I’ve been looking for a solution that can help deploy any RAG solution involving Python faster. It would be more effective if an available UI helped deliver the solution faster. And, here comes the solution that does exactly what I needed – “LangFlow.”
Before delving into the details, I strongly recommend taking a look at the demo. It’s a great way to get a comprehensive understanding of LangFlow and its capabilities in deploying RAG architecture rapidly.
This describes the entire architecture; hence, I’ll share the architecture components I used to build the solution.
To know more about RAG-Architecture, please refer to the following link.
As we all know, we can parse the data from the source website URL (in this case, I’m referring to my photography website to extract the text of one of my blogs) and then embed it into the newly created Astra DB & new collection, where I will be storing the vector embeddings.

As you can see from the above diagram, the flow that I configured within 5 minutes and the full functionality of writing a complete solution (underlying Python application) within no time that extracts chunks, converts them into embeddings, and finally stores them inside the Astra DB.
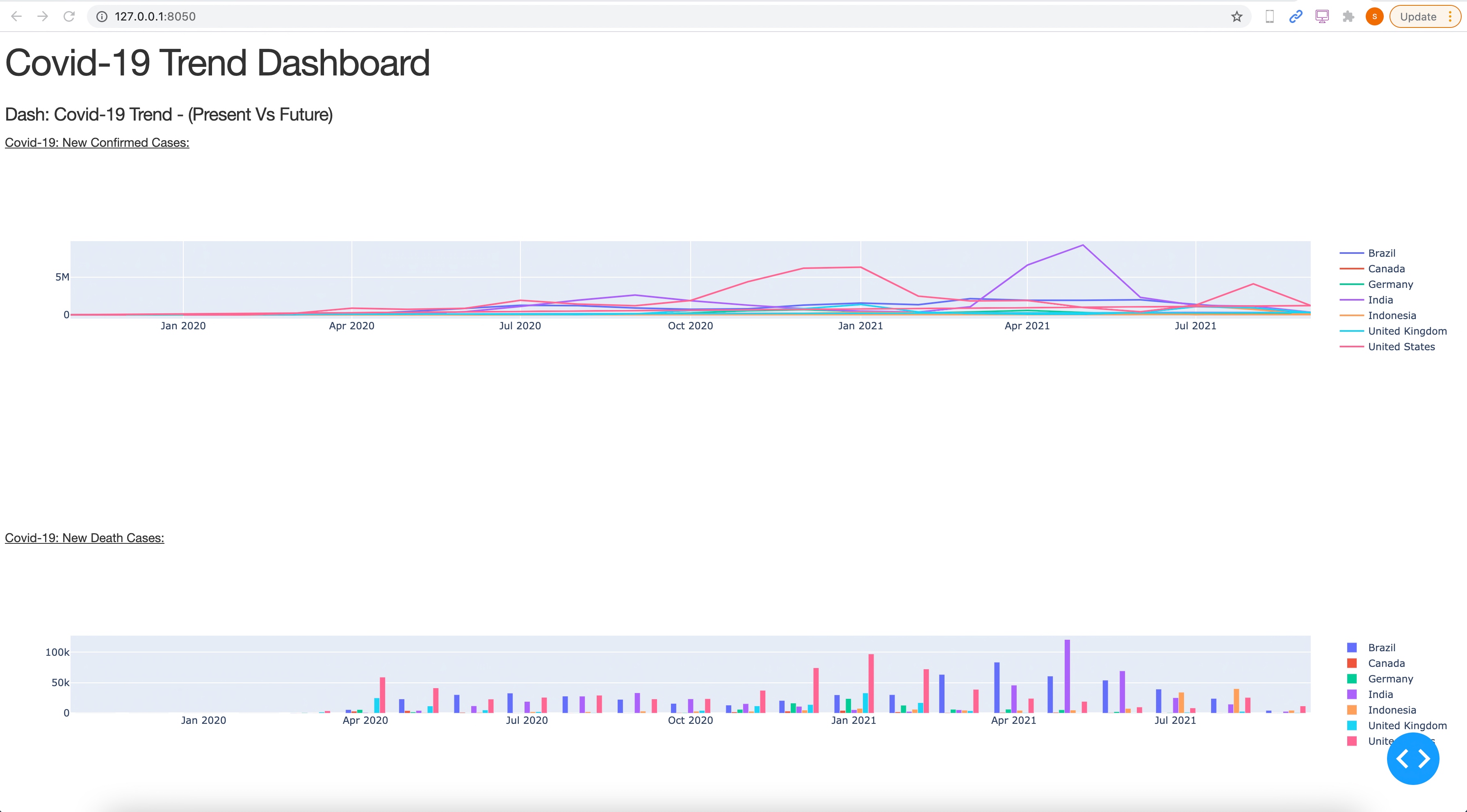
Now, let us understand the next phase, where, based on the ask from a chatbot, I need to convert that question into Vector DB & then find the similarity search to bring the relevant vectors as shown below –

