Today, we’ll be discussing a new cross-over between API, JSON, Encryption along with data distribution through Queue.
The primary objective here is to distribute one csv file through API service & access our previously deployed Encryption/Decryption methods by accessing the parallel call through Queue. In this case, our primary objective is to allow asynchronous calls to Queue for data distributions & at this point we’re not really looking for performance improvement. Instead, our goal to achieve the target.
My upcoming posts will discuss the improvement of performance using Parallel calls.
Let’s discuss it now.
Please find the structure of our Windows & MAC directory are as follows –

We’re not going to discuss any scripts, which we’ve already discussed in my previous posts. Please refer the relevant earlier posts from my blogs.
1. clsL.py (This script will create the split csv files or final merge file after the corresponding process. However, this can be used as usual verbose debug logging as well. Hence, the name comes into the picture.)
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
|
###########################################
#### Written By: SATYAKI DE ########
#### Written On: 25-Jan-2019 ########
#### ########
#### Objective: Log File ########
###########################################
import pandas as p
import platform as pl
from clsParam import clsParam as cf
class clsL(object):
def __init__(self):
self.path = cf.config['PATH']
def logr(self, Filename, Ind, df, subdir=None):
try:
x = p.DataFrame()
x = df
sd = subdir
os_det = pl.system()
if sd == None:
if os_det == "Windows":
fullFileName = self.path + '\\' + Filename
else:
fullFileName = self.path + '/' + Filename
else:
if os_det == "Windows":
fullFileName = self.path + '\\' + sd + "\\" + Filename
else:
fullFileName = self.path + '/' + sd + "/" + Filename
if Ind == 'Y':
x.to_csv(fullFileName, index=False)
return 0
except Exception as e:
y = str(e)
print(y)
return 3
|
2. callRunServer.py (This script will create an instance of a server. Once, it is running – it will emulate the Server API functionalities. Hence, the name comes into the picture.)
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
|
############################################
#### Written By: SATYAKI DE ####
#### Written On: 10-Feb-2019 ####
#### Package Flask package needs to ####
#### install in order to run this ####
#### script. ####
#### ####
#### Objective: This script will ####
#### initiate the encrypt/decrypt class ####
#### based on client supplied data. ####
#### Also, this will create an instance ####
#### of the server & create an endpoint ####
#### or API using flask framework. ####
############################################
from flask import Flask
from flask import jsonify
from flask import request
from flask import abort
from clsConfigServer import clsConfigServer as csf
import clsFlask as clf
app = Flask(__name__)
@app.route('/process/getEncrypt', methods=['POST'])
def getEncrypt():
try:
# If the server application doesn't have
# valid json, it will throw 400 error
if not request.get_json:
abort(400)
# Capturing the individual element
content = request.get_json()
dGroup = content['dataGroup']
input_data = content['data']
dTemplate = content['dataTemplate']
# For debug purpose only
print("-" * 157)
print("Group: ", dGroup)
print("Data: ", input_data)
print("Template: ", dTemplate)
print("-" * 157)
ret_val = ''
if ((dGroup != '') & (dTemplate != '')):
y = clf.clsFlask()
ret_val = y.getEncryptProcess(dGroup, input_data, dTemplate)
else:
abort(500)
return jsonify({'status': 'success', 'encrypt_val': ret_val})
except Exception as e:
x = str(e)
return jsonify({'status': 'error', 'detail': x})
@app.route('/process/getDecrypt', methods=['POST'])
def getDecrypt():
try:
# If the server application doesn't have
# valid json, it will throw 400 error
if not request.get_json:
abort(400)
# Capturing the individual element
content = request.get_json()
dGroup = content['dataGroup']
input_data = content['data']
dTemplate = content['dataTemplate']
# For debug purpose only
print("-" * 157)
print("Group: ", dGroup)
print("Data: ", input_data)
print("Template: ", dTemplate)
print("-" * 157)
ret_val = ''
if ((dGroup != '') & (dTemplate != '')):
y = clf.clsFlask()
ret_val = y.getDecryptProcess(dGroup, input_data, dTemplate)
else:
abort(500)
return jsonify({'status': 'success', 'decrypt_val': ret_val})
except Exception as e:
x = str(e)
return jsonify({'status': 'error', 'detail': x})
def main():
try:
print('Starting Encrypt/Decrypt Application!')
# Calling Server Start-Up Script
app.run(debug=True, host=str(csf.config['HOST_IP_ADDR']))
ret_val = 0
if ret_val == 0:
print("Finished Returning Message!")
else:
raise IOError
except Exception as e:
print("Server Failed To Start!")
if __name__ == '__main__':
main()
|
3. clsFlask.py (This script is part of the server process, which will categorize the encryption logic based on different groups. Hence, the name comes into the picture.)
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
|
###########################################
#### Written By: SATYAKI DE ####
#### Written On: 25-Jan-2019 ####
#### Package Flask package needs to ####
#### install in order to run this ####
#### script. ####
#### ####
#### Objective: This script will ####
#### encrypt/decrypt based on the ####
#### supplied salt value. Also, ####
#### this will capture the individual ####
#### element & stored them into JSON ####
#### variables using flask framework. ####
###########################################
from clsConfigServer import clsConfigServer as csf
import clsEnDecAuth as cen
class clsFlask(object):
def __init__(self):
self.xtoken = str(csf.config['DEF_SALT'])
def getEncryptProcess(self, dGroup, input_data, dTemplate):
try:
# It is sending default salt value
xtoken = self.xtoken
# Capturing the individual element
dGroup = dGroup
input_data = input_data
dTemplate = dTemplate
# This will check the mandatory json elements
if ((dGroup != '') & (dTemplate != '')):
# Based on the Group & Element it will fetch the salt
# Based on the specific salt it will encrypt the data
if ((dGroup == 'GrDet') & (dTemplate == 'subGrAcct_Nbr')):
xtoken = str(csf.config['ACCT_NBR_SALT'])
print("xtoken: ", xtoken)
print("Flask Input Data: ", input_data)
x = cen.clsEnDec(xtoken)
ret_val = x.encrypt_str(input_data)
elif ((dGroup == 'GrDet') & (dTemplate == 'subGrName')):
xtoken = str(csf.config['NAME_SALT'])
print("xtoken: ", xtoken)
print("Flask Input Data: ", input_data)
x = cen.clsEnDec(xtoken)
ret_val = x.encrypt_str(input_data)
elif ((dGroup == 'GrDet') & (dTemplate == 'subGrPhone')):
xtoken = str(csf.config['PHONE_SALT'])
print("xtoken: ", xtoken)
print("Flask Input Data: ", input_data)
x = cen.clsEnDec(xtoken)
ret_val = x.encrypt_str(input_data)
elif ((dGroup == 'GrDet') & (dTemplate == 'subGrEmail')):
xtoken = str(csf.config['EMAIL_SALT'])
print("xtoken: ", xtoken)
print("Flask Input Data: ", input_data)
x = cen.clsEnDec(xtoken)
ret_val = x.encrypt_str(input_data)
else:
ret_val = ''
else:
ret_val = ''
# Return value
return ret_val
except Exception as e:
ret_val = ''
# Return the valid json Error Response
return ret_val
def getDecryptProcess(self, dGroup, input_data, dTemplate):
try:
xtoken = self.xtoken
# Capturing the individual element
dGroup = dGroup
input_data = input_data
dTemplate = dTemplate
# This will check the mandatory json elements
if ((dGroup != '') & (dTemplate != '')):
# Based on the Group & Element it will fetch the salt
# Based on the specific salt it will decrypt the data
if ((dGroup == 'GrDet') & (dTemplate == 'subGrAcct_Nbr')):
xtoken = str(csf.config['ACCT_NBR_SALT'])
print("xtoken: ", xtoken)
print("Flask Input Data: ", input_data)
x = cen.clsEnDec(xtoken)
ret_val = x.decrypt_str(input_data)
elif ((dGroup == 'GrDet') & (dTemplate == 'subGrName')):
xtoken = str(csf.config['NAME_SALT'])
print("xtoken: ", xtoken)
print("Flask Input Data: ", input_data)
x = cen.clsEnDec(xtoken)
ret_val = x.decrypt_str(input_data)
elif ((dGroup == 'GrDet') & (dTemplate == 'subGrPhone')):
xtoken = str(csf.config['PHONE_SALT'])
print("xtoken: ", xtoken)
print("Flask Input Data: ", input_data)
x = cen.clsEnDec(xtoken)
ret_val = x.decrypt_str(input_data)
elif ((dGroup == 'GrDet') & (dTemplate == 'subGrEmail')):
xtoken = str(csf.config['EMAIL_SALT'])
print("xtoken: ", xtoken)
print("Flask Input Data: ", input_data)
x = cen.clsEnDec(xtoken)
ret_val = x.decrypt_str(input_data)
else:
ret_val = ''
else:
ret_val = ''
# Return value
return ret_val
except Exception as e:
ret_val = ''
# Return the valid Error Response
return ret_val
|
4. clsEnDec.py (This script will convert the string to encryption or decryption from its previous states based on the supplied group. Hence, the name comes into the picture.)
