender'], inplace=True)# Renaming one existing columndf_3.rename(columns={"age_group": "AgeGroup"}, inplace=True)# Creating important feature# 0 - Deceased# 1 - Alivedf_3['Survived'] = df_3.apply(lambda row: self.setSurviveStatus(row), axis=1)
The above lines point to the critical transformation areas, where the application is invoking various essential business logic.
The above lines will transform the data into this –
As you can see, we’ve transformed the row values into columns with binary values. This kind of transformation is beneficial.
# Plotting it to Graphsns.jointplot(x="Age", y='Survived', data=df_5)sns.jointplot(x="Age", y='Survived', data=df_5, kind='kde', color='red')plt.xlabel("Age")plt.ylabel("Data Point (0 - Died Vs 1 - Alive)")# Another check with Age Groupsns.countplot(x='Survived', hue='Age', data=df_5, palette='RdBu_r')plt.xlabel("Survived(0 - Died Vs 1 - Alive)")plt.ylabel("Total No Of Patient")
The above lines will process the data & visualize based on that.
x_1 = df_6y_1 = df_5['Survived']
In the above snippet, we’ve assigned the features & target variable for our final logistic regression model.
# Now Train-Test Split of your source datafrom sklearn.model_selection import train_test_split# test_size => % of allocated data for your test cases# random_state => A specific set of random split on your dataX_train_1, X_test_1, Y_train_1, Y_test_1 = train_test_split(x_1, y_1, test_size=0.3, random_state=101)# Importing Modelfrom sklearn.linear_model import LogisticRegressionlogmodel = LogisticRegression()logmodel.fit(X_train_1, Y_train_1)
In the above snippet, we’re splitting the primary data & create a set of test & train data. Once we have the collection, the application will put the logistic regression model. And, finally, we’ll fit the training data.
The above lines, finally use the model & then we feed our test data.
Let’s see how it runs –
And, here is the log directory –
For better understanding, I’m just clubbing both the diagram at one place & the final outcome is showing as follows –
So, from the above picture, we can see that the maximum vulnerable patients are patients who are 80+. The next two categories that also suffered are 70+ & 60+.
Also, We’ve checked the Female Vs. Male in the following code –
sns.countplot(x='Survived', hue='Female', data=df_5, palette='RdBu_r')plt.xlabel("Survived(0 - Died Vs 1 - Alive)")plt.ylabel("Female Vs Male (Including Other Genders)")
And, the analysis represents through this –
In this case, you have to consider that the Male part includes all the other genders apart from the actual Male. Hence, I believe death for females would be more compared to people who identified themselves as males.
So, finally, we’ve done it.
During this challenging time, I would request you to follow strict health guidelines & stay healthy.
N.B.: All the data that are used here can be found in the public domain. We use this solely for educational purposes. You can find the details here.
So, here we come up with another crossover of Space Stone, Reality Stone & Mind Stone of Python-Verse. It is indeed exciting & I cannot wait to explore that part further. Today, in this post, we’ll see how one application can integrate all these key ingredients in Python to serve the purpose. Our key focus will be involving popular packages like Pandas, Numpy & Popular Encryption-Decryption techniques, which include some hidden files as well.
So, our objective here is to proceed with the encryption & decryption technique. But, there is a catch. We need to store some salt or tokenized value inside a hidden file. Our application will extract the salt value from it & then based on that it will perform Encrypt/Decrypt on the data.
Why do we need this approach?
The answer is simple. On many occasions, we don’t want to store our right credentials in configuration files. Also, we don’t want to keep our keys to open to other developers. There are many ways you can achieve this kind of security. Today, I’ll be showing a different approach to make the same.
Let’s explore.
As usual, I’ll provide the solution, which is tested in Windows & MAC & provide the script. Also, I’ll explain the critical lines of those scripts to understand it from a layman point of view. And, I won’t explain any script, which I’ve already explained in my earlier post. So, you have to refer my old post for that.
