
Hi Guys,
Today, I’ll demonstrate one of the fascinating ways to capture real-time streaming data in a dashboard. It is a dream for any developer who wants to build an application involving streaming data, API & a dashboard.
Why don’t we see our run to make this thread more interesting?

Today, I’ll be using the two most essential services to achieve that goal.
Ably
H2O-Wave
Let’s discuss brief about these two services.
- Why I used “Ably” here?
One of my scenarios is to consume real-time currency data. Even after checking paid-API, I was not getting what I was looking for. Hence, I decided to use any service, which can mimics & publish my data as streaming data through a channel. Once published, I’ll consume the posted data into my application to create this new dashboard.
Using Ably, you can leverage their cloud platform to publish & consume data with the free developer account, which is sufficient for anyone.
To better understand this, we need to understand the basic concept of “pubsub”. Here is the important page from their side that I would like to embed for your reference –

To know more about this, please refer to the following link.
- Why I used “H2O-Wave” here?
Wave_H2O is a relatively brand new framework with some outstanding capabilities to visualize your data using native Python.
- Pre-Steps:
We need to register Ably. Some of the useful screen that we should explore more –

Successful creation of an App will generate the API-Key. Make sure that you note-down the channel details as well.

The above page will capture the details of usage. Since this is a free subscription, you will be blocked once you consume your limit. However, for paid users, this is one of the vital pages to control their budget.

Like any other cloud service, you can check your message published or consumptions here on this page.
This is the main landing page for H2O-Wave –