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
|
###########################################
#### Written By: SATYAKI DE ########
#### Written On: 25-Jan-2019 ########
#### Package Cryptography needs to ########
#### install in order to run this ########
#### script. ########
#### ########
#### Objective: This script will ########
#### encrypt/decrypt based on the ########
#### hidden supplied salt value. ########
###########################################
from cryptography.fernet import Fernet
class clsEnDec(object):
def __init__(self, token):
# Calculating Key
self.token = token
def encrypt_str(self, data):
try:
# Capturing the Salt Information
salt = self.token
# Checking Individual Types inside the Dataframe
cipher = Fernet(salt)
encr_val = str(cipher.encrypt(bytes(data,'utf8'))).replace("b'","").replace("'","")
return encr_val
except Exception as e:
x = str(e)
print(x)
encr_val = ''
return encr_val
def decrypt_str(self, data):
try:
# Capturing the Salt Information
salt = self.token
# Checking Individual Types inside the Dataframe
cipher = Fernet(salt)
decr_val = str(cipher.decrypt(bytes(data,'utf8'))).replace("b'","").replace("'","")
return decr_val
except Exception as e:
x = str(e)
print(x)
decr_val = ''
return decr_val
|
5. clsConfigServer.py (This script contains all the main parameter details of your emulated API server. Hence, the name comes into the picture.)
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
|
###########################################
#### Written By: SATYAKI DE ########
#### Written On: 10-Feb-2019 ########
#### ########
#### Objective: Parameter File ########
###########################################
import os
import platform as pl
# Checking with O/S system
os_det = pl.system()
class clsConfigServer(object):
Curr_Path = os.path.dirname(os.path.realpath(__file__))
if os_det == "Windows":
config = {
'FILE': 'acct_addr_20180112.csv',
'SRC_FILE_PATH': Curr_Path + '\\' + 'src_file\\',
'PROFILE_FILE_PATH': Curr_Path + '\\' + 'profile\\',
'HOST_IP_ADDR': '0.0.0.0',
'DEF_SALT': 'iooquzKtqLwUwXG3rModqj_fIl409vemWg9PekcKh2o=',
'ACCT_NBR_SALT': 'iooquzKtqLwUwXG3rModqj_fIlpp1vemWg9PekcKh2o=',
'NAME_SALT': 'iooquzKtqLwUwXG3rModqj_fIlpp1026Wg9PekcKh2o=',
'PHONE_SALT': 'iooquzKtqLwUwXG3rMM0F5_fIlpp1026Wg9PekcKh2o=',
'EMAIL_SALT': 'iooquzKtqLwU0653rMM0F5_fIlpp1026Wg9PekcKh2o='
}
else:
config = {
'FILE': 'acct_addr_20180112.csv',
'SRC_FILE_PATH': Curr_Path + '/' + 'src_file/',
'PROFILE_FILE_PATH': Curr_Path + '/' + 'profile/',
'HOST_IP_ADDR': '0.0.0.0',
'DEF_SALT': 'iooquzKtqLwUwXG3rModqj_fIl409vemWg9PekcKh2o=',
'ACCT_NBR_SALT': 'iooquzKtqLwUwXG3rModqj_fIlpp1vemWg9PekcKh2o=',
'NAME_SALT': 'iooquzKtqLwUwXG3rModqj_fIlpp1026Wg9PekcKh2o=',
'PHONE_SALT': 'iooquzKtqLwUwXG3rMM0F5_fIlpp1026Wg9PekcKh2o=',
'EMAIL_SALT': 'iooquzKtqLwU0653rMM0F5_fIlpp1026Wg9PekcKh2o='
}
|
6. clsWeb.py (This script will receive the input Pandas dataframe & then convert it to JSON & then send it back to our Flask API Server for encryption/decryption. Hence, the name comes into the picture.)
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
|
############################################
#### Written By: SATYAKI DE ####
#### Written On: 09-Mar-2019 ####
#### Package Flask package needs to ####
#### install in order to run this ####
#### script. ####
#### ####
#### Objective: This script will ####
#### initiate API based JSON requests ####
#### at the server & receive the ####
#### response from it & transform it ####
#### back to the data-frame. ####
############################################
import json
import requests
import datetime
import time
import ssl
import os
from clsParam import clsParam as cf
class clsWeb(object):
def __init__(self, payload):
self.payload = payload
self.path = str(cf.config['PATH'])
self.max_retries = int(cf.config['MAX_RETRY'])
self.encrypt_ulr = str(cf.config['ENCRYPT_URL'])
self.decrypt_ulr = str(cf.config['DECRYPT_URL'])
def getResponse(self, mode):
# Assigning Logging Info
max_retries = self.max_retries
encrypt_ulr = self.encrypt_ulr
decrypt_ulr = self.decrypt_ulr
En_Dec_Mode = mode
try:
# Bypassing SSL Authentication
try:
_create_unverified_https_context = ssl._create_unverified_context
except AttributeError:
# Legacy python that doesn't verify HTTPS certificates by default
pass
else:
# Handle target environment that doesn't support HTTPS verification
ssl._create_default_https_context = _create_unverified_https_context
# Providing the url
if En_Dec_Mode == 'En':
url = encrypt_ulr
else:
url = decrypt_ulr
print("URL::", url)
# Capturing the payload
data = self.payload
# Converting String to Json
# json_data = json.loads(data)
json_data = json.loads(data)
print("JSON:::::::", str(json_data))
headers = {"Content-type": "application/json"}
param = headers
var1 = datetime.datetime.now().strftime("%H:%M:%S")
print('Json Fetch Start Time:', var1)
retries = 1
success = False
while not success:
# Getting response from web service
# response = requests.post(url, params=param, json=data, auth=(login, password), verify=False)
response = requests.post(url, params=param, json=json_data, verify=False)
print("Complete Return Code:: ", str(response.status_code))
print("Return Code Initial::", str(response.status_code)[:1])
if str(response.status_code)[:1] == '2':
# response = s.post(url, params=param, json=json_data, verify=False)
success = True
else:
wait = retries * 2
print("Retry fails! Waiting " + str(wait) + " seconds and retrying.")
time.sleep(wait)
retries += 1
# print('Return Service::')
# Checking Maximum Retries
if retries == max_retries:
success = True
raise ValueError
print("JSON RESPONSE:::", response.text)
var2 = datetime.datetime.now().strftime("%H:%M:%S")
print('Json Fetch End Time:', var2)
# Capturing the response json from Web Service
response_json = response.text
load_val = json.loads(response_json)
# Based on the mode application will send the return value
if En_Dec_Mode == 'En':
encrypt_ele = str(load_val['encrypt_val'])
return_ele = encrypt_ele
else:
decrypt_ele = str(load_val['decrypt_val'])
return_ele = decrypt_ele
return return_ele
except ValueError as v:
raise ValueError
except Exception as e:
x = str(e)
print(x)
return 'Error'
|
Let’s discuss the key lines –
try:
_create_unverified_https_context = ssl._create_unverified_context
except AttributeError:
# Legacy python that doesn't verify HTTPS certificates by default
pass
else:
# Handle target environment that doesn't support HTTPS verification
ssl._create_default_https_context = _create_unverified_https_context
If you are running in a secure environment. Sometimes, your proxy or firewall blocks you from accessing the API server – if they are using different networks. Hence, we need to bypass that. However, it is advisable not to use this in Prod environment for obvious reasons.