To encrypt & decrypt, we need the following files, which contains credentials in a csv. Please find the sample data –
Config_orig.csv
Please see the file, which will be hidden by the application process.
As you can see, this column contains the salt, which will be used in our Encryption/Decryption.
1. clsL.py (This script will create the csv files or any intermediate debug csv file after the corresponding process. Hence, the name comes into the picture.)
The above two lines under doit() functions are changing the file attributes in Windows OS to the hidden mode by assigning the FILE_ATTRIBUTE_HIDDEN property.
As the script suggested, the application is setting the file attribute of a hidden file to FILE_ATTRIBUTE_NORMAL & set the correct flag from parameters, which leads to the file appears as a normal windows file.
4. clsOSXHide.py (This script contains the core logic of hiding/unhiding a file under OSX, i.e., MAC OS. Hence, the name comes into the picture.)
In this case, our application simply renaming a file with its the original file to get the file as a normal file.
Let’s understand that in Linux or MAC, you have a lot of other ways to restrict any files as it has much more granular level access control. But, I thought, why not take a slightly different & fun way to achieve the same. After all, we’re building an Infinity War for Python verse. A little bit of fun will certainly make some sense. 🙂
5. clsProcess.py (This script will invoke any of the hide scripts, i.e. clsWinHide.py or clsOSXHide.py based on the OS platform. Hence, the name comes into the picture.)
############################################### Written By: SATYAKI DE ########## Written On: 25-Jan-2019 ########## ########## Objective: Based on the OS, this########## script calls the actual script. #################################################fromclsParamimport clsParam as cp
plat_det = cp.config['OS_DET']
# Based on the platform# Application is loading subprocess# in order to avoid library missing# case against cross platformif plat_det =="Windows":
importclsWinHideaswinelse:
importclsOSXHideasosx# End of conditional class loadclassclsProcess(object):
def__init__(self):
self.os_det = plat_det
defdoit(self):
try:
os_det =self.os_det
print("OS Info: ", os_det)
if os_det =="Windows":
win_doit = win.clsWinHide()
ret_val = win_doit.doit()
else:
osx_doit = osx.clsOSXHide()
ret_val = osx_doit.doit()
return ret_val
exceptExceptionas e:
x =str(e)
print(x)
return1defundoit(self):
try:
os_det =self.os_det
print("OS Info: ", os_det)
if os_det =="Windows":
win_doit = win.clsWinHide()
ret_val = win_doit.undoit()
else:
osx_doit = osx.clsOSXHide()
ret_val = osx_doit.undoit()
return ret_val
exceptExceptionas e:
x =str(e)
print(x)
return1
Key lines to explores are as follows –
from clsParam import clsParam as cpplat_det = cp.config['OS_DET']# Based on the platform# Application is loading subprocess# in order to avoid library missing# case against cross platformif plat_det == "Windows": import clsWinHide as winelse: import clsOSXHide as osx
This step is very essential to run the same python scripts in both the environments, e.g. in this case like MAC & Windows.
So, based on the platform details, which the application is getting from the clsParam class, it is loading the specific class to the application. And why it is so important.
Under Windows OS, this will work if you load both the class. But, under MAC, this will fail as the first program will try to load all the libraries & it may happen that the pywin32/pypiwin32 package might not available under MAC. Anyway, you are not even using that package. So, this conditional class loading is significant.
As you can see that, based on the OS, it is invoking the correct function of that corresponding class.
6. clsEnDec.py (This script will read the credentials from a csv file & then based on the salt captured from the hidden file, it will either encrypt or decrypt the content. Hence, the name comes into the picture.)
