
Today, I will share a new post in a part series about creating end-end LLMs that feed source data with RAG implementation. I’ll also use OpenAI python-based SDK and Haystack embeddings in this case.
In this post, I’ve directly subscribed to OpenAI & I’m not using OpenAI from Azure. However, I’ll explore that in the future as well.
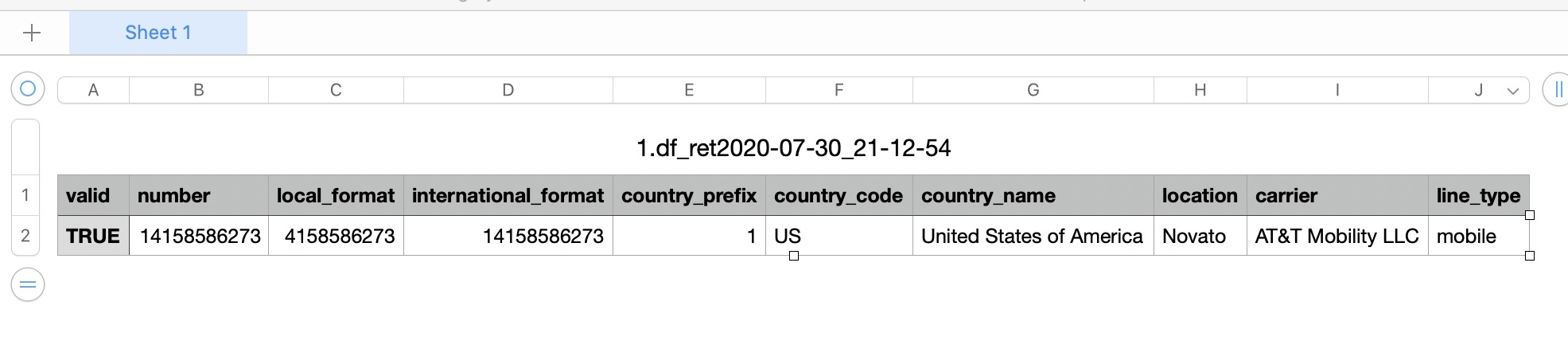
Before I explain the process to invoke this new library, why not view the demo first & then discuss it?
FLOW OF EVENTS:
Let us look at the flow diagram as it captures the sequence of events that unfold as part of the process.

As you can see, to enable this large & complex solution, we must first establish the capabilities to build applications powered by LLMs, Transformer models, vector search, and more. You can use state-of-the-art NLP models to perform question-answering, answer generation, semantic document search, or build tools capable of complex decision-making and query resolution. Hence, steps no. 1 & 2 showcased the data embedding & creating that informed repository. We’ll be discussing that in our second part.
Once you have the informed repository, the system can interact with the end-users. As part of the query (shown in step 3), the prompt & the question are shared with the process engine, which then turned to reduce the volume & get relevant context from our informed repository & get the tuned context as part of the response (Shown in steps 4, 5 & 6).
Then, this tuned context is shared with the OpenAI for better response & summary & concluding remarks that are very user-friendly & easier to understand for end-users (Shown in steps 8 & 9).
IMPORTANT PACKAGES:
The following are the important packages that are essential to this project –
pip install farm-haystack==1.19.0
pip install Flask==2.2.5
pip install Flask-Cors==4.0.0
pip install Flask-JWT-Extended==4.5.2
pip install Flask-Session==0.5.0
pip install openai==0.27.8
pip install pandas==2.0.3
pip install tensorflow==2.11.1CODE:
We’ve both the front-end using react & back-end APIs with Python-flask and the Open AI to create this experience.
Python:
Today, we’ll be going in reverse mode. We first discuss the main script & then explain all the other class scripts.
- flaskServer.py (This is the main calling Python script to invoke the RAG-Server.)