# Capturing the payload
data = self.payload
# Converting String to Json
json_data = json.loads(data)
This snippet will convert your data frame into a JSON object.
response = requests.post(url, params=param, json=json_data, verify=False)
print("Complete Return Code:: ", str(response.status_code))
print("Return Code Initial::", str(response.status_code)[:1])
if str(response.status_code)[:1] == '2':
# response = s.post(url, params=param, json=json_data, verify=False)
success = True
else:
wait = retries * 2
print("Retry fails! Waiting " + str(wait) + " seconds and retrying.")
time.sleep(wait)
retries += 1
# print('Return Service::')
# Checking Maximum Retries
if retries == max_retries:
success = True
raise ValueError
In the first 3 lines, the application is building a JSON response, which will be sent to the API Server. And, it will capture the response from the server.
Next 8 lines will check the status code. And, based on the status code, it will continue or retry the requests in case if there is any failure or lousy response from the server.
Last 3 lines say if the application crosses the maximum allowable error limit, it will terminate the process by raising it as an error.
# Capturing the response json from Web Service
response_json = response.text
load_val = json.loads(response_json)
Once, it receives the valid response, the application will convert it back to the dataframe & send it to the calling methods.
7. clsParam.py (This script contains the fundamental parameter values to run your client application. Hence, the name comes into the picture.)
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
|
###########################################
#### Written By: SATYAKI DE ########
#### Written On: 20-Jan-2019 ########
###########################################
import os
class clsParam(object):
config = {
'MAX_RETRY' : 5,
'ENCRYPT_MODE' : 'En',
'DECRYPT_MODE': 'De',
'PATH' : os.path.dirname(os.path.realpath(__file__)),
'SRC_DIR' : os.path.dirname(os.path.realpath(__file__)) + '/' + 'src_files/',
'FIN_DIR': os.path.dirname(os.path.realpath(__file__)) + '/' + 'finished/',
'ENCRYPT_URL': "http://192.168.0.13:5000/process/getEncrypt",
'DECRYPT_URL': "http://192.168.0.13:5000/process/getDecrypt",
'NUM_OF_THREAD': 20
}
|
8. clsSerial.py (This script will show the usual or serial way to convert your data into encryption & then to decrypts & store the result into two separate csv files. Hence, the name comes into the picture.)
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
144
145
146
147
148
149
150
151
152
153
154
155
156
157
158
159
160
161
162
163
164
165
166
167
168
169
170
171
172
173
174
175
176
177
178
179
180
181
182
183
184
185
186
187
188
189
190
191
192
193
194
195
196
197
198
199
200
201
202
203
204
205
206
207
208
209
210
211
212
213
214
215
216
217
218
219
220
221
222
223
224
225
226
227
228
229
230
231
232
233
234
235
236
237
238
239
240
241
242
243
244
245
246
247
248
249
250
251
252
253
254
255
256
257
258
259
260
261
262
263
264
265
266
267
268
269
270
271
272
273
274
275
276
277
278
279
280
281
282
283
284
285
286
287
288
289
290
291
292
293
294
295
296
297
298
299
300
301
302
303
304
305
306
307
308
309
310
311
312
|
############################################
#### Written By: SATYAKI DE ####
#### Written On: 10-Feb-2019 ####
#### Package Flask package needs to ####
#### install in order to run this ####
#### script. ####
#### ####
#### Objective: This script will ####
#### initiate the encrypt/decrypt class ####
#### based on client supplied data ####
#### using serial mode operation. ####
############################################
import pandas as p
import clsWeb as cw
import datetime
from clsParam import clsParam as cf
# Disbling Warnings
def warn(*args, **kwargs):
pass
import warnings
warnings.warn = warn
class clsSerial(object):
def __init__(self):
self.path = cf.config['PATH']
self.EncryptMode = str(cf.config['ENCRYPT_MODE'])
self.DecryptMode = str(cf.config['DECRYPT_MODE'])
# Lookup Methods for Encryption
def encrypt_acctNbr(self, row):
# Declaring Local Variable
en_AcctNbr = ''
json_source_str = ''
# Capturing essential values
EncryptMode = self.EncryptMode
lkp_acctNbr = row['Acct_Nbr']
str_acct_nbr = str(lkp_acctNbr)
fil_acct_nbr = str_acct_nbr.strip()
# Forming JSON String for this field
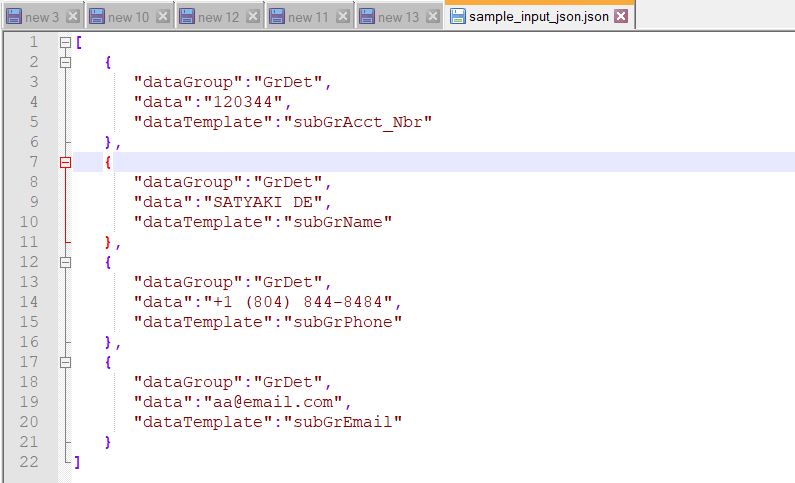
json_source_str = '{"dataGroup":"GrDet","data":"' + fil_acct_nbr + '","dataTemplate":"subGrAcct_Nbr"}'
# Identifying Length of the field
len_acct_nbr = len(fil_acct_nbr)
# This will trigger the service if it has valid data
if len_acct_nbr > 0:
x = cw.clsWeb(json_source_str)
en_AcctNbr = x.getResponse(EncryptMode)
else:
en_AcctNbr = ''
fil_acct_nbr = ''
fil_acct_nbr = ''
return en_AcctNbr
def encrypt_Name(self, row):
# Declaring Local Variable
en_AcctName = ''
# Capturing essential values
EncryptMode = self.EncryptMode
lkp_acctName = row['Name']
str_acct_name = str(lkp_acctName)
fil_acct_name = str_acct_name.strip()
# Forming JSON String for this field
json_source_str = '{"dataGroup":"GrDet","data":"' + fil_acct_name + '","dataTemplate":"subGrName"}'
# Identifying Length of the field
len_acct_nbr = len(fil_acct_name)
# This will trigger the service if it has valid data
if len_acct_nbr > 0:
x = cw.clsWeb(json_source_str)
en_AcctName = x.getResponse(EncryptMode)
else:
en_AcctName = ''
return en_AcctName
def encrypt_Phone(self, row):
# Declaring Local Variable
en_Phone = ''
# Capturing essential values
EncryptMode = self.EncryptMode
lkp_phone = row['Phone']
str_phone = str(lkp_phone)
fil_phone = str_phone.strip()
# Forming JSON String for this field
json_source_str = '{"dataGroup":"GrDet","data":"' + fil_phone + '","dataTemplate":"subGrPhone"}'
# Identifying Length of the field
len_acct_nbr = len(fil_phone)
# This will trigger the service if it has valid data
if len_acct_nbr > 0:
x = cw.clsWeb(json_source_str)
en_Phone = x.getResponse(EncryptMode)
else:
en_Phone = ''
return en_Phone
def encrypt_Email(self, row):
# Declaring Local Variable
en_Email = ''
# Capturing essential values
EncryptMode = self.EncryptMode
lkp_email = row['Email']
str_email = str(lkp_email)
fil_email = str_email.strip()
# Forming JSON String for this field
json_source_str = '{"dataGroup":"GrDet","data":"' + fil_email + '","dataTemplate":"subGrEmail"}'
# Identifying Length of the field
len_acct_nbr = len(fil_email)