They have a quite many example snippet. However, these samples contain random data. Hence, these are relatively easier to implement. It would take quite some effort to tailor it for your need to implement that for real-life scenarios.
Some of the important links are as follows –
You need to install the following libraries in Python –
pip install ably
pip install h2o-waveWe’ve two scripts. We’re not going to discuss the publish streaming data script over here. We’ll be discussing only the consumption script, which will generate the dashboard as well. If you need, you can post your message. I’ll provide it.
1. dashboard_st.py ( This native Python script will consume streaming data & create live dashboard. )
##########################################################
#### Template Written By: H2O Wave ####
#### Enhanced with Streaming Data By: Satyaki De ####
#### Base Version Enhancement On: 20-Dec-2020 ####
#### Modified On 26-Dec-2020 ####
#### ####
#### Objective: This script will consume real-time ####
#### streaming data coming out from a hosted API ####
#### sources using another popular third-party ####
#### service named Ably. Ably mimics pubsub Streaming ####
#### concept, which might be extremely useful for ####
#### any start-ups. ####
##########################################################
import time
from h2o_wave import site, data, ui
from ably import AblyRest
import pandas as p
import json
class DaSeries:
def __init__(self, inputDf):
self.Df = inputDf
self.count_row = inputDf.shape[0]
self.start_pos = 0
self.end_pos = 0
self.interval = 1
def next(self):
try:
# Getting Individual Element & convert them to Series
if ((self.start_pos + self.interval) <= self.count_row):
self.end_pos = self.start_pos + self.interval