#########################################################
#### Written By: SATYAKI DE ####
#### Written On: 27-Jun-2023 ####
#### Modified On 28-Jun-2023 ####
#### ####
#### Objective: This is the main calling ####
#### python script that will invoke the ####
#### shortcut application created inside MAC ####
#### enviornment including MacBook, IPad or IPhone. ####
#### ####
#########################################################
from flask import Flask, jsonify, request, session
from flask_cors import CORS
from werkzeug.security import check_password_hash, generate_password_hash
from flask_jwt_extended import JWTManager, jwt_required, create_access_token
import pandas as pd
from clsConfigClient import clsConfigClient as cf
import clsL as log
import clsContentScrapper as csc
import clsRAGOpenAI as crao
import csv
from datetime import timedelta
import os
import re
import json
########################################################
################ Global Area ######################
########################################################
#Initiating Logging Instances
clog = log.clsL()
admin_key = cf.conf['ADMIN_KEY']
secret_key = cf.conf['SECRET_KEY']
session_path = cf.conf['SESSION_PATH']
sessionFile = cf.conf['SESSION_CACHE_FILE']
app = Flask(__name__)
CORS(app) # This will enable CORS for all routes
app.config['JWT_SECRET_KEY'] = admin_key # Change this!
app.secret_key = secret_key
jwt = JWTManager(app)
users = cf.conf['USER_NM']
passwd = cf.conf['USER_PWD']
cCScrapper = csc.clsContentScrapper()
cr = crao.clsRAGOpenAI()
# Disbling Warning
def warn(*args, **kwargs):
pass
import warnings
warnings.warn = warn
# Define the aggregation functions
def join_unique(series):
unique_vals = series.drop_duplicates().astype(str)
return ', '.join(filter(lambda x: x != 'nan', unique_vals))
# Building the preaggregate cache
def groupImageWiki():
try:
base_path = cf.conf['OUTPUT_PATH']
inputFile = cf.conf['CLEANED_FILE']
outputFile = cf.conf['CLEANED_FILE_SHORT']
subdir = cf.conf['SUBDIR_OUT']
Ind = cf.conf['DEBUG_IND']
inputCleanedFileLookUp = base_path + inputFile
#Opening the file in dataframe
df = pd.read_csv(inputCleanedFileLookUp)
hash_values = df['Total_Hash'].unique()
dFin = df[['primaryImage','Wiki_URL','Total_Hash']]
# Ensure columns are strings and not NaN
# Convert columns to string and replace 'nan' with an empty string
dFin['primaryImage'] = dFin['primaryImage'].astype(str).replace('nan', '')
dFin['Wiki_URL'] = dFin['Wiki_URL'].astype(str).replace('nan', '')
dFin.drop_duplicates()
# Group by 'Total_Hash' and aggregate
dfAgg = dFin.groupby('Total_Hash').agg({'primaryImage': join_unique,'Wiki_URL': join_unique}).reset_index()
return dfAgg
except Exception as e:
x = str(e)
print('Error: ', x)
df = pd.DataFrame()
return df
resDf = groupImageWiki()
########################################################
################ End Global Area ####################
########################################################
def extractRemoveUrls(hash_value):
image_urls = ''
wiki_urls = ''
# Parse the inner message JSON string
try:
resDf['Total_Hash'] = resDf['Total_Hash'].astype(int)
filtered_df = resDf[resDf['Total_Hash'] == int(hash_value)]
if not filtered_df.empty:
image_urls = filtered_df['primaryImage'].values[0]
wiki_urls = filtered_df['Wiki_URL'].values[0]
return image_urls, wiki_urls
except Exception as e:
x = str(e)
print('extractRemoveUrls Error: ', x)
return image_urls, wiki_urls
def isIncomplete(line):
"""Check if a line appears to be incomplete."""