############################################### Written By: SATYAKI DE ############ Written On: 25-Jan-2019 ############ Package Cryptography needs to ############ install in order to run this ############ script. ############ ############ Objective: This script will ############ encrypt/decrypt based on the ############ hidden supplied salt value. ###################################################importpandasaspfromcryptography.fernetimport Fernet
classclsEnDec(object):
def__init__(self, token):
# Calculating Keyself.token = token
defencrypt_str(self):
try:
# Capturing the Salt Information
salt =self.token
# Fetching the content of lookup file
df_orig = p.read_csv('Config_orig.csv', index_col=False)
# Checking Individual Types inside the Dataframe
cipher = Fernet(salt)
df_orig['User'] = df_orig['User'].apply(lambda x1: cipher.encrypt(bytes(x1,'utf8')))
df_orig['Pwd'] = df_orig['Pwd'].apply(lambda x2: cipher.encrypt(bytes(x2,'utf8')))
# Writing to the File
df_orig.to_csv('Encrypt_Config.csv', index=False)
return0exceptExceptionas e:
x =str(e)
print(x)
return1defdecrypt_str(self):
try:
# Capturing the Salt Information
salt =self.token
# Checking Individual Types inside the Dataframe
cipher = Fernet(salt)
# Fetching the Encrypted csv file
df_orig = p.read_csv('Encrypt_Config.csv', index_col=False)
df_orig['User'] = df_orig['User'].apply(lambda x1: str(cipher.decrypt(bytes(x1[2:-1],'utf8'))).replace("b'","").replace("'",""))
df_orig['Pwd'] = df_orig['Pwd'].apply(lambda x2: str(cipher.decrypt(bytes(x2[2:-1],'utf8'))).replace("b'","").replace("'",""))
# Writing to the file
df_orig.to_csv('Decrypt_Config.csv', index=False)
return0exceptExceptionas e:
x =str(e)
print(x)
return1
So, once you captured the salt from that hidden file, the application is capturing that value over here. And, based on that both the field will be encrypted. But, note that cryptography package is required for this. And, you need to pass bytes value to work this thing. Hence, we’ve used bytes() function over here.
Again, in this step, our application is extracting the salt & then it retrieves the encrypted values of corresponding fields & applies the decryption logic on top of it. Note that, since we need to pass bytes value to get it to work. Hence, your output will be appended with (b’xxxxx’). To strip that, we’ve used the replace() functions. You can use regular expression using pattern matching as well.
7. callEnDec.py (This script will create the split csv files or final merge file after the corresponding process. However, this can be used as normal verbose debug logging as well. Hence, the name comes into the picture.)
############################################### Written By: SATYAKI DE ######### Written On: 25-Jan-2019 ######### ######### Objective: Main calling function ################################################importclsEnDecasedimportclsProcessashfromclsParamimport clsParam as cp
importtimeastimportpandasaspdefmain():
print("")
print("#"*60)
print("Calling (Encryption/Decryption) Package!!")
print("#"*60)
print("")
# Unhiding the file
x = h.clsProcess()
ret_val_unhide = x.undoit()
if ret_val_unhide ==0:
print("Successfully Unhide the file!")
else:
print("Unsuccessful to Unhide the file!")
# To See the Unhide file
t.sleep(10)
print("*"*60)
print("Proceeding with Encryption...")
print("*"*60)
# Getting Salt Value from the hidden files# by temporarily making it available
FileName = cp.config['FILENAME']
df = p.read_csv(FileName, index_col=False)
salt =str(df.iloc[0]['Token_Salt'])
print("-"*60)
print("Salt: ", salt)
print("-"*60)
# Calling the Encryption Method
x = ed.clsEnDec(salt)
ret_val = x.encrypt_str()
if ret_val ==0:
print("Encryption Successful!")
else:
print("Encryption Failure!")
print("")
print("*"*60)
print("Checking Decryption Now...")
print("*"*60)
# Calling the Decryption Method
ret_val1 = x.decrypt_str()
if ret_val1 ==0:
print("Decryption Successful!")
else:
print("Decryption Failure!")
