
Hi Guys,
Today, I’ll be using another exciting installment of Computer Vision. Our focus will be on getting a sense of human emotions. Let me explain. This post will demonstrate how to read/detect human emotions by analyzing computer vision videos. We will be using part of a Bengali Movie called “Ganashatru (An enemy of the people)” entirely for educational purposes & also as a tribute to the great legendary director late Satyajit Roy. To know more about him, please click the following link.
Why don’t we see the demo first before jumping into the technical details?
Architecture:
Let us understand the architecture –
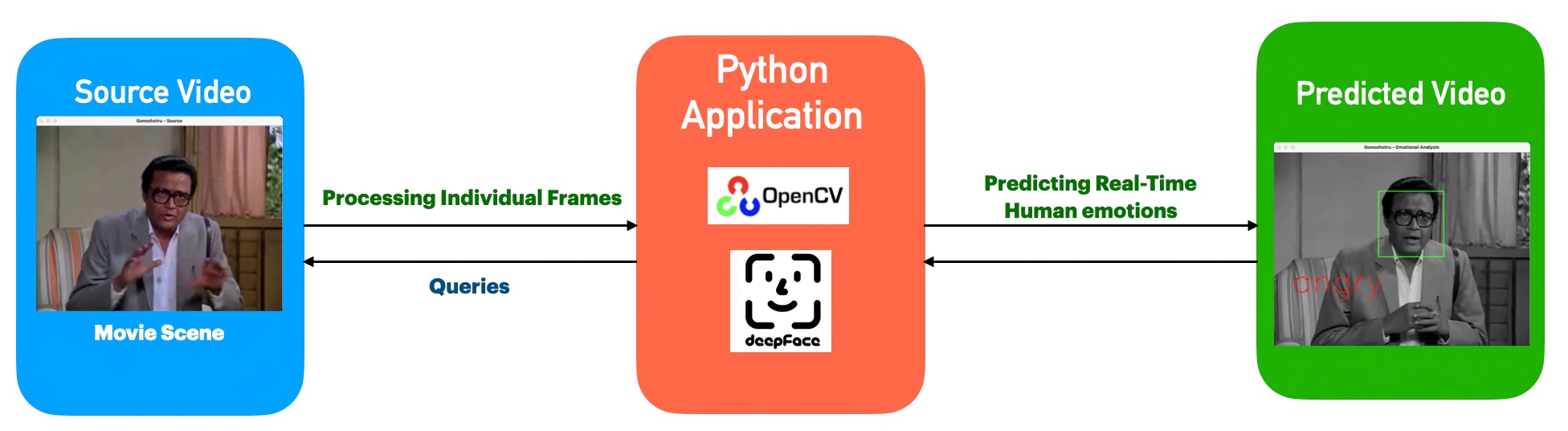
From the above diagram, one can see that the application, which uses both the Open-CV & DeepFace, analyzes individual frames from the source. Then predicts the emotions & adds the label in the target B&W frames. Finally, it creates another video by correctly mixing the source audio.
Python Packages:
Following are the python packages that are necessary to develop this brilliant use case –
pip install deepface
pip install opencv-python
pip install ffpyplayerCODE:
Let us now understand the code. For this use case, we will only discuss three python scripts. However, we need more than these three. However, we have already discussed them in some of the early posts. Hence, we will skip them here.
- clsConfig.py (This script will play the video along with audio in sync.)
This file contains hidden or bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
| ################################################ | |
| #### Written By: SATYAKI DE #### | |
| #### Written On: 15-May-2020 #### | |
| #### Modified On: 22-Apr-2022 #### | |
| #### #### | |
| #### Objective: This script is a config #### | |
| #### file, contains all the keys for #### | |
| #### Machine-Learning & streaming dashboard.#### | |
| #### #### | |
| ################################################ | |
| import os | |
| import platform as pl | |
| class clsConfig(object): | |
| Curr_Path = os.path.dirname(os.path.realpath(__file__)) | |
| os_det = pl.system() | |
| if os_det == "Windows": | |
| sep = '\\' | |
| else: | |
| sep = '/' | |
| conf = { | |
| 'APP_ID': 1, | |
| 'ARCH_DIR': Curr_Path + sep + 'arch' + sep, | |
| 'PROFILE_PATH': Curr_Path + sep + 'profile' + sep, | |
| 'LOG_PATH': Curr_Path + sep + 'log' + sep, | |
| 'REPORT_PATH': Curr_Path + sep + 'report', | |
| 'FILE_NAME': 'GonoshotruClimax', | |
| 'SRC_PATH': Curr_Path + sep + 'data' + sep, | |
| 'FINAL_PATH': Curr_Path + sep + 'Target' + sep, | |
| 'APP_DESC_1': 'Video Emotion Capture!', | |
| 'DEBUG_IND': 'N', | |
| 'INIT_PATH': Curr_Path, | |
| 'SUBDIR': 'data', | |
| 'SEP': sep, | |
| 'VIDEO_FILE_EXTN': '.mp4', | |
| 'AUDIO_FILE_EXTN': '.mp3', | |
| 'IMAGE_FILE_EXTN': '.jpg', | |
| 'TITLE': "Gonoshotru – Emotional Analysis" | |
| } |
All the above inputs are generic & used as normal parameters.