# Check if the line ends with certain patterns indicating it might be incomplete.
incomplete_patterns = [': [Link](', ': Approximately ', ': ']
return any(line.endswith(pattern) for pattern in incomplete_patterns)
def filterData(data):
"""Return only the complete lines from the data."""
lines = data.split('\n')
complete_lines = [line for line in lines if not isIncomplete(line)]
return '\n'.join(complete_lines)
def updateCounter(sessionFile):
try:
counter = 0
# Check if the CSV file exists
if os.path.exists(sessionFile):
with open(sessionFile, 'r') as f:
reader = csv.reader(f)
for row in reader:
# Assuming the counter is the first value in the CSV
counter = int(row[0])
# Increment counter
counter += 1
# Write counter back to CSV
with open(sessionFile, 'w', newline='') as f:
writer = csv.writer(f)
writer.writerow([counter])
return counter
except Exception as e:
x = str(e)
print('Error: ', x)
return 1
def getPreviousResult():
try:
fullFileName = session_path + sessionFile
newCounterValue = updateCounter(fullFileName)
return newCounterValue
except Exception as e:
x = str(e)
print('Error: ', x)
return 1
@app.route('/login', methods=['POST'])
def login():
username = request.json.get('username', None)
password = request.json.get('password', None)
print('User Name: ', str(username))
print('Password: ', str(password))
#if username not in users or not check_password_hash(users.get(username), password):
if ((username not in users) or (password not in passwd)):
return jsonify({'login': False}), 401
access_token = create_access_token(identity=username)
return jsonify(access_token=access_token)
@app.route('/chat', methods=['POST'])
def get_chat():
try:
#session["key"] = "1D98KI"
#session_id = session.sid
#print('Session Id: ', str(session_id))
cnt = getPreviousResult()
print('Running Session Count: ', str(cnt))
username = request.json.get('username', None)
message = request.json.get('message', None)
print('User: ', str(username))
print('Content: ', str(message))
if cnt == 1:
retList = cCScrapper.extractCatalog()
else:
hashValue, cleanedData = cr.getData(str(message))
print('Main Hash Value:', str(hashValue))
imageUrls, wikiUrls = extractRemoveUrls(hashValue)
print('Image URLs: ', str(imageUrls))
print('Wiki URLs: ', str(wikiUrls))
print('Clean Text:')
print(str(cleanedData))
retList = '{"records":[{"Id":"' + str(cleanedData) + '", "Image":"' + str(imageUrls) + '", "Wiki": "' + str(wikiUrls) + '"}]}'
response = {
'message': retList
}
print('JSON: ', str(response))
return jsonify(response)
except Exception as e:
x = str(e)
response = {
'message': 'Error: ' + x
}
return jsonify(response)
@app.route('/api/data', methods=['GET'])
@jwt_required()
def get_data():
response = {
'message': 'Hello from Flask!'
}
return jsonify(response)
if __name__ == '__main__':
app.run(debug=True)
Let us understand some of the important sections of the above script –
Function – login():

The login function retrieves a ‘username’ and ‘password’ from a JSON request and prints them. It checks if the provided credentials are missing from users or password lists, returning a failure JSON response if so. It creates and returns an access token in a JSON response if valid.
Function – get_chat():

The get_chat function retrieves the running session count and user input from a JSON request. Based on the session count, it extracts catalog data or processes the user’s message from the RAG framework that finally receives the refined response from the OpenAI, extracting hash values, image URLs, and wiki URLs. If an error arises, the function captures and returns the error as a JSON message.
Function – updateCounter():
The updateCounter function checks if a given CSV file exists and retrieves its counter value. It then increments the counter and writes it back to the CSV. If any errors occur, an error message is printed, and the function returns a value of 1.


Function – extractRemoveUrls():

The extractRemoveUrls function attempts to filter a data frame, resDf, based on a provided hash value to extract image and wiki URLs. If the data frame contains matching entries, it retrieves the corresponding URLs. Any errors encountered are printed, but the function always returns the image and wiki URLs, even if they are empty.
- clsContentScrapper.py (This is the main class that brings the default options for the users if they agree with the initial prompt by the bot.)