# This will trigger the service if it has valid data
if len_acct_nbr > 0:
x = cw.clsWeb(json_source_str)
en_Email = x.getResponse(EncryptMode)
else:
en_Email = ''
return en_Email
# Lookup Methods for Decryption
def decrypt_acctNbr(self, row):
# Declaring Local Variable
de_AcctNbr = ''
json_source_str = ''
# Capturing essential values
EncryptMode = self.DecryptMode
lkp_acctNbr = row['Acct_Nbr']
str_acct_nbr = str(lkp_acctNbr)
fil_acct_nbr = str_acct_nbr.strip()
# Forming JSON String for this field
json_source_str = '{"dataGroup":"GrDet","data":"' + fil_acct_nbr + '","dataTemplate":"subGrAcct_Nbr"}'
# Identifying Length of the field
len_acct_nbr = len(fil_acct_nbr)
# This will trigger the service if it has valid data
if len_acct_nbr > 0:
x = cw.clsWeb(json_source_str)
de_AcctNbr = x.getResponse(EncryptMode)
else:
de_AcctNbr = ''
return de_AcctNbr
def decrypt_Name(self, row):
# Declaring Local Variable
de_AcctName = ''
# Capturing essential values
EncryptMode = self.DecryptMode
lkp_acctName = row['Name']
str_acct_name = str(lkp_acctName)
fil_acct_name = str_acct_name.strip()
# Forming JSON String for this field
json_source_str = '{"dataGroup":"GrDet","data":"' + fil_acct_name + '","dataTemplate":"subGrName"}'
# Identifying Length of the field
len_acct_nbr = len(fil_acct_name)
# This will trigger the service if it has valid data
if len_acct_nbr > 0:
x = cw.clsWeb(json_source_str)
de_AcctName = x.getResponse(EncryptMode)
else:
de_AcctName = ''
return de_AcctName
def decrypt_Phone(self, row):
# Declaring Local Variable
de_Phone = ''
# Capturing essential values
EncryptMode = self.DecryptMode
lkp_phone = row['Phone']
str_phone = str(lkp_phone)
fil_phone = str_phone.strip()
# Forming JSON String for this field
json_source_str = '{"dataGroup":"GrDet","data":"' + fil_phone + '","dataTemplate":"subGrPhone"}'
# Identifying Length of the field
len_acct_nbr = len(fil_phone)
# This will trigger the service if it has valid data
if len_acct_nbr > 0:
x = cw.clsWeb(json_source_str)
de_Phone = x.getResponse(EncryptMode)
else:
de_Phone = ''
return de_Phone
def decrypt_Email(self, row):
# Declaring Local Variable
de_Email = ''
# Capturing essential values
EncryptMode = self.DecryptMode
lkp_email = row['Email']
str_email = str(lkp_email)
fil_email = str_email.strip()
# Forming JSON String for this field
json_source_str = '{"dataGroup":"GrDet","data":"' + fil_email + '","dataTemplate":"subGrEmail"}'
# Identifying Length of the field
len_acct_nbr = len(fil_email)
# This will trigger the service if it has valid data
if len_acct_nbr > 0:
x = cw.clsWeb(json_source_str)
de_Email = x.getResponse(EncryptMode)
else:
de_Email = ''
return de_Email
def getEncrypt(self, df_payload):
try:
df_input = p.DataFrame()
df_fin = p.DataFrame()
# Assigning Target File Basic Name
df_input = df_payload
# Checking total count of rows
count_row = df_input.shape[0]
print('Total number of records to process:: ', count_row)
# Deriving rows
df_input['Encrypt_Acct_Nbr'] = df_input.apply(lambda row: self.encrypt_acctNbr(row), axis=1)
df_input['Encrypt_Name'] = df_input.apply(lambda row: self.encrypt_Name(row), axis=1)
df_input['Encrypt_Phone'] = df_input.apply(lambda row: self.encrypt_Phone(row), axis=1)
df_input['Encrypt_Email'] = df_input.apply(lambda row: self.encrypt_Email(row), axis=1)
# Dropping original columns
df_input.drop(['Acct_Nbr', 'Name', 'Phone', 'Email'], axis=1, inplace=True)
# Renaming new columns with the old column names
df_input.rename(columns={'Encrypt_Acct_Nbr':'Acct_Nbr'}, inplace=True)
df_input.rename(columns={'Encrypt_Name': 'Name'}, inplace=True)
df_input.rename(columns={'Encrypt_Phone': 'Phone'}, inplace=True)
df_input.rename(columns={'Encrypt_Email': 'Email'}, inplace=True)
# New Column List Orders
column_order = ['Acct_Nbr', 'Name', 'Acct_Addr_1', 'Acct_Addr_2', 'Phone', 'Email', 'Serial_No']
df_fin = df_input.reindex(column_order, axis=1)
return df_fin
except Exception as e:
df_error = p.DataFrame({'Acct_Nbr':str(e), 'Name':'', 'Acct_Addr_1':'', 'Acct_Addr_2':'', 'Phone':'', 'Email':'', 'Serial_No':''})
return df_error
def getDecrypt(self, df_encrypted_payload):
try:
df_input = p.DataFrame()
df_fin = p.DataFrame()
# Assigning Target File Basic Name
df_input = df_encrypted_payload
# Checking total count of rows
count_row = df_input.shape[0]
print('Total number of records to process:: ', count_row)
# Deriving rows
df_input['Decrypt_Acct_Nbr'] = df_input.apply(lambda row: self.decrypt_acctNbr(row), axis=1)
df_input['Decrypt_Name'] = df_input.apply(lambda row: self.decrypt_Name(row), axis=1)
df_input['Decrypt_Phone'] = df_input.apply(lambda row: self.decrypt_Phone(row), axis=1)
df_input['Decrypt_Email'] = df_input.apply(lambda row: self.decrypt_Email(row), axis=1)
# Dropping original columns
df_input.drop(['Acct_Nbr', 'Name', 'Phone', 'Email'], axis=1, inplace=True)
# Renaming new columns with the old column names
df_input.rename(columns={'Decrypt_Acct_Nbr':'Acct_Nbr'}, inplace=True)
df_input.rename(columns={'Decrypt_Name': 'Name'}, inplace=True)
df_input.rename(columns={'Decrypt_Phone': 'Phone'}, inplace=True)
df_input.rename(columns={'Decrypt_Email': 'Email'}, inplace=True)
# New Column List Orders
column_order = ['Acct_Nbr', 'Name', 'Acct_Addr_1', 'Acct_Addr_2', 'Phone', 'Email']
df_fin = df_input.reindex(column_order, axis=1)
return df_fin
except Exception as e:
df_error = p.DataFrame({'Acct_Nbr':str(e), 'Name':'', 'Acct_Addr_1':'', 'Acct_Addr_2':'', 'Phone':'', 'Email':''})
return df_error
|
Key lines to discuss –
Main two methods, we’ll be looking into & they are –
a. getEncrypt
b. getDecrypt
However, these two functions constructions are identical in nature. One is for encryption & the other one is decryption.
# Deriving rows
df_input['Encrypt_Acct_Nbr'] = df_input.apply(lambda row: self.encrypt_acctNbr(row), axis=1)
df_input['Encrypt_Name'] = df_input.apply(lambda row: self.encrypt_Name(row), axis=1)
df_input['Encrypt_Phone'] = df_input.apply(lambda row: self.encrypt_Phone(row), axis=1)
df_input['Encrypt_Email'] = df_input.apply(lambda row: self.encrypt_Email(row), axis=1)
As you can see, the application is processing row-by-row & column-by-column data transformations using look-up functions.
# Dropping original columns
df_input.drop(['Acct_Nbr', 'Name', 'Phone', 'Email'], axis=1, inplace=True)
As the comment suggested, the application is dropping all the unencrypted source columns.