- clsFaceEmotionDetect.py (This python class will track the human emotions after splitting the audio from the video & put that label on top of the video frame.)
This file contains hidden or bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
| ################################################## | |
| #### Written By: SATYAKI DE #### | |
| #### Written On: 17-Apr-2022 #### | |
| #### Modified On 20-Apr-2022 #### | |
| #### #### | |
| #### Objective: This python class will #### | |
| #### track the human emotions after splitting #### | |
| #### the audio from the video & put that #### | |
| #### label on top of the video frame. #### | |
| #### #### | |
| ################################################## | |
| from imutils.video import FileVideoStream | |
| from imutils.video import FPS | |
| import numpy as np | |
| import imutils | |
| import time | |
| import cv2 | |
| from clsConfig import clsConfig as cf | |
| from deepface import DeepFace | |
| import clsL as cl | |
| import subprocess | |
| import sys | |
| import os | |
| # Initiating Log class | |
| l = cl.clsL() | |
| class clsFaceEmotionDetect: | |
| def __init__(self): | |
| self.sep = str(cf.conf['SEP']) | |
| self.Curr_Path = str(cf.conf['INIT_PATH']) | |
| self.FileName = str(cf.conf['FILE_NAME']) | |
| self.VideoFileExtn = str(cf.conf['VIDEO_FILE_EXTN']) | |
| self.ImageFileExtn = str(cf.conf['IMAGE_FILE_EXTN']) | |
| def convert_video_to_audio_ffmpeg(self, video_file, output_ext="mp3"): | |
| try: | |
| """Converts video to audio directly using `ffmpeg` command | |
| with the help of subprocess module""" | |
| filename, ext = os.path.splitext(video_file) | |
| subprocess.call(["ffmpeg", "-y", "-i", video_file, f"{filename}.{output_ext}"], | |
| stdout=subprocess.DEVNULL, | |
| stderr=subprocess.STDOUT) | |
| return 0 | |
| except Exception as e: | |
| x = str(e) | |
| print('Error: ', x) | |
| return 1 | |
| def readEmotion(self, debugInd, var): | |
| try: | |
| sep = self.sep | |
| Curr_Path = self.Curr_Path | |
| FileName = self.FileName | |
| VideoFileExtn = self.VideoFileExtn | |
| ImageFileExtn = self.ImageFileExtn | |
| font = cv2.FONT_HERSHEY_SIMPLEX | |
| # Load Video | |
| videoFile = Curr_Path + sep + 'Video' + sep + FileName + VideoFileExtn | |
| temp_path = Curr_Path + sep + 'Temp' + sep | |
| # Extracting the audio from the source video | |
| x = self.convert_video_to_audio_ffmpeg(videoFile) | |
| if x == 0: | |
| print('Successfully Audio extracted from the source file!') | |
| else: | |
| print('Failed to extract the source audio!') | |
| # Loading the haarcascade xml class | |
| faceCascade = cv2.CascadeClassifier(cv2.data.haarcascades + 'haarcascade_frontalface_default.xml') | |
| # start the file video stream thread and allow the buffer to | |
| # start to fill | |
| print("[INFO] Starting video file thread…") | |
| fvs = FileVideoStream(videoFile).start() | |
| time.sleep(1.0) | |
| cnt = 0 | |
| # start the FPS timer | |
| fps = FPS().start() | |
| try: | |
| # loop over frames from the video file stream | |
| while fvs.more(): | |
| cnt += 1 | |
| # grab the frame from the threaded video file stream, resize | |
| # it, and convert it to grayscale (while still retaining 3 | |
| # channels) | |
| try: | |
| frame = fvs.read() | |
| except Exception as e: | |
| x = str(e) | |
| print('Error: ', x) | |
| frame = imutils.resize(frame, width=720) | |
| cv2.imshow("Gonoshotru – Source", frame) | |
| # Enforce Detection to False will continue the sequence even when there is no face | |
| result = DeepFace.analyze(frame, enforce_detection=False, actions = ['emotion']) | |
| frame = cv2.cvtColor(frame, cv2.COLOR_BGR2GRAY) | |
| frame = np.dstack([frame, frame, frame]) | |
| faces = faceCascade.detectMultiScale(image=frame, scaleFactor=1.1, minNeighbors=4, minSize=(80,80), flags=cv2.CASCADE_SCALE_IMAGE) | |