#####################################################
#### Written By: SATYAKI DE ####
#### Written On: 27-May-2023 ####
#### Modified On 28-May-2023 ####
#### ####
#### Objective: This is the main calling ####
#### python class that will invoke the ####
#### LangChain of package to extract ####
#### the transcript from the YouTube videos & ####
#### then answer the questions based on the ####
#### topics selected by the users. ####
#### ####
#####################################################
from langchain.document_loaders import YoutubeLoader
from langchain.text_splitter import RecursiveCharacterTextSplitter
from langchain.embeddings.openai import OpenAIEmbeddings
from langchain.vectorstores import FAISS
from langchain.chat_models import ChatOpenAI
from langchain.chains import LLMChain
from langchain.prompts.chat import (
ChatPromptTemplate,
SystemMessagePromptTemplate,
HumanMessagePromptTemplate,
)
from googleapiclient.discovery import build
import clsTemplate as ct
from clsConfigClient import clsConfigClient as cf
import os
from flask import jsonify
import requests
###############################################
### Global Section ###
###############################################
open_ai_Key = cf.conf['OPEN_AI_KEY']
os.environ["OPENAI_API_KEY"] = open_ai_Key
embeddings = OpenAIEmbeddings(openai_api_key=open_ai_Key)
YouTube_Key = cf.conf['YOUTUBE_KEY']
youtube = build('youtube', 'v3', developerKey=YouTube_Key)
# Disbling Warning
def warn(*args, **kwargs):
pass
import warnings
warnings.warn = warn
###############################################
### End of Global Section ###
###############################################
class clsContentScrapper:
def __init__(self):
self.model_name = cf.conf['MODEL_NAME']
self.temp_val = cf.conf['TEMP_VAL']
self.max_cnt = int(cf.conf['MAX_CNT'])
self.url = cf.conf['BASE_URL']
self.header_token = cf.conf['HEADER_TOKEN']
def extractCatalog(self):
try:
base_url = self.url
header_token = self.header_token
url = base_url + '/departments'
print('Full URL: ', str(url))
payload={}
headers = {'Cookie': header_token}
response = requests.request("GET", url, headers=headers, data=payload)
x = response.text
return x
except Exception as e:
discussedTopic = []
x = str(e)
print('Error: ', x)
return x
Let us understand the the core part that require from this class.
Function – extractCatalog():
The extractCatalog function uses specific headers to make a GET request to a constructed URL. The URL is derived by appending ‘/departments’ to a base_url, and a header token is used in the request headers. If successful, it returns the text of the response; if there’s an exception, it prints the error and returns the error message.
- clsRAGOpenAI.py (This is the main class that brings the RAG-enabled context that is fed to OpenAI for fine-tuned response with less cost.)
#########################################################
#### Written By: SATYAKI DE ####
#### Written On: 27-Jun-2023 ####
#### Modified On 28-Jun-2023 ####
#### ####
#### Objective: This is the main calling ####
#### python script that will invoke the ####
#### shortcut application created inside MAC ####
#### enviornment including MacBook, IPad or IPhone. ####
#### ####
#########################################################
from haystack.document_stores.faiss import FAISSDocumentStore
from haystack.nodes import DensePassageRetriever
import openai
from clsConfigClient import clsConfigClient as cf
import clsL as log
# Disbling Warning
def warn(*args, **kwargs):
pass
import warnings
warnings.warn = warn
import os
import re
###############################################
### Global Section ###
###############################################
Ind = cf.conf['DEBUG_IND']
queryModel = cf.conf['QUERY_MODEL']
passageModel = cf.conf['PASSAGE_MODEL']
#Initiating Logging Instances
clog = log.clsL()
os.environ["TOKENIZERS_PARALLELISM"] = "false"
vectorDBFileName = cf.conf['VECTORDB_FILE_NM']
indexFile = "vectorDB/" + str(vectorDBFileName) + '.faiss'
indexConfig = "vectorDB/" + str(vectorDBFileName) + ".json"
print('File: ', str(indexFile))