# Renaming new columns with the old column names
df_input.rename(columns={'Encrypt_Acct_Nbr':'Acct_Nbr'}, inplace=True)
df_input.rename(columns={'Encrypt_Name': 'Name'}, inplace=True)
df_input.rename(columns={'Encrypt_Phone': 'Phone'}, inplace=True)
df_input.rename(columns={'Encrypt_Email': 'Email'}, inplace=True)
Once, the application drops all the source columns, it will rename the new column names back to old columns & based on this data will be merged with the rest of the data from the source csv.
# New Column List Orders
column_order = ['Acct_Nbr', 'Name', 'Acct_Addr_1', 'Acct_Addr_2', 'Phone', 'Email', 'Serial_No']
df_fin = df_input.reindex(column_order, axis=1)
Once, the application finished doing all these transformations, it will now re-sequence the order of the columns, which will create the same column order as it’s source csv files.
Similar logic is applicable for the decryption as well.
As we know, there are many look-up methods take part as part of this drive.
encrypt_acctNbr, encrypt_Name, encrypt_Phone, encrypt_Email
decrypt_acctNbr, decrypt_Name, decrypt_Phone, decrypt_Email
We’ll discuss only one method as these are completely identical.
# Capturing essential values
EncryptMode = self.EncryptMode
lkp_acctNbr = row['Acct_Nbr']
str_acct_nbr = str(lkp_acctNbr)
fil_acct_nbr = str_acct_nbr.strip()
From the row, our application is extracting the relevant column. In this case, it is Acct_Nbr. And, then converts it to string & remove any unnecessary white space from it.
# Forming JSON String for this field
json_source_str = '{"dataGroup":"GrDet","data":"' + fil_acct_nbr + '","dataTemplate":"subGrAcct_Nbr"}'
Once extracted, the application will build the target JON string as per column data.
# Identifying Length of the field
len_acct_nbr = len(fil_acct_nbr)
# This will trigger the service if it has valid data
if len_acct_nbr > 0:
x = cw.clsWeb(json_source_str)
en_AcctNbr = x.getResponse(EncryptMode)
else:
en_AcctNbr = ''
Based on the length of the extracted value, our application will trigger the individual JSON requests & will receive the data frame in response.
9. clsParallel.py (This script will use the queue to make asynchronous calls & perform the same encryption & decryption. Hence, the name comes into the picture.)
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
144
145
146
147
148
149
150
151
152
153
154
155
156
157
158
159
160
161
162
163
164
165
166
167
168
169
170
171
172
173
174
175
176
177
178
179
180
181
182
183
184
185
186
187
188
189
190
191
192
193
194
195
196
197
198
199
200
201
202
203
204
205
206
207
208
209
210
211
212
213
214
215
216
217
218
219
220
221
222
223
224
225
226
227
228
229
230
231
232
233
234
235
236
237
238
239
240
241
242
243
244
245
246
247
248
249
250
251
252
253
254
255
256
257
258
259
260
261
262
263
264
265
266
267
268
269
270
271
272
273
274
275
276
277
278
279
280
281
282
283
284
285
286
287
288
289
290
291
292
293
294
295
296
297
298
299
300
301
302
303
304
305
306
307
308
309
310
311
312
313
314
315
316
317
318
319
320
321
322
323
324
325
326
327
328
329
330
331
332
333
334
335
336
337
338
339
340
341
342
343
344
345
346
347
348
349
350
351
352
353
354
355
356
357
358
359
360
361
362
363
364
365
366
367
368
369
370
371
372
373
374
375
376
377
378
379
380
381
382
383
384
385
386
387
388
389
390
391
392
393
394
395
396
397
398
399
400
401
402
403
404
405
406
407
408
409
410
411
412
413
414
415
416
417
418
419
420
421
422
423
424
425
426
427
428
429
430
431
432
433
434
435
436
437
438
439
440
441
442
443
444
445
446
447
448
449
450
451
452
453
454
455
456
457
458
459
460
461
462
463
464
465
466
467
468
469
470
471
472
473
474
475
476
477
478
479
480
481
482
483
484
485
486
487
488
489
490
491
492
493
494
495
496
497
498
499
500
501
502
503
504
505
506
507
508
509
510
511
512
513
514
515
516
517
518
519
520
521
522
523
524
525
526
527
528
529
530
531
532
533
534
535
536
537
538
539
540
541
542
543
544
545
546
547
548
549
550
551
552
553
554
555
556
557
558
559
560
561
562
563
564
565
566
567
568
569
570
571
572
573
574
575
576
577
578
579
580
581
582
583
584
585
586
587
588
589
590
591
592
593
594
595
|
############################################
#### Written By: SATYAKI DE ####
#### Written On: 10-Feb-2019 ####
#### Package Flask package needs to ####
#### install in order to run this ####
#### script. ####
#### ####
#### Objective: This script will ####
#### initiate the encrypt/decrypt class ####
#### based on client supplied data. ####
#### This script will use the advance ####
#### queue & asynchronus calls to the ####
#### API Server to process Encryption & ####
#### Decryption on our csv files. ####
############################################
import pandas as p
import clsWebService as cw
import datetime
from clsParam import clsParam as cf
from multiprocessing import Lock, Process, Queue, freeze_support, JoinableQueue
import gc
import signal
import time
import os
import queue
import asyncio
# Declaring Global Variable
q = Queue()
lock = Lock()
finished_task = JoinableQueue()
pending_task = JoinableQueue()
sp_fin_dict = {}
dp_fin_dict = {}
# Disbling Warnings
def warn(*args, **kwargs):
pass
import warnings
warnings.warn = warn
class clsParallel(object):
def __init__(self):
self.path = cf.config['PATH']
self.EncryptMode = str(cf.config['ENCRYPT_MODE'])
self.DecryptMode = str(cf.config['DECRYPT_MODE'])
self.num_worker_process = int(cf.config['NUM_OF_THREAD'])
self.lock = Lock()
# Lookup Methods for Encryption
def encrypt_acctNbr(self, row):
# Declaring Local Variable
en_AcctNbr = ''
json_source_str = ''
# Capturing essential values
EncryptMode = self.EncryptMode
lkp_acctNbr = row['Acct_Nbr']
str_acct_nbr = str(lkp_acctNbr)
fil_acct_nbr = str_acct_nbr.strip()
# Forming JSON String for this field
json_source_str = '{"dataGroup":"GrDet","data":"' + fil_acct_nbr + '","dataTemplate":"subGrAcct_Nbr"}'
# Identifying Length of the field
len_acct_nbr = len(fil_acct_nbr)
# This will trigger the service if it has valid data
if len_acct_nbr > 0:
x = cw.clsWeb(json_source_str)
en_AcctNbr = x.getResponse(EncryptMode)
else:
en_AcctNbr = ''
fil_acct_nbr = ''
return en_AcctNbr
def encrypt_Name(self, row):
# Declaring Local Variable
en_AcctName = ''
# Capturing essential values
EncryptMode = self.EncryptMode
lkp_acctName = row['Name']
str_acct_name = str(lkp_acctName)
fil_acct_name = str_acct_name.strip()
# Forming JSON String for this field
json_source_str = '{"dataGroup":"GrDet","data":"' + fil_acct_name + '","dataTemplate":"subGrName"}'
# Identifying Length of the field
len_acct_nbr = len(fil_acct_name)
# This will trigger the service if it has valid data
if len_acct_nbr > 0:
x = cw.clsWeb(json_source_str)
en_AcctName = x.getResponse(EncryptMode)
else:
en_AcctName = ''
return en_AcctName
def encrypt_Phone(self, row):
# Declaring Local Variable
en_Phone = ''
# Capturing essential values
EncryptMode = self.EncryptMode
lkp_phone = row['Phone']
str_phone = str(lkp_phone)
fil_phone = str_phone.strip()
# Forming JSON String for this field
json_source_str = '{"dataGroup":"GrDet","data":"' + fil_phone + '","dataTemplate":"subGrPhone"}'