else:
self.end_pos = self.start_pos + (self.count_row - self.start_pos)
split_df = self.Df.iloc[self.start_pos:self.end_pos]
if ((self.start_pos > self.count_row) | (self.start_pos == self.count_row)):
pass
else:
self.start_pos = self.start_pos + self.interval
x = float(split_df.iloc[0]['CurrentExchange'])
dx = float(split_df.iloc[0]['Change'])
# Emptying the exisitng dataframe
split_df = p.DataFrame(None)
return x, dx
except:
x = 0
dx = 0
return x, dx
class CategoricalSeries:
def __init__(self, sourceDf):
self.series = DaSeries(sourceDf)
self.i = 0
def next(self):
x, dx = self.series.next()
self.i += 1
return f'C{self.i}', x, dx
light_theme_colors = '$red $pink $purple $violet $indigo $blue $azure $cyan $teal $mint $green $amber $orange $tangerine'.split()
dark_theme_colors = '$red $pink $blue $azure $cyan $teal $mint $green $lime $yellow $amber $orange $tangerine'.split()
_color_index = -1
colors = dark_theme_colors
def next_color():
global _color_index
_color_index += 1
return colors[_color_index % len(colors)]
_curve_index = -1
curves = 'linear smooth step stepAfter stepBefore'.split()
def next_curve():
global _curve_index
_curve_index += 1
return curves[_curve_index % len(curves)]
def create_dashboard(update_freq=0.0):
page = site['/dashboard_st']
# Fetching the data
client = AblyRest('XXXXX.YYYYYY:94384jjdhdh98kiidLO')
channel = client.channels.get('sd_channel')
message_page = channel.history()
# Counter Value
cnt = 0
# Declaring Global Data-Frame
df_conv = p.DataFrame()
for i in message_page.items:
print('Last Msg: {}'.format(i.data))
json_data = json.loads(i.data)
# Converting JSON to Dataframe
df = p.json_normalize(json_data)
df.columns = df.columns.map(lambda x: x.split(".")[-1])
if cnt == 0:
df_conv = df
else:
d_frames = [df_conv, df]
df_conv = p.concat(d_frames)
cnt += 1
# Resetting the Index Value
df_conv.reset_index(drop=True, inplace=True)
print('DF:')
print(df_conv)
df_conv['default_rank'] = df_conv.groupby(['Currency']).cumcount() + 1
lkp_rank = 1
df_unique = df_conv[(df_conv['default_rank'] == lkp_rank)]
print('Rank DF Unique:')
print(df_unique)
count_row = df_unique.shape[0]
large_lines = []
start_pos = 0
end_pos = 0
interval = 1
# Converting dataframe to a desired Series
f = CategoricalSeries(df_conv)
for j in range(count_row):
# Getting the series values from above
cat, val, pc = f.next()
# Getting Individual Element & convert them to Series
if ((start_pos + interval) <= count_row):
end_pos = start_pos + interval
else:
end_pos = start_pos + (count_row - start_pos)
split_df = df_unique.iloc[start_pos:end_pos]
if ((start_pos > count_row) | (start_pos == count_row)):
pass
else:
start_pos = start_pos + interval
x_currency = str(split_df.iloc[0]['Currency'])
c = page.add(f'e{j+1}', ui.tall_series_stat_card(
box=f'{j+1} 1 1 2',
title=x_currency,
value='=${{intl qux minimum_fraction_digits=2 maximum_fraction_digits=2}}',
aux_value='={{intl quux style="percent" minimum_fraction_digits=1 maximum_fraction_digits=1}}',
data=dict(qux=val, quux=pc),
plot_type='area',
plot_category='foo',
plot_value='qux',
plot_color=next_color(),
plot_data=data('foo qux', -15),
plot_zero_value=0,
plot_curve=next_curve(),
))
large_lines.append((f, c))
page.save()
while update_freq > 0:
time.sleep(update_freq)
for f, c in large_lines:
cat, val, pc = f.next()
c.data.qux = val
c.data.quux = pc / 100
c.plot_data[-1] = [cat, val]
page.save()
create_dashboard(update_freq=0.25)
Some of the key snippets from the above codes are –