| # Draw a rectangle around the face | |
| for (x, y, w, h) in faces: | |
| cv2.rectangle(frame, (x, y), (x + w, y + h), (0,255,0), 2) | |
| # Use puttext method for inserting live emotion on video | |
| cv2.putText(frame, result['dominant_emotion'], (50,390), font, 3, (0,0,255), 2, cv2.LINE_4) | |
| # display the size of the queue on the frame | |
| #cv2.putText(frame, "Queue Size: {}".format(fvs.Q.qsize()), (10, 30), font, 0.6, (0, 255, 0), 2) | |
| cv2.imwrite(temp_path+'frame-' + str(cnt) + ImageFileExtn, frame) | |
| # show the frame and update the FPS counter | |
| cv2.imshow("Gonoshotru – Emotional Analysis", frame) | |
| fps.update() | |
| if cv2.waitKey(2) & 0xFF == ord('q'): | |
| break | |
| except Exception as e: | |
| x = str(e) | |
| print('Error: ', x) | |
| print('No more frame exists!') | |
| # stop the timer and display FPS information | |
| fps.stop() | |
| print("[INFO] Elasped Time: {:.2f}".format(fps.elapsed())) | |
| print("[INFO] Approx. FPS: {:.2f}".format(fps.fps())) | |
| # do a bit of cleanup | |
| cv2.destroyAllWindows() | |
| fvs.stop() | |
| return 0 | |
| except Exception as e: | |
| x = str(e) | |
| print('Error: ', x) | |
| return 1 |
Key snippets from the above scripts –
def convert_video_to_audio_ffmpeg(self, video_file, output_ext="mp3"):
try:
"""Converts video to audio directly using `ffmpeg` command
with the help of subprocess module"""
filename, ext = os.path.splitext(video_file)
subprocess.call(["ffmpeg", "-y", "-i", video_file, f"{filename}.{output_ext}"],
stdout=subprocess.DEVNULL,
stderr=subprocess.STDOUT)
return 0
except Exception as e:
x = str(e)
print('Error: ', x)
return 1
The above snippet represents an Audio extraction function that will extract the audio from the source file & store it in the specified directory.
# Loading the haarcascade xml class faceCascade = cv2.CascadeClassifier(cv2.data.haarcascades + 'haarcascade_frontalface_default.xml')
Now, Loading is one of the best classes for face detection, which our applications require.
fvs = FileVideoStream(videoFile).start()
Using FileVideoStream will enable our application to process the video faster than cv2.VideoCapture() method.
# start the FPS timer fps = FPS().start()
The application then invokes the FPS.Start() that will initiate the FPS timer.
# loop over frames from the video file stream while fvs.more():
The application will check using fvs.more() to find the EOF of the video file. Until then, it will try to read individual frames.
try:
frame = fvs.read()
except Exception as e:
x = str(e)
print('Error: ', x)
The application will read individual frames. In case of any issue, it will capture the correct error without terminating the main program at the beginning. This exception strategy is beneficial when there is no longer any frame to read & yet due to the end frame issue, the entire application throws an error.
frame = imutils.resize(frame, width=720)
cv2.imshow("Gonoshotru - Source", frame)
At this point, the application is resizing the frame for better resolution & performance. Furthermore, identify this video feed as a source.
# Enforce Detection to False will continue the sequence even when there is no face result = DeepFace.analyze(frame, enforce_detection=False, actions = ['emotion'])
Finally, the application has used the deepface machine-learning API to analyze the subject face & trying to predict its emotions.
frame = cv2.cvtColor(frame, cv2.COLOR_BGR2GRAY) frame = np.dstack([frame, frame, frame]) faces = faceCascade.detectMultiScale(image=frame, scaleFactor=1.1, minNeighbors=4, minSize=(80,80), flags=cv2.CASCADE_SCALE_IMAGE)
detectMultiScale function can use to detect the faces. This function will return a rectangle with coordinates (x, y, w, h) around the detected face.