# Identifying Length of the field
len_acct_nbr = len(fil_phone)
# This will trigger the service if it has valid data
if len_acct_nbr > 0:
x = cw.clsWeb(json_source_str)
en_Phone = x.getResponse(EncryptMode)
else:
en_Phone = ''
return en_Phone
def encrypt_Email(self, row):
# Declaring Local Variable
en_Email = ''
# Capturing essential values
EncryptMode = self.EncryptMode
lkp_email = row['Email']
str_email = str(lkp_email)
fil_email = str_email.strip()
# Forming JSON String for this field
json_source_str = '{"dataGroup":"GrDet","data":"' + fil_email + '","dataTemplate":"subGrEmail"}'
# Identifying Length of the field
len_acct_nbr = len(fil_email)
# This will trigger the service if it has valid data
if len_acct_nbr > 0:
x = cw.clsWeb(json_source_str)
en_Email = x.getResponse(EncryptMode)
else:
en_Email = ''
return en_Email
# Lookup Methods for Decryption
def decrypt_acctNbr(self, row):
# Declaring Local Variable
de_AcctNbr = ''
json_source_str = ''
# Capturing essential values
EncryptMode = self.DecryptMode
lkp_acctNbr = row['Acct_Nbr']
str_acct_nbr = str(lkp_acctNbr)
fil_acct_nbr = str_acct_nbr.strip()
# Forming JSON String for this field
json_source_str = '{"dataGroup":"GrDet","data":"' + fil_acct_nbr + '","dataTemplate":"subGrAcct_Nbr"}'
# Identifying Length of the field
len_acct_nbr = len(fil_acct_nbr)
# This will trigger the service if it has valid data
if len_acct_nbr > 0:
x = cw.clsWeb(json_source_str)
de_AcctNbr = x.getResponse(EncryptMode)
else:
de_AcctNbr = ''
return de_AcctNbr
def decrypt_Name(self, row):
# Declaring Local Variable
de_AcctName = ''
# Capturing essential values
EncryptMode = self.DecryptMode
lkp_acctName = row['Name']
str_acct_name = str(lkp_acctName)
fil_acct_name = str_acct_name.strip()
# Forming JSON String for this field
json_source_str = '{"dataGroup":"GrDet","data":"' + fil_acct_name + '","dataTemplate":"subGrName"}'
# Identifying Length of the field
len_acct_nbr = len(fil_acct_name)
# This will trigger the service if it has valid data
if len_acct_nbr > 0:
x = cw.clsWeb(json_source_str)
de_AcctName = x.getResponse(EncryptMode)
else:
de_AcctName = ''
return de_AcctName
def decrypt_Phone(self, row):
# Declaring Local Variable
de_Phone = ''
# Capturing essential values
EncryptMode = self.DecryptMode
lkp_phone = row['Phone']
str_phone = str(lkp_phone)
fil_phone = str_phone.strip()
# Forming JSON String for this field
json_source_str = '{"dataGroup":"GrDet","data":"' + fil_phone + '","dataTemplate":"subGrPhone"}'
# Identifying Length of the field
len_acct_nbr = len(fil_phone)
# This will trigger the service if it has valid data
if len_acct_nbr > 0:
x = cw.clsWeb(json_source_str)
de_Phone = x.getResponse(EncryptMode)
else:
de_Phone = ''
return de_Phone
def decrypt_Email(self, row):
# Declaring Local Variable
de_Email = ''
# Capturing essential values
EncryptMode = self.DecryptMode
lkp_email = row['Email']
str_email = str(lkp_email)
fil_email = str_email.strip()
# Forming JSON String for this field
json_source_str = '{"dataGroup":"GrDet","data":"' + fil_email + '","dataTemplate":"subGrEmail"}'
# Identifying Length of the field
len_acct_nbr = len(fil_email)
# This will trigger the service if it has valid data
if len_acct_nbr > 0:
x = cw.clsWeb(json_source_str)
de_Email = x.getResponse(EncryptMode)
else:
de_Email = ''
return de_Email
def getEncrypt(self, df_dict):
try:
en_fin_dict = {}
df_input = p.DataFrame()
df_fin = p.DataFrame()
# Assigning Target File Basic Name
for k, v in df_dict.items():
Process_Name = k
df_input = v
# Checking total count of rows
count_row = int(df_input.shape[0])
print('Part number of records to process:: ', count_row)
if count_row > 0:
# Deriving rows
df_input['Encrypt_Acct_Nbr'] = df_input.apply(lambda row: self.encrypt_acctNbr(row), axis=1)
df_input['Encrypt_Name'] = df_input.apply(lambda row: self.encrypt_Name(row), axis=1)
df_input['Encrypt_Phone'] = df_input.apply(lambda row: self.encrypt_Phone(row), axis=1)
df_input['Encrypt_Email'] = df_input.apply(lambda row: self.encrypt_Email(row), axis=1)
# Dropping original columns
df_input.drop(['Acct_Nbr', 'Name', 'Phone', 'Email'], axis=1, inplace=True)
# Renaming new columns with the old column names
df_input.rename(columns={'Encrypt_Acct_Nbr':'Acct_Nbr'}, inplace=True)
df_input.rename(columns={'Encrypt_Name': 'Name'}, inplace=True)
df_input.rename(columns={'Encrypt_Phone': 'Phone'}, inplace=True)
df_input.rename(columns={'Encrypt_Email': 'Email'}, inplace=True)
# New Column List Orders
column_order = ['Acct_Nbr', 'Name', 'Acct_Addr_1', 'Acct_Addr_2', 'Phone', 'Email', 'Serial_No']
df_fin = df_input.reindex(column_order, axis=1)
sp_fin_dict[Process_Name] = df_fin
return sp_fin_dict
except Exception as e:
df_error = p.DataFrame({'Acct_Nbr':str(e), 'Name':'', 'Acct_Addr_1':'', 'Acct_Addr_2':'', 'Phone':'', 'Email':'', 'Serial_No':''})
sp_fin_dict[Process_Name] = df_error
return sp_fin_dict
async def produceEncr(self, queue, l_dict):
m_dict = {}
m_dict = self.getEncrypt(l_dict)
for k, v in m_dict.items():
item = k
print('producing {}...'.format(item))
await queue.put(m_dict)
async def consumeEncr(self, queue):
result_dict = {}
while True:
# wait for an item from the producer
sp_fin_dict.update(await queue.get())
# process the item
for k, v in sp_fin_dict.items():
item = k
print('consuming {}...'.format(item))
# Notify the queue that the item has been processed
queue.task_done()
async def runEncrypt(self, n, df_input):
l_dict = {}
queue = asyncio.Queue()
# schedule the consumer
consumer = asyncio.ensure_future(self.consumeEncr(queue))
start_pos = 0
end_pos = 0
num_worker_process = n
count_row = df_input.shape[0]
print('Total number of records to process:: ', count_row)
interval = int(count_row / num_worker_process) + 1
actual_worker_task = int(count_row / interval) + 1
for i in range(actual_worker_task):
name = 'Task-' + str(i)
if ((start_pos + interval) < count_row):
end_pos = start_pos + interval
else:
end_pos = start_pos + (count_row - start_pos)
print("start_pos: ", start_pos)
print("end_pos: ", end_pos)
split_df = df_input.iloc[start_pos:end_pos]
l_dict[name] = split_df
if ((start_pos > count_row) | (start_pos == count_row)):
break
else:
start_pos = start_pos + interval
# run the producer and wait for completion
await self.produceEncr(queue, l_dict)
# wait until the consumer has processed all items
await queue.join()
# the consumer is still awaiting for an item, cancel it
consumer.cancel()
return sp_fin_dict
def getEncryptParallel(self, df_payload):
l_dict = {}
data_dict = {}
min_val_list = {}
cnt = 1
num_worker_process = self.num_worker_process
actual_worker_task = 0
number_of_processes = 4
processes = []
split_df = p.DataFrame()
df_ret = p.DataFrame()
dummy_df = p.DataFrame()
# Assigning Target File Basic Name
df_input = df_payload
# Checking total count of rows
count_row = df_input.shape[0]
print('Total number of records to process:: ', count_row)
interval = int(count_row / num_worker_process) + 1
actual_worker_task = int(count_row/interval) + 1
loop = asyncio.get_event_loop()
loop.run_until_complete(self.runEncrypt(actual_worker_task, df_input))