# Hiding the salt file
x = h.clsProcess()
ret_val_hide = x.doit()
if ret_val_hide ==0:
print("Successfully Hide the file!")
else:
print("Unsuccessful to Hide the file!")
print("*"*60)
print("Operation Done!")
print("*"*60)
if __name__ =='__main__':
main()
And, here comes the final calling methods.
The key lines that we would like to discuss –
# Getting Salt Value from the hidden files# by temporarily making it availableFileName = cp.config['FILENAME']df = p.read_csv(FileName, index_col=False)salt = str(df.iloc[0]['Token_Salt'])
As I’ve shown that, we have our hidden files that contain only 1 row & 1 column. To extract the specific value we’ve used iloc with the row number as 0 along with the column name, i.e. Token_Salt.
Now, let’s see how it runs –
Windows (64 bit):
Mac (32 bit):
So, from the screenshot, we can see our desired output & you can calculate the aggregated value based on our sample provided in the previous screenshot.
Let’s check the Encrypted & Decrypted values –
Encrypted Values (Encrypt_Config.csv):
Decrypted Values (Decrypt_Config.csv):
So, finally, we’ve achieved our target.
I hope this will give you some more idea about more insights into the Python verse. Let me know – how do you think about this post.


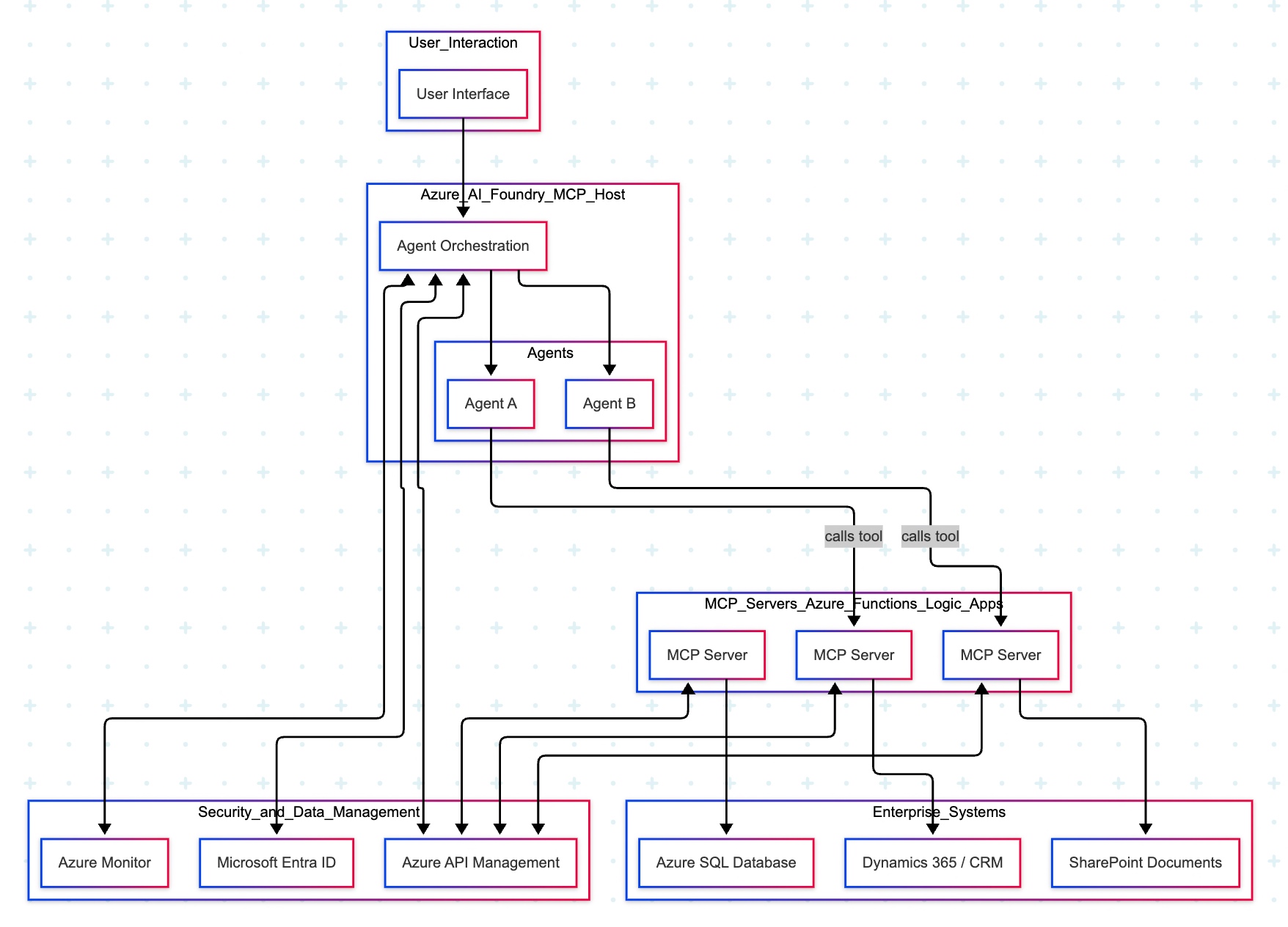
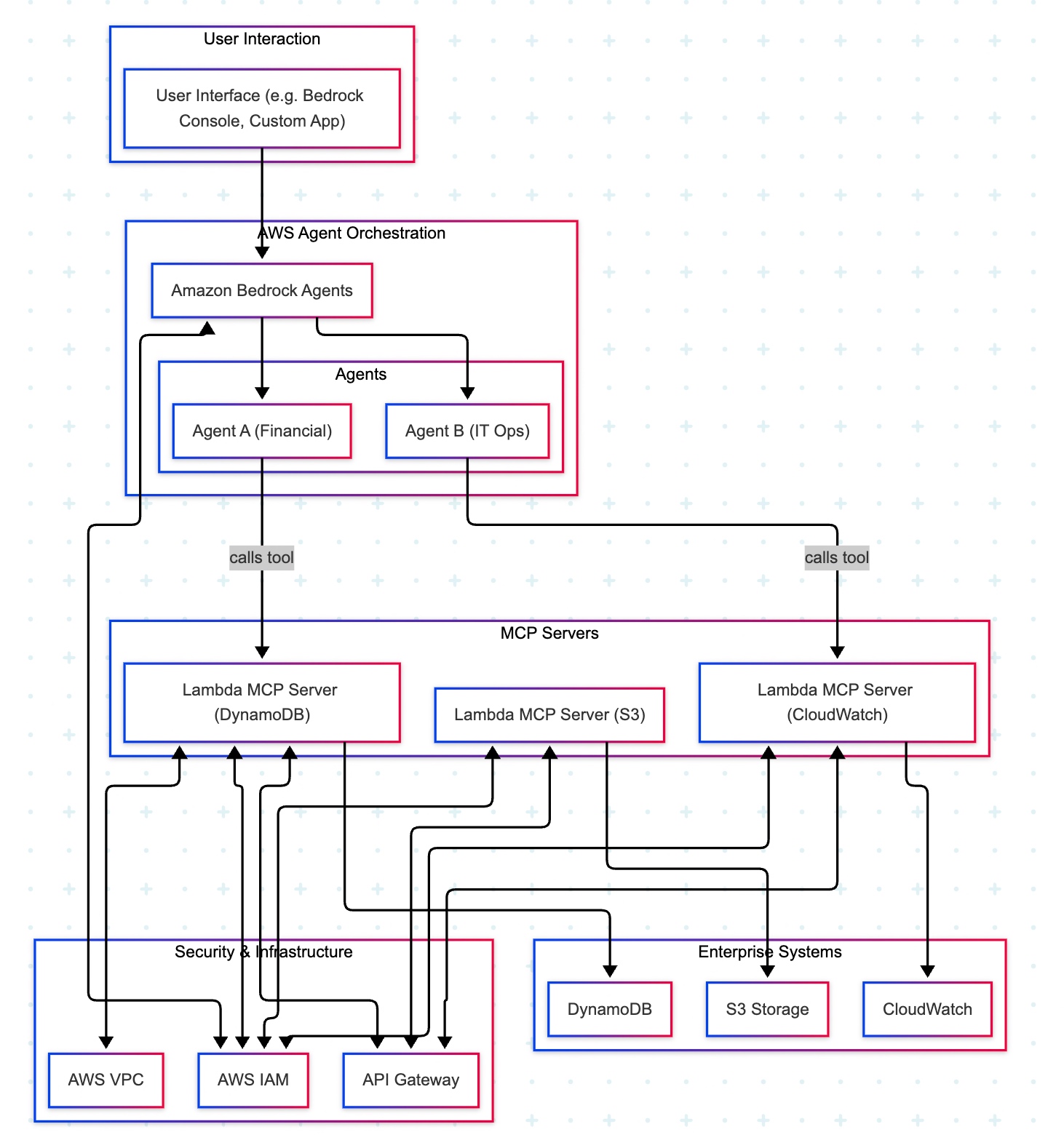








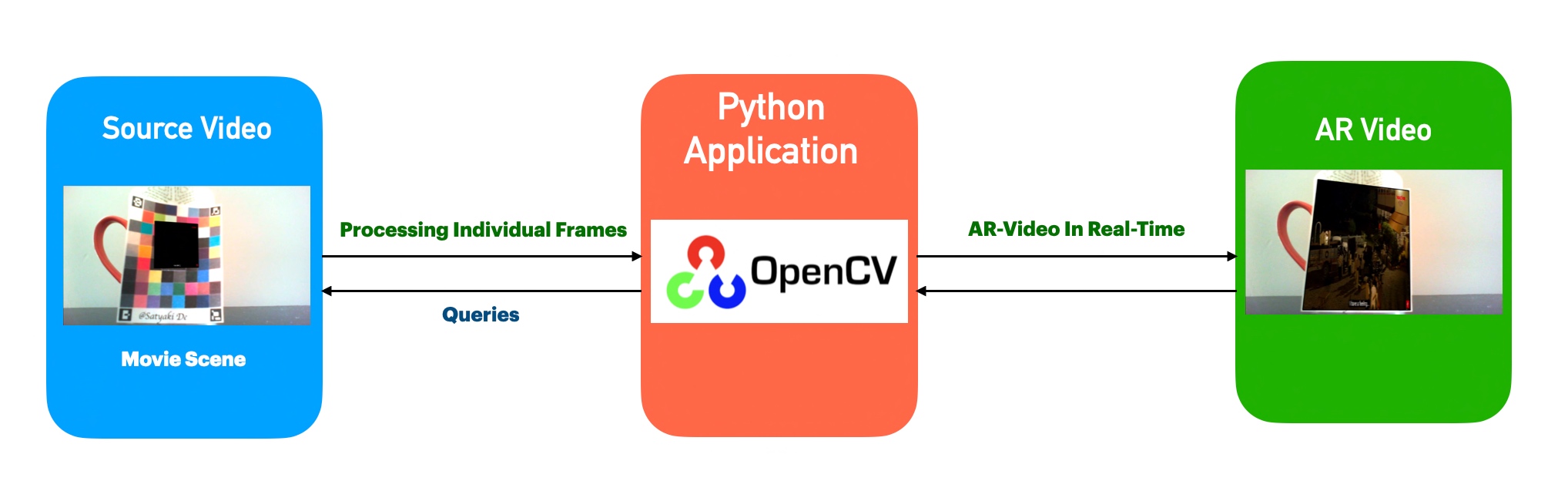


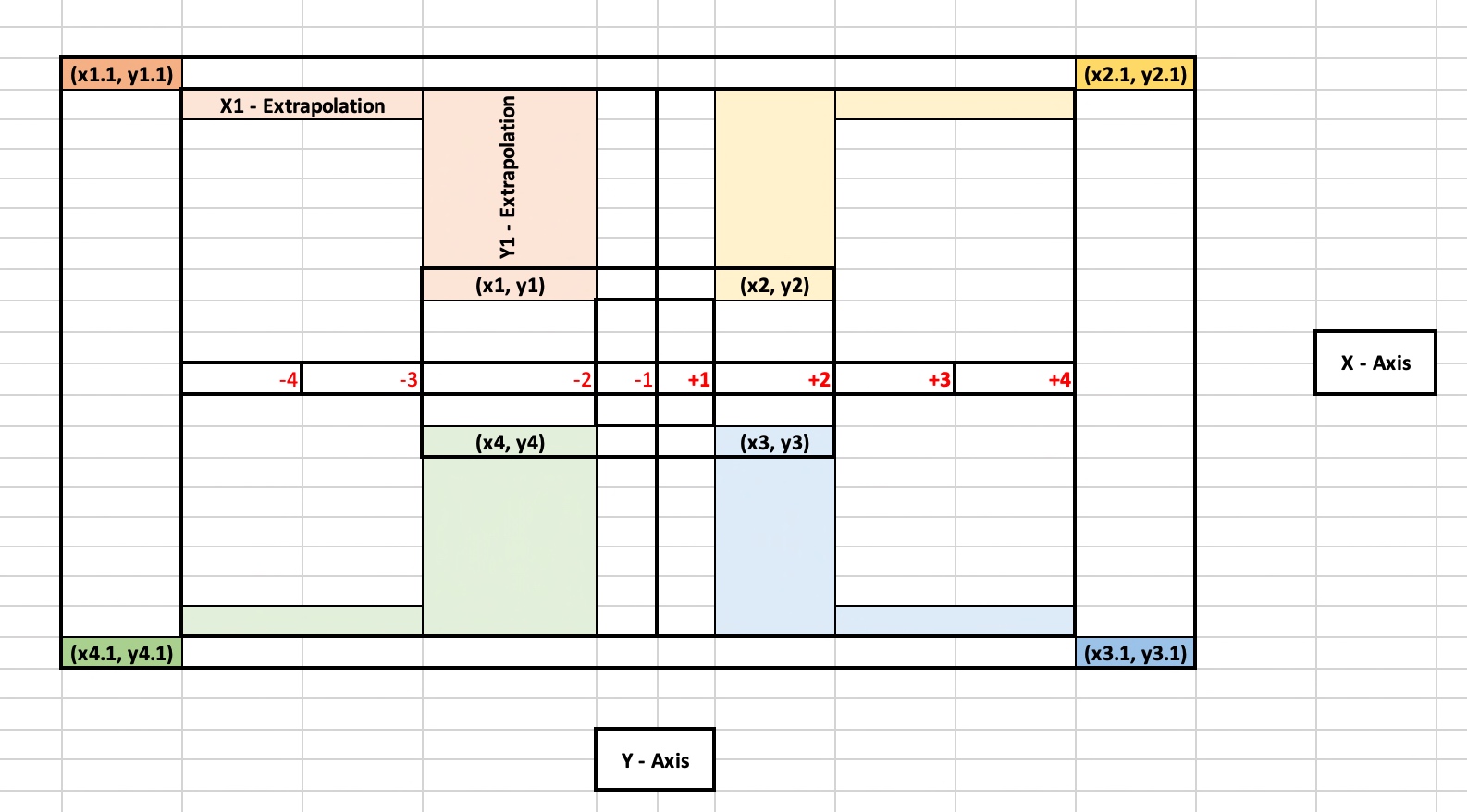























You must be logged in to post a comment.