It takes three common arguments — the input image, scaleFactor, and minNeighbours.
scaleFactor specifies how much the image size reduces with each scale. There may be more faces near the camera in a group photo than others. Naturally, such faces would appear more prominent than the ones behind. This factor compensates for that.
minNeighbours specifies how many neighbors each candidate rectangle should have to retain. One may have to tweak these values to get the best results. This parameter specifies the number of neighbors a rectangle should have to be called a face.
# Draw a rectangle around the face
for (x, y, w, h) in faces:
cv2.rectangle(frame, (x, y), (x + w, y + h), (0,255,0), 2)
As discussed above, the application is now calculating the square’s boundary after receiving the values of x, y, w, & h.
# Use puttext method for inserting live emotion on video cv2.putText(frame, result['dominant_emotion'], (50,390), font, 3, (0,0,255), 2, cv2.LINE_4)
Finally, capture the dominant emotion from the deepface API & post it on top of the target video.
# display the size of the queue on the frame
cv2.imwrite(temp_path+'frame-' + str(cnt) + ImageFileExtn, frame)
# show the frame and update the FPS counter
cv2.imshow("Gonoshotru - Emotional Analysis", frame)
fps.update()
Also, writing individual frames into a temporary folder, where later they will be consumed & mixed with the source audio.
if cv2.waitKey(2) & 0xFF == ord('q'):
break
At any given point, if the user wants to quit, the above snippet will allow them by simply pressing either the escape-button or ‘q’-button from the keyboard.
- clsVideoPlay.py (This script will play the video along with audio in sync.)
This file contains hidden or bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
| ############################################### | |
| #### Updated By: SATYAKI DE #### | |
| #### Updated On: 17-Apr-2022 #### | |
| #### #### | |
| #### Objective: This script will play the #### | |
| #### video along with audio in sync. #### | |
| #### #### | |
| ############################################### | |
| import os | |
| import platform as pl | |
| import cv2 | |
| import numpy as np | |
| import glob | |
| import re | |
| import ffmpeg | |
| import time | |
| from clsConfig import clsConfig as cf | |
| from ffpyplayer.player import MediaPlayer | |
| import logging | |
| os_det = pl.system() | |
| if os_det == "Windows": | |
| sep = '\\' | |
| else: | |
| sep = '/' | |
| class clsVideoPlay: | |
| def __init__(self): | |
| self.fileNmFin = str(cf.conf['FILE_NAME']) | |
| self.final_path = str(cf.conf['FINAL_PATH']) | |
| self.title = str(cf.conf['TITLE']) | |
| self.VideoFileExtn = str(cf.conf['VIDEO_FILE_EXTN']) | |
| def videoP(self, file): | |
| try: | |
| cap = cv2.VideoCapture(file) | |
| player = MediaPlayer(file) | |
| start_time = time.time() | |
| while cap.isOpened(): | |
| ret, frame = cap.read() | |
| if not ret: | |
| break | |
| _, val = player.get_frame(show=False) | |
| if val == 'eof': | |
| break | |
| cv2.imshow(file, frame) | |
| elapsed = (time.time() – start_time) * 1000 # msec | |
| play_time = int(cap.get(cv2.CAP_PROP_POS_MSEC)) | |
| sleep = max(1, int(play_time – elapsed)) | |
| if cv2.waitKey(sleep) & 0xFF == ord("q"): | |
| break | |
| player.close_player() | |
| cap.release() | |
| cv2.destroyAllWindows() | |
| return 0 | |
| except Exception as e: | |
| x = str(e) | |
| print('Error: ', x) | |
| return 1 | |
| def stream(self, dInd, var): | |
| try: | |
| VideoFileExtn = self.VideoFileExtn | |
| fileNmFin = self.fileNmFin + VideoFileExtn | |
| final_path = self.final_path | |
| title = self.title | |
| FullFileName = final_path + fileNmFin | |
| ret = self.videoP(FullFileName) | |
| if ret == 0: | |
| print('Successfully Played the Video!') | |
| return 0 | |
| else: | |
| return 1 | |
| except Exception as e: | |
| x = str(e) | |
| print('Error: ', x) | |
| return 1 |
Let us explore the key snippet –
cap = cv2.VideoCapture(file) player = MediaPlayer(file)
In the above snippet, the application first reads the video & at the same time, it will create an instance of the MediaPlayer.
play_time = int(cap.get(cv2.CAP_PROP_POS_MSEC))
The application uses cv2.CAP_PROP_POS_MSEC to synchronize video and audio.