loop.close()
for k, v in sp_fin_dict.items():
min_val_list[int(k.replace('Task-', ''))] = v
min_val = min(min_val_list, key=int)
print("Minimum Index Value: ", min_val)
for k, v in sorted(sp_fin_dict.items(), key=lambda k: int(k[0].replace('Task-', ''))):
if int(k.replace('Task-', '')) == min_val:
df_ret = sp_fin_dict[k]
else:
d_frames = [df_ret, sp_fin_dict[k]]
df_ret = p.concat(d_frames)
return df_ret
def getDecrypt(self, df_encrypted_dict):
try:
de_fin_dict = {}
df_input = p.DataFrame()
df_fin = p.DataFrame()
# Assigning Target File Basic Name
for k, v in df_encrypted_dict.items():
Process_Name = k
df_input = v
# Checking total count of rows
count_row = int(df_input.shape[0])
print('Part number of records to process:: ', count_row)
if count_row > 0:
# Deriving rows
df_input['Decrypt_Acct_Nbr'] = df_input.apply(lambda row: self.decrypt_acctNbr(row), axis=1)
df_input['Decrypt_Name'] = df_input.apply(lambda row: self.decrypt_Name(row), axis=1)
df_input['Decrypt_Phone'] = df_input.apply(lambda row: self.decrypt_Phone(row), axis=1)
df_input['Decrypt_Email'] = df_input.apply(lambda row: self.decrypt_Email(row), axis=1)
# Dropping original columns
df_input.drop(['Acct_Nbr', 'Name', 'Phone', 'Email'], axis=1, inplace=True)
# Renaming new columns with the old column names
df_input.rename(columns={'Decrypt_Acct_Nbr':'Acct_Nbr'}, inplace=True)
df_input.rename(columns={'Decrypt_Name': 'Name'}, inplace=True)
df_input.rename(columns={'Decrypt_Phone': 'Phone'}, inplace=True)
df_input.rename(columns={'Decrypt_Email': 'Email'}, inplace=True)
# New Column List Orders
column_order = ['Acct_Nbr', 'Name', 'Acct_Addr_1', 'Acct_Addr_2', 'Phone', 'Email', 'Serial_No']
df_fin = df_input.reindex(column_order, axis=1)
de_fin_dict[Process_Name] = df_fin
return de_fin_dict
except Exception as e:
df_error = p.DataFrame({'Acct_Nbr': str(e), 'Name': '', 'Acct_Addr_1': '', 'Acct_Addr_2': '', 'Phone': '', 'Email': '', 'Serial_No': ''})
de_fin_dict[Process_Name] = df_error
return de_fin_dict
async def produceDecr(self, queue, l_dict):
m_dict = {}
m_dict = self.getDecrypt(l_dict)
for k, v in m_dict.items():
item = k
print('producing {}...'.format(item))
await queue.put(m_dict)
async def consumeDecr(self, queue):
result_dict = {}
while True:
# wait for an item from the producer
dp_fin_dict.update(await queue.get())
# process the item
for k, v in dp_fin_dict.items():
item = k
print('consuming {}...'.format(item))
# Notify the queue that the item has been processed
queue.task_done()
async def runDecrypt(self, n, df_input):
l_dict = {}
queue = asyncio.Queue()
# schedule the consumer
consumerDe = asyncio.ensure_future(self.consumeDecr(queue))
start_pos = 0
end_pos = 0
num_worker_process = n
count_row = df_input.shape[0]
print('Total number of records to process:: ', count_row)
interval = int(count_row / num_worker_process) + 1
actual_worker_task = int(count_row / interval) + 1
for i in range(actual_worker_task):
name = 'Task-' + str(i)
if ((start_pos + interval) < count_row):
end_pos = start_pos + interval
else:
end_pos = start_pos + (count_row - start_pos)
print("start_pos: ", start_pos)
print("end_pos: ", end_pos)
split_df = df_input.iloc[start_pos:end_pos]
l_dict[name] = split_df
if ((start_pos > count_row) | (start_pos == count_row)):
break
else:
start_pos = start_pos + interval
# run the producer and wait for completion
await self.produceDecr(queue, l_dict)
# wait until the consumer has processed all items
await queue.join()
# the consumer is still awaiting for an item, cancel it
consumerDe.cancel()
return dp_fin_dict
def getDecryptParallel(self, df_payload):
l_dict = {}
data_dict = {}
min_val_list = {}
cnt = 1
num_worker_process = self.num_worker_process
actual_worker_task = 0
number_of_processes = 4
processes = []
split_df = p.DataFrame()
df_ret_1 = p.DataFrame()
dummy_df = p.DataFrame()
# Assigning Target File Basic Name
df_input = df_payload
# Checking total count of rows
count_row = df_input.shape[0]
print('Total number of records to process:: ', count_row)
interval = int(count_row / num_worker_process) + 1
actual_worker_task = int(count_row/interval) + 1
loop_1 = asyncio.new_event_loop()
asyncio.set_event_loop(asyncio.new_event_loop())
loop_2 = asyncio.get_event_loop()
loop_2.run_until_complete(self.runDecrypt(actual_worker_task, df_input))
loop_2.close()
for k, v in dp_fin_dict.items():
min_val_list[int(k.replace('Task-', ''))] = v
min_val = min(min_val_list, key=int)
print("Minimum Index Value: ", min_val)
for k, v in sorted(dp_fin_dict.items(), key=lambda k: int(k[0].replace('Task-', ''))):
if int(k.replace('Task-', '')) == min_val:
df_ret_1 = dp_fin_dict[k]
else:
d_frames = [df_ret_1, dp_fin_dict[k]]
df_ret_1 = p.concat(d_frames)
return df_ret_1
|
I don’t want to discuss any more look-up methods as the post is already pretty big. Only address a few critical lines
Under getEncryptParallel, the following lines are essential –
# Checking total count of rows
count_row = df_input.shape[0]
print('Total number of records to process:: ', count_row)
interval = int(count_row / num_worker_process) + 1
actual_worker_task = int(count_row/interval) + 1
Based on the dataframe total number of records, our application will split that main dataframe into parts of sub dataframe & then pass them using queue by asynchronous queue calls.
loop = asyncio.get_event_loop()
loop.run_until_complete(self.runEncrypt(actual_worker_task, df_input))
loop.close()
Initiating our queue methods & passing our dataframe to it.
for k, v in sorted(sp_fin_dict.items(), key=lambda k: int(k[0].replace('Task-', ''))):
if int(k.replace('Task-', '')) == min_val:
df_ret = sp_fin_dict[k]
else:
d_frames = [df_ret, sp_fin_dict[k]]
df_ret = p.concat(d_frames)
Our application is sending & receiving data using the dictionary. The reason is – we’re not expecting data that we may get it from our server in sequence. Instead, we’re hoping the data will be random. Hence, using keys, we’re maintaining our final sequence & that will ensure our application to joining back to the correct sets of source data, which won’t be the candidate for any encryption/decryption.
Let’s discuss runEncrypt method.
for i in range(actual_worker_task):
name = 'Task-' + str(i)
if ((start_pos + interval) < count_row):
end_pos = start_pos + interval
else:
end_pos = start_pos + (count_row - start_pos)
print("start_pos: ", start_pos)
print("end_pos: ", end_pos)
split_df = df_input.iloc[start_pos:end_pos]
l_dict[name] = split_df
if ((start_pos > count_row) | (start_pos == count_row)):
break
else:
start_pos = start_pos + interval
Here, our application is splitting our source data frame into multiple sub dataframe & then it can be processed in parallel using queues.
# run the producer and wait for completion
await self.produceEncr(queue, l_dict)
# wait until the consumer has processed all items
await queue.join()
Invoking the encryption-decryption process using queues. The last line is significant. The queue will not destroy until all the item produced/place into the queue are not consumed. Hence, your main program will wait until it processes all the records of your dataframe.