class DaSeries:
def __init__(self, inputDf):
self.Df = inputDf
self.count_row = inputDf.shape[0]
self.start_pos = 0
self.end_pos = 0
self.interval = 1
def next(self):
try:
# Getting Individual Element & convert them to Series
if ((self.start_pos + self.interval) <= self.count_row):
self.end_pos = self.start_pos + self.interval
else:
self.end_pos = self.start_pos + (self.count_row - self.start_pos)
split_df = self.Df.iloc[self.start_pos:self.end_pos]
if ((self.start_pos > self.count_row) | (self.start_pos == self.count_row)):
pass
else:
self.start_pos = self.start_pos + self.interval
x = float(split_df.iloc[0]['CurrentExchange'])
dx = float(split_df.iloc[0]['Change'])
# Emptying the exisitng dataframe
split_df = p.DataFrame(None)
return x, dx
except:
x = 0
dx = 0
return x, dx
class CategoricalSeries:
def __init__(self, sourceDf):
self.series = DaSeries(sourceDf)
self.i = 0
def next(self):
x, dx = self.series.next()
self.i += 1
return f'C{self.i}', x, dx
The above snippet will create a series of data out of a pandas data frame. It will consume, one-by-one record & then pass it to the dashboard for real-time updates.
# Fetching the data
client = AblyRest('XXXXX.YYYYYY:94384jjdhdh98kiidLO')
channel = client.channels.get('sd_channel')
message_page = channel.history()
In the above code, the application will consume the real-time data out of Ably’s channel.
df_conv['default_rank'] = df_conv.groupby(['Currency']).cumcount() + 1 lkp_rank = 1 df_unique = df_conv[(df_conv['default_rank'] == lkp_rank)]
In the above code, the application is uniquely identifying the first instance of currency entries, which will be passed to the initial dashboard page before consuming the array of updates.
f = CategoricalSeries(df_conv)