print('Config: ', str(indexConfig))
# Also, provide `config_path` parameter if you set it when calling the `save()` method:
new_document_store = FAISSDocumentStore.load(index_path=indexFile, config_path=indexConfig)
# Initialize Retriever
retriever = DensePassageRetriever(document_store=new_document_store,
query_embedding_model=queryModel,
passage_embedding_model=passageModel,
use_gpu=False)
###############################################
### End of Global Section ###
###############################################
class clsRAGOpenAI:
def __init__(self):
self.basePath = cf.conf['DATA_PATH']
self.fileName = cf.conf['FILE_NAME']
self.Ind = cf.conf['DEBUG_IND']
self.subdir = str(cf.conf['OUT_DIR'])
self.base_url = cf.conf['BASE_URL']
self.outputPath = cf.conf['OUTPUT_PATH']
self.vectorDBPath = cf.conf['VECTORDB_PATH']
self.openAIKey = cf.conf['OPEN_AI_KEY']
self.temp = cf.conf['TEMP_VAL']
self.modelName = cf.conf['MODEL_NAME']
self.maxToken = cf.conf['MAX_TOKEN']
def extractHash(self, text):
try:
# Regular expression pattern to match 'Ref: {' followed by a number and then '}'
pattern = r"Ref: \{'(\d+)'\}"
match = re.search(pattern, text)
if match:
return match.group(1)
else:
return None
except Exception as e:
x = str(e)
print('Error: ', x)
return None
def removeSentencesWithNaN(self, text):
try:
# Split text into sentences using regular expression
sentences = re.split('(?<!\w\.\w.)(?<![A-Z][a-z]\.)(?<=\.|\?)\s', text)
# Filter out sentences containing 'nan'
filteredSentences = [sentence for sentence in sentences if 'nan' not in sentence]
# Rejoin the sentences
return ' '.join(filteredSentences)
except Exception as e:
x = str(e)
print('Error: ', x)
return ''
def retrieveDocumentsReader(self, question, top_k=9):
return retriever.retrieve(question, top_k=top_k)
def generateAnswerWithGPT3(self, retrieved_docs, question):
try:
openai.api_key = self.openAIKey
temp = self.temp
modelName = self.modelName
maxToken = self.maxToken
documentsText = " ".join([doc.content for doc in retrieved_docs])
filteredDocs = self.removeSentencesWithNaN(documentsText)
hashValue = self.extractHash(filteredDocs)
print('RAG Docs:: ')
print(filteredDocs)
#prompt = f"Given the following documents: {documentsText}, answer the question accurately based on the above data with the supplied http urls: {question}"
# Set up a chat-style prompt with your data
messages = [
{"role": "system", "content": "You are a helpful assistant, answer the question accurately based on the above data with the supplied http urls. Only relevant content needs to publish. Please do not provide the facts or the texts that results crossing the max_token limits."},
{"role": "user", "content": filteredDocs}
]
# Chat style invoking the latest model
response = openai.ChatCompletion.create(
model=modelName,
messages=messages,
temperature = temp,
max_tokens=maxToken
)
return hashValue, response.choices[0].message['content'].strip().replace('\n','\\n')
except Exception as e:
x = str(e)
print('failed to get from OpenAI: ', x)
return 'Not Available!'
def ragAnswerWithHaystackAndGPT3(self, question):
retrievedDocs = self.retrieveDocumentsReader(question)
return self.generateAnswerWithGPT3(retrievedDocs, question)
def getData(self, strVal):
try:
print('*'*120)
print('Index Your Data for Retrieval:')
print('*'*120)
print('Response from New Docs: ')
print()
hashValue, answer = self.ragAnswerWithHaystackAndGPT3(strVal)
print('GPT3 Answer::')
print(answer)
print('Hash Value:')
print(str(hashValue))
print('*'*240)
print('End Of Use RAG to Generate Answers:')
print('*'*240)
return hashValue, answer
except Exception as e:
x = str(e)
print('Error: ', x)
answer = x
hashValue = 1
return hashValue, answer
Let us understand some of the important block –
Function – ragAnswerWithHaystackAndGPT3():
The ragAnswerWithHaystackAndGPT3 function retrieves relevant documents for a given question using the retrieveDocumentsReader method. It then generates an answer for the query using GPT-3 with the retrieved documents via the generateAnswerWithGPT3 method. The final response is returned.