Two methods named produceEncr & consumeEncr mainly used for placing an item inside the queue & then after encryption/decryption it will retrieve it from the queue.
Few important lines from both the methods are –
#produceEncr
await queue.put(m_dict)
#consumeEncr
# wait for an item from the producer
sp_fin_dict.update(await queue.get())
# Notify the queue that the item has been processed
queue.task_done()
From the first two lines, one can see that the application will place its item into the queue. Rests are the lines from the other methods. Our application is pouring the data into the dictionary, which will be returned to our calling methods. The last line is significantly essential. Without the task_done process, the queue will continue to wait for upcoming items. Hence, that will trigger infinite wait or sometimes deadlock.
10. callClient.py (This script will trigger both the serial & parallel process of encryption one by one & finally capture some statistics. Hence, the name comes into the picture.)
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
144
145
146
147
148
149
150
151
152
153
154
155
156
157
158
159
160
161
162
163
164
165
166
167
168
169
170
171
172
173
174
175
176
177
178
179
180
181
182
|
############################################
#### Written By: SATYAKI DE ####
#### Written On: 10-Feb-2019 ####
#### Package Flask package needs to ####
#### install in order to run this ####
#### script. ####
#### ####
#### Objective: This script will ####
#### initiate the encrypt/decrypt class ####
#### based on client supplied data. ####
############################################
import pandas as p
import clsSerial as cs
import time
import datetime
from clsParam import clsParam as cf
import clsParallel as cp
import sys
def main():
source_df = p.DataFrame()
encrypted_df = p.DataFrame()
source_encrypted_df = p.DataFrame()
decrypted_df = p.DataFrame()
encrypted_parallel_df = p.DataFrame()
source_encrypted_parallel_df = p.DataFrame()
decrypted_parallel_df = p.DataFrame()
###############################################################################
##### Start Of Serial Encryption Methods ######
###############################################################################
print("-" * 157)
startEnTime = time.time()
srcFile = 'acct_addr_20180106'
srcFileWithPath = str(cf.config['SRC_DIR']) + srcFile + '.csv'
print("Calling Serial Process to Encrypt!")
# Reading source file
source_df = p.read_csv(srcFileWithPath, index_col=False)
# Calling Encrypt Methods
x = cs.clsSerial()
encrypted_df = x.getEncrypt(source_df)
# Handling Multiple source files
var = datetime.datetime.now().strftime("%H.%M.%S")
print('Target File Extension will contain the following:: ', var)
targetFile = srcFile + '_Serial_'
taregetFileWithPath = str(cf.config['FIN_DIR']) + targetFile + var + '.csv'
# Finally Storing them into csv
encrypted_df.to_csv(taregetFileWithPath, index=False)
endEnTime = time.time()
z1 = str(endEnTime - startEnTime)
print("Over All Encrypt Process Time:", z1)
time.sleep(20)
###############################################################################
##### Start Of Serial Decryption Methods ######
###############################################################################
print("-" * 157)
startDeTime = time.time()
srcFileWithPath = taregetFileWithPath
print("Calling Serial Process to Decrypt!")
# Reading source file
source_encrypted_df = p.read_csv(srcFileWithPath, index_col=False)
# Calling Encrypt Methods
x = cs.clsSerial()
decrypted_df = x.getDecrypt(source_encrypted_df)
targetFile = srcFile + '_restored_'
taregetFileWithPath = str(cf.config['FIN_DIR']) + targetFile + var + '.csv'
# Finally Storing them into csv
decrypted_df.to_csv(taregetFileWithPath, index=False)
endDeTime = time.time()
z2 = str(endDeTime - startDeTime)
print("Over All Decrypt Process Time:", z2)
print("-" * 157)
###############################################################################
##### End Of Serial Encryption/Decryption Methods ######
###############################################################################
time.sleep(20)
###############################################################################
##### Start Of Parallel Encryption Methods ######
###############################################################################
print("-" * 157)
startEnTime = time.time()
srcFileWithPath = str(cf.config['SRC_DIR']) + srcFile + '.csv'
print("Calling Serial Process to Encrypt!")
# Reading source file
source_df = p.read_csv(srcFileWithPath, index_col=False)
# Calling Encrypt Methods
x = cp.clsParallel()
encrypted_parallel_df = x.getEncryptParallel(source_df)
# Handling Multiple source files
var = datetime.datetime.now().strftime("%H.%M.%S")
print('Target File Extension will contain the following:: ', var)
targetFile = srcFile + '_Parallel_'
taregetFileWithPath = str(cf.config['FIN_DIR']) + targetFile + var + '.csv'
# Finally Storing them into csv
encrypted_parallel_df.to_csv(taregetFileWithPath, index=False)
endEnTime = time.time()
z3 = str(endEnTime - startEnTime)
print("Over All Encrypt Process Time:", z3)
time.sleep(20)
###############################################################################
##### Start Of Serial Decryption Methods ######
###############################################################################
print("-" * 157)
startDeTime = time.time()
srcFileWithPath = taregetFileWithPath
print("Calling Parallel Process to Decrypt!")
# Reading source file
source_encrypted_parallel_df = p.read_csv(srcFileWithPath, index_col=False)
# Calling Encrypt Methods
x = cp.clsParallel()
decrypted_parallel_df = x.getDecryptParallel(source_encrypted_parallel_df)
targetFile = srcFile + '_restored_'
taregetFileWithPath = str(cf.config['FIN_DIR']) + targetFile + var + '.csv'
# Finally Storing them into csv
decrypted_parallel_df.to_csv(taregetFileWithPath, index=False)
endDeTime = time.time()
z4 = str(endDeTime - startDeTime)
print("Over All Decrypt Process Time:", z4)
print("-" * 157)
###############################################################################
##### End Of Parallel Encryption/Decryption Methods ######
###############################################################################
###############################################################################
##### Final Statistics between Serial & Parallel loading. ######
###############################################################################
print("-" * 157)
print("Serial Encryption:: ", z1)
print("Serial Decryption:: ", z2)
print("-" * 157)
print("Parallel Encryption:: ", z3)
print("Parallel Decryption:: ", z4)
print("-" * 157)
if __name__ == '__main__':
main()
|
As you can see, we’ve triggered both the application using the main callable scripts.
Let’s explore the output –
Windows:

Mac:

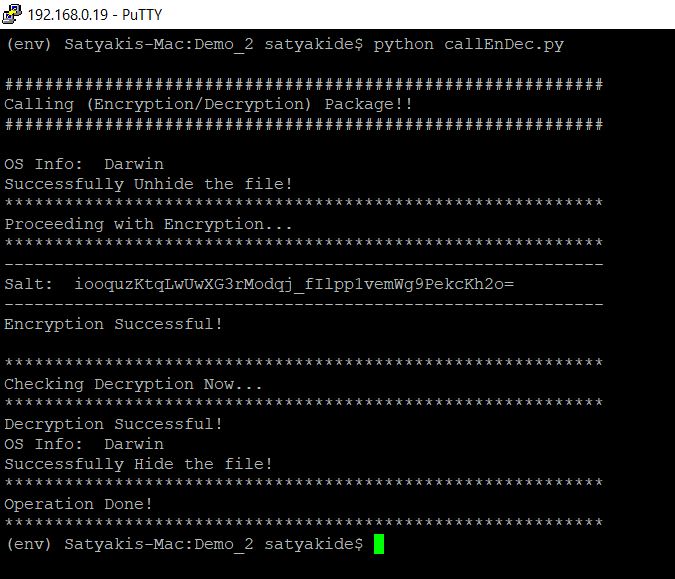
Note that you have to open two different windows or MAC terminal. One will trigger the server & others will trigger the client to simulate this.
Server:

Clients:
Win:

MAC:

So, finally, we’ve achieved our goal. So, today we’ve done a bit long but beneficial & advanced concepts of crossover stones from our python verse. 🙂
Lot more innovative posts are coming.
Till then – Happy Avenging!




























































You must be logged in to post a comment.