In the above code, the application is creating an instance of the intended categorical series.
c = page.add(f'e{j+1}', ui.tall_series_stat_card(
box=f'{j+1} 1 1 2',
title=x_currency,
value='=${{intl qux minimum_fraction_digits=2 maximum_fraction_digits=2}}',
aux_value='={{intl quux style="percent" minimum_fraction_digits=1 maximum_fraction_digits=1}}',
data=dict(qux=val, quux=pc),
plot_type='area',
plot_category='foo',
plot_value='qux',
plot_color=next_color(),
plot_data=data('foo qux', -15),
plot_zero_value=0,
plot_curve=next_curve(),
))
large_lines.append((f, c))
page.save()
The above code is a standard way to bind the streaming data with the H2O-Wave dashboard.
while update_freq > 0:
time.sleep(update_freq)
for f, c in large_lines:
cat, val, pc = f.next()
c.data.qux = val
c.data.quux = pc / 100
c.plot_data[-1] = [cat, val]
page.save()
Here are the last few snippet lines that will capture the continuous streaming data & keep updating the numbers on your dashboard.
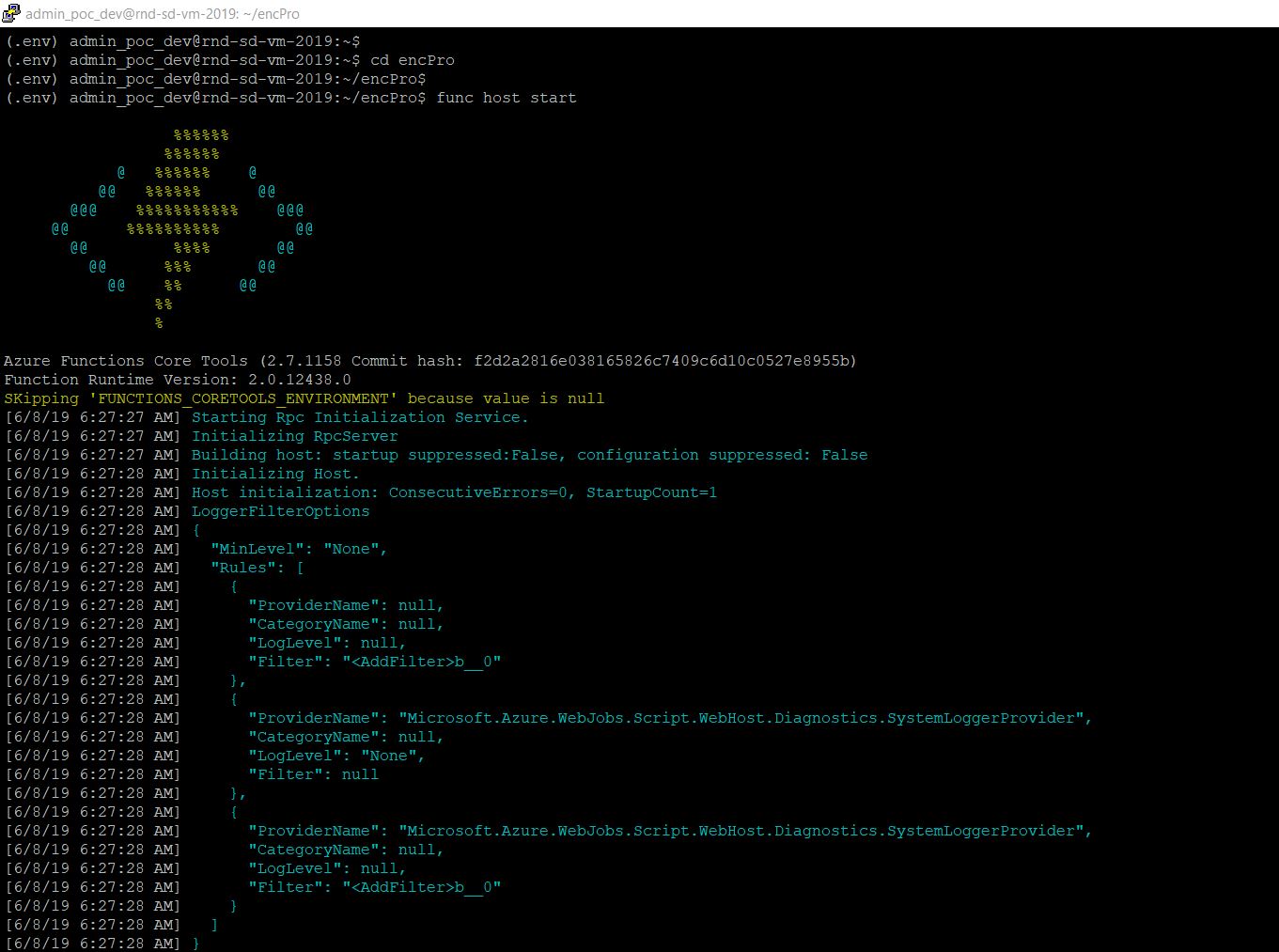
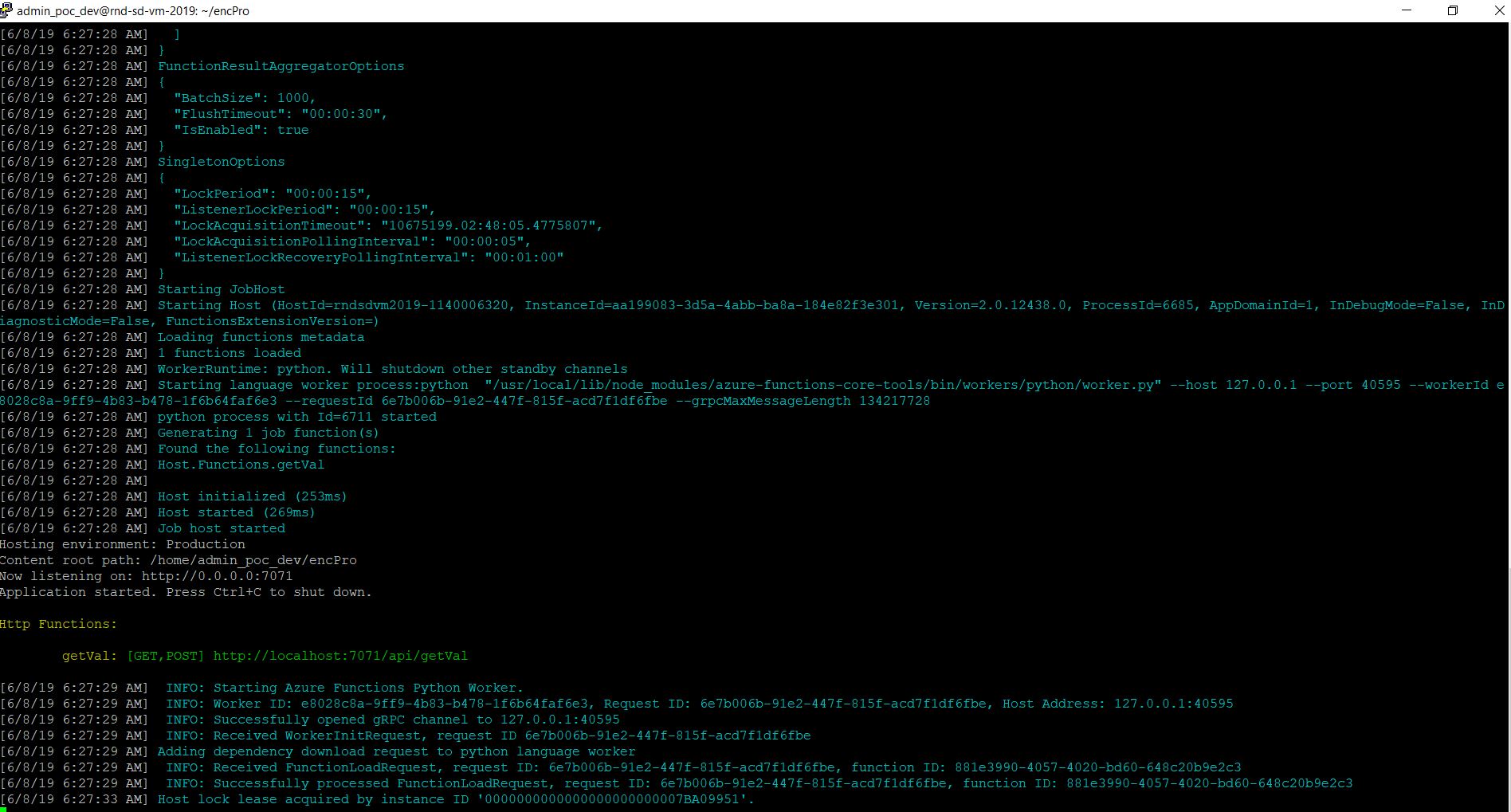
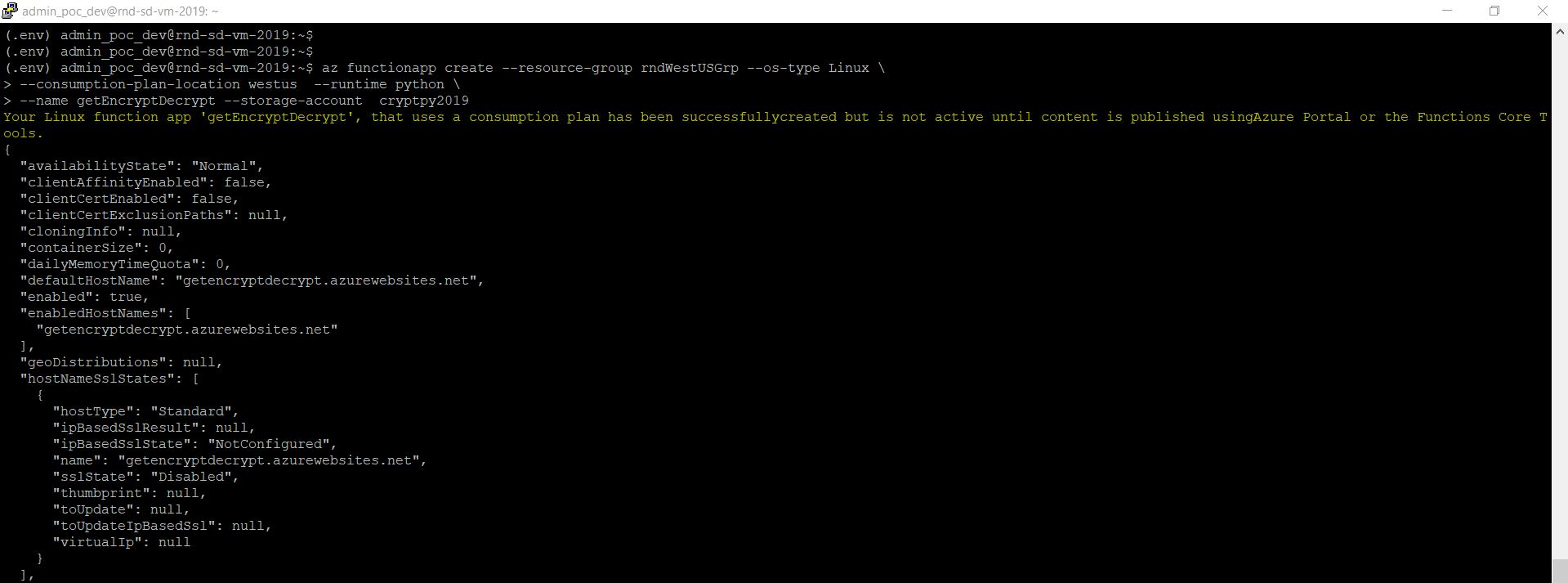
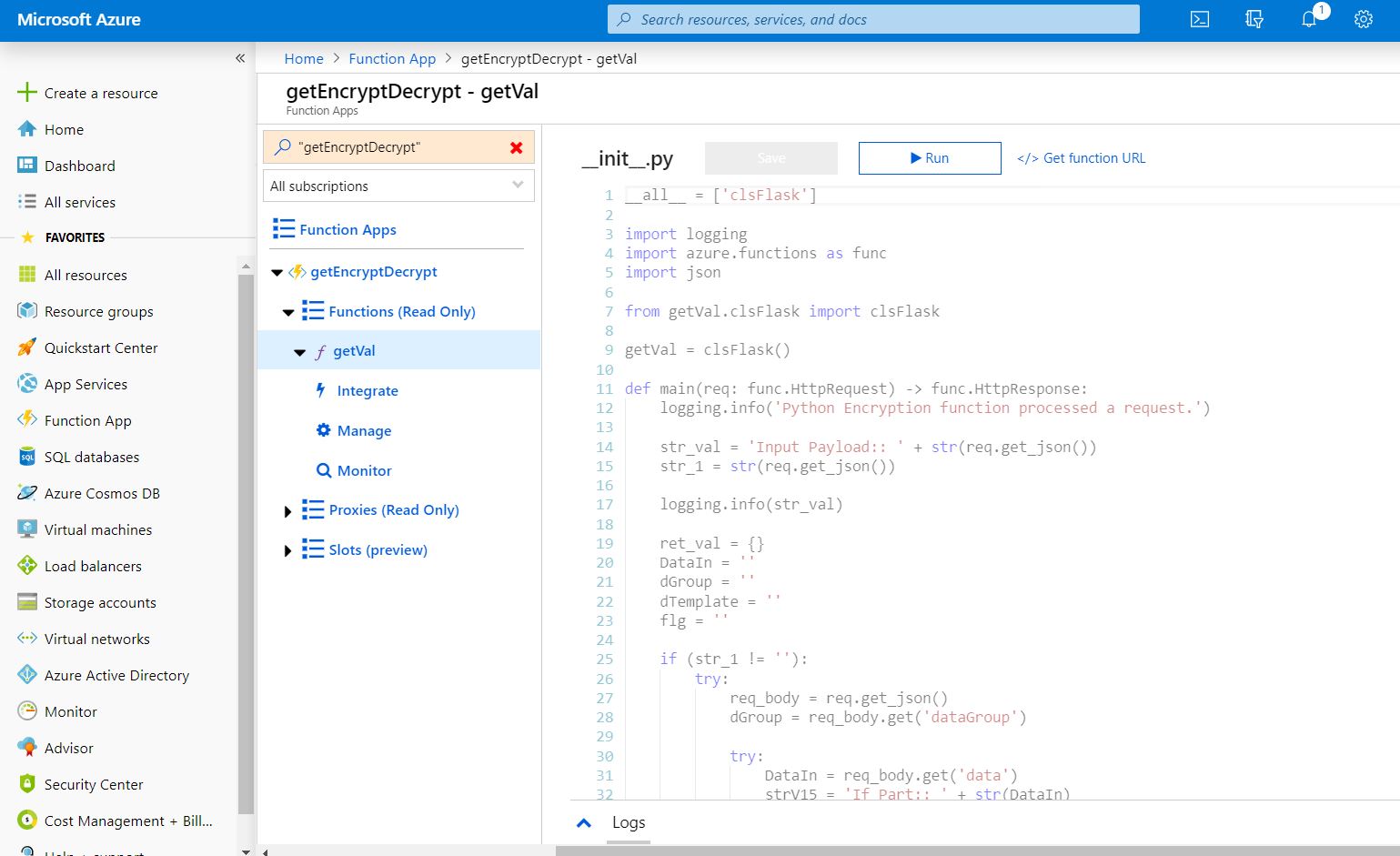
Since I’ve already provided the run video of my application, here are a few important screens –
Case 1:

Case 2:

Case 3:

Case 4:

So, finally, we have done it.
You will get the complete codebase in the following Github link.
I’ll bring some more exciting topic in the coming days from the Python verse.
Till then, Happy Avenging! 😀
Note: All the data & scenario posted here are representational data & scenarios & available over the internet & for educational purpose only.
































































































You must be logged in to post a comment.