Function – generateAnswerWithGPT3():
The generateAnswerWithGPT3 function, given a list of retrieved documents and a question, communicates with OpenAI’s GPT-3 to generate an answer. It first processes the documents, filtering and extracting a hash value. Using a chat-style format, it prompts GPT-3 with the processed documents and captures its response. If an error occurs, an error message is printed, and “Not Available!” is returned.
Function – retrieveDocumentsReader():
The retrieveDocumentsReader function takes in a question and an optional parameter, top_k (defaulted to 9). It is called the retriever.retrieve method with the given parameters. The result of the retrieval will generate at max nine responses from the RAG engine, which will be fed to OpenAI.
React:
- App.js (This is the main react script, that will create the interface & parse the data apart from the authentication)
// App.js
import React, { useState } from 'react';
import axios from 'axios';
import './App.css';
const App = () => {
const [isLoggedIn, setIsLoggedIn] = useState(false);
const [username, setUsername] = useState('');
const [password, setPassword] = useState('');
const [message, setMessage] = useState('');
const [chatLog, setChatLog] = useState([{ sender: 'MuBot', message: 'Welcome to MuBot! Please explore the world of History from our brilliant collections! Do you want to proceed to see the catalog?'}]);
const handleLogin = async (e) => {
e.preventDefault();
try {
const response = await axios.post('http://localhost:5000/login', { username, password });
if (response.status === 200) {
setIsLoggedIn(true);
}
} catch (error) {
console.error('Login error:', error);
}
};
const sendMessage = async (username) => {
if (message.trim() === '') return;
// Create a new chat entry
const newChatEntry = {
sender: 'user',
message: message.trim(),
};
// Clear the input field
setMessage('');
try {
// Make API request to Python-based API
const response = await axios.post('http://localhost:5000/chat', { message: newChatEntry.message }); // Replace with your API endpoint URL
const responseData = response.data;
// Print the response to the console for debugging
console.log('API Response:', responseData);
// Parse the nested JSON from the 'message' attribute
const jsonData = JSON.parse(responseData.message);
// Check if the data contains 'departments'
if (jsonData.departments) {
// Extract the 'departments' attribute from the parsed data
const departments = jsonData.departments;
// Extract the department names and create a single string with line breaks
const botResponseText = departments.reduce((acc, department) => {return acc + department.departmentId + ' ' + department.displayName + '\n';}, '');
// Update the chat log with the bot's response
setChatLog((prevChatLog) => [...prevChatLog, { sender: 'user', message: message }, { sender: 'bot', message: botResponseText },]);
}
else if (jsonData.records)
{
// Data structure 2: Artwork information
const records = jsonData.records;
// Prepare chat entries
const chatEntries = [];
// Iterate through records and extract text, image, and wiki information
records.forEach((record) => {
const textInfo = Object.entries(record).map(([key, value]) => {
if (key !== 'Image' && key !== 'Wiki') {
return `${key}: ${value}`;
}
return null;
}).filter((info) => info !== null).join('\n');
const imageLink = record.Image;
//const wikiLinks = JSON.parse(record.Wiki.replace(/'/g, '"'));
//const wikiLinks = record.Wiki;
const wikiLinks = record.Wiki.split(',').map(link => link.trim());
console.log('Wiki:', wikiLinks);
// Check if there is a valid image link
const hasValidImage = imageLink && imageLink !== '[]';
const imageElement = hasValidImage ? (
<img src={imageLink} alt="Artwork" style={{ maxWidth: '100%' }} />
) : null;
// Create JSX elements for rendering the wiki links (if available)
const wikiElements = wikiLinks.map((link, index) => (
<div key={index}>
<a href={link} target="_blank" rel="noopener noreferrer">
Wiki Link {index + 1}
</a>
</div>
));
if (textInfo) {
chatEntries.push({ sender: 'bot', message: textInfo });