- peopleEmotionRead.py (This is the main calling python script that will invoke the class to initiate the model to read the real-time human emotions from video.)
This file contains hidden or bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
| ################################################## | |
| #### Written By: SATYAKI DE #### | |
| #### Written On: 17-Jan-2022 #### | |
| #### Modified On 20-Apr-2022 #### | |
| #### #### | |
| #### Objective: This is the main calling #### | |
| #### python script that will invoke the #### | |
| #### clsFaceEmotionDetect class to initiate #### | |
| #### the model to read the real-time #### | |
| #### human emotions from video or even from #### | |
| #### Web-CAM & predict it continuously. #### | |
| ################################################## | |
| # We keep the setup code in a different class as shown below. | |
| import clsFaceEmotionDetect as fed | |
| import clsFrame2Video as fv | |
| import clsVideoPlay as vp | |
| from clsConfig import clsConfig as cf | |
| import datetime | |
| import logging | |
| ############################################### | |
| ### Global Section ### | |
| ############################################### | |
| # Instantiating all the three classes | |
| x1 = fed.clsFaceEmotionDetect() | |
| x2 = fv.clsFrame2Video() | |
| x3 = vp.clsVideoPlay() | |
| ############################################### | |
| ### End of Global Section ### | |
| ############################################### | |
| def main(): | |
| try: | |
| # Other useful variables | |
| debugInd = 'Y' | |
| var = datetime.datetime.now().strftime("%Y-%m-%d_%H-%M-%S") | |
| var1 = datetime.datetime.now() | |
| print('Start Time: ', str(var)) | |
| # End of useful variables | |
| # Initiating Log Class | |
| general_log_path = str(cf.conf['LOG_PATH']) | |
| # Enabling Logging Info | |
| logging.basicConfig(filename=general_log_path + 'restoreVideo.log', level=logging.INFO) | |
| print('Started Capturing Real-Time Human Emotions!') | |
| # Execute all the pass | |
| r1 = x1.readEmotion(debugInd, var) | |
| r2 = x2.convert2Vid(debugInd, var) | |
| r3 = x3.stream(debugInd, var) | |
| if ((r1 == 0) and (r2 == 0) and (r3 == 0)): | |
| print('Successfully identified human emotions!') | |
| else: | |
| print('Failed to identify the human emotions!') | |
| var2 = datetime.datetime.now() | |
| c = var2 – var1 | |
| minutes = c.total_seconds() / 60 | |
| print('Total difference in minutes: ', str(minutes)) | |
| print('End Time: ', str(var1)) | |
| except Exception as e: | |
| x = str(e) | |
| print('Error: ', x) | |
| if __name__ == "__main__": | |
| main() |
The key-snippet from the above script are as follows –
# Instantiating all the three classes x1 = fed.clsFaceEmotionDetect() x2 = fv.clsFrame2Video() x3 = vp.clsVideoPlay()
As one can see from the above snippet, all the major classes are instantiated & loaded into the memory.
# Execute all the pass r1 = x1.readEmotion(debugInd, var) r2 = x2.convert2Vid(debugInd, var) r3 = x3.stream(debugInd, var)
All the responses are captured into the corresponding variables, which later check for success status.
Let us capture & compare the emotions in a screenshot for better understanding –

So, one can see that most of the frames from the video & above-posted frame correctly identify the human emotions.
FOLDER STRUCTURE:
Here is the folder structure that contains all the files & directories in MAC O/S –
So, we’ve done it.
You will get the complete codebase in the following Github link.
If you want to know more about this legendary director & his famous work, please visit the following link.
I’ll bring some more exciting topic in the coming days from the Python verse. Please share & subscribe my post & let me know your feedback.
Till then, Happy Avenging! 😀
Note: All the data & scenario posted here are representational data & scenarios & available over the internet & for educational purpose only. Some of the images (except my photo) that we’ve used are available over the net. We don’t claim the ownership of these images. There is an always room for improvement & especially the prediction quality.















You must be logged in to post a comment.