}
if (imageElement) {
chatEntries.push({ sender: 'bot', message: imageElement });
}
if (wikiElements.length > 0) {
chatEntries.push({ sender: 'bot', message: wikiElements });
}
});
// Update the chat log with the bot's response
setChatLog((prevChatLog) => [...prevChatLog, { sender: 'user', message }, ...chatEntries, ]);
}
} catch (error) {
console.error('Error sending message:', error);
}
};
if (!isLoggedIn) {
return (
<div className="login-container">
<h2>Welcome to the MuBot</h2>
<form onSubmit={handleLogin} className="login-form">
<input
type="text"
placeholder="Enter your name"
value={username}
onChange={(e) => setUsername(e.target.value)}
required
/>
<input
type="password"
placeholder="Enter your password"
value={password}
onChange={(e) => setPassword(e.target.value)}
required
/>
<button type="submit">Login</button>
</form>
</div>
);
}
return (
<div className="chat-container">
<div className="chat-header">
<h2>Hello, {username}</h2>
<h3>Chat with MuBot</h3>
</div>
<div className="chat-log">
{chatLog.map((chatEntry, index) => (
<div
key={index}
className={`chat-entry ${chatEntry.sender === 'user' ? 'user' : 'bot'}`}
>
<span className="user-name">{chatEntry.sender === 'user' ? username : 'MuBot'}</span>
<p className="chat-message">{chatEntry.message}</p>
</div>
))}
</div>
<div className="chat-input">
<input
type="text"
placeholder="Type your message..."
value={message}
onChange={(e) => setMessage(e.target.value)}
onKeyPress={(e) => {
if (e.key === 'Enter') {
sendMessage();
}
}}
/>
<button onClick={sendMessage}>Send</button>
</div>
</div>
);
};
export default App;
Please find some of the important logic –
Function – handleLogin():
The handleLogin asynchronous function responds to an event by preventing its default action. It attempts to post a login request with a username and password to a local server endpoint. If the response is successful with a status of 200, it updates a state variable to indicate a successful login; otherwise, it logs any encountered errors.
Function – sendMessage():
The sendMessage asynchronous function is designed to handle the user’s chat interaction:
- If the message is empty (after trimming spaces), the function exits without further action.
- A chat entry object is created with the sender set as ‘user’ and the trimmed message.
- The input field’s message is cleared, and an API request is made to a local server endpoint with the chat message.
- If the API responds with a ‘departments’ attribute in its JSON, a bot response is crafted by iterating over department details.
- If the API responds with ‘records’ indicating artwork information, the bot crafts responses for each record, extracting text, images, and wiki links, and generating JSX elements for rendering them.
- After processing the API response, the chat log state is updated with the user’s original message and the bot’s responses.
- Errors, if encountered, are logged to the console.
This function enables interactive chat with bot responses that vary based on the nature of the data received from the API.
DIRECTORY STRUCTURES:
Let us explore the directory structure starting from the parent to some of the important child folder should look like this –



So, finally, we’ve done it.
I know that this post is relatively bigger than my earlier post. But, I think, you can get all the details once you go through it.
You will get the complete codebase in the following GitHub link.
I’ll bring some more exciting topics in the coming days from the Python verse. Please share & subscribe to my post & let me know your feedback.
Till then, Happy Avenging! 🙂
Note: All the data & scenarios posted here are representational data & scenarios & available over the internet & for educational purposes only. Some of the images (except my photo) we’ve used are available over the net. We don’t claim ownership of these images. There is always room for improvement & especially in the prediction quality.






























































































You must be logged in to post a comment.