You need to configure this entire flow by dragging the necessary widgets from the left-side panel as marked in the Blue-Box shown below –

For this specific use case, we’ve created an instance of Astra DB & then created an empty vector collection. Also, we need to ensure that we generate the API-Key & and provide the right roles assigned with the token. After successfully creating the token, you need to copy the endpoint, token & collection details & paste them into the desired fields of the Astra-DB components inside the LangFlow. Think of it as a framework where one needs to provide all the necessary information to build & run the entire flow successfully.
Following are some of the important snapshots from the Astra-DB –
Step – 1

Step – 2

Once you run the vector DB population, this will insert extracted text & then convert it into vectors, which will show in the following screenshot –

You can see the sample vectors along with the text chunks inside the Astra DB data explorer as shown below –

Some of the critical components are highlighted in the Blue-box which is important for us to monitor the vector embeddings.
Now, here is how you can modify the current Python code of any available widgets or build your own widget by using the custom widget.
The first step is to click the code button highlighted in the Red-box as shown below –

The next step is when you click that button, which will open the detailed Python code representing the entire widget build & its functionality. This button is the place where you can add, modify, or keep it as it is depending upon your need, which will shown below –

Once one builds the entire solution, you must click the final compile button (shown in the red box), which will eventually compile all the individual widgets. However, you can build the compile button for the individual widgets as soon as you make the solution. So you can pinpoint any potential problems at that very step.

Let us understand one sample code of a widget. In this case, we will take vector embedding insertion into the Astra DB. Let us see the code –
from typing import List, Optional, Union
from langchain_astradb import AstraDBVectorStore
from langchain_astradb.utils.astradb import SetupMode
from langflow.custom import CustomComponent
from langflow.field_typing import Embeddings, VectorStore
from langflow.schema import Record
from langchain_core.retrievers import BaseRetriever
class AstraDBVectorStoreComponent(CustomComponent):
display_name = "Astra DB"
description = "Builds or loads an Astra DB Vector Store."
icon = "AstraDB"
field_order = ["token", "api_endpoint", "collection_name", "inputs", "embedding"]
def build_config(self):
return {
"inputs": {
"display_name": "Inputs",
"info": "Optional list of records to be processed and stored in the vector store.",
},
"embedding": {"display_name": "Embedding", "info": "Embedding to use"},
"collection_name": {
"display_name": "Collection Name",
"info": "The name of the collection within Astra DB where the vectors will be stored.",
},
"token": {
"display_name": "Token",
"info": "Authentication token for accessing Astra DB.",
"password": True,
},
"api_endpoint": {
"display_name": "API Endpoint",
"info": "API endpoint URL for the Astra DB service.",
},
"namespace": {
"display_name": "Namespace",
"info": "Optional namespace within Astra DB to use for the collection.",
"advanced": True,
},
"metric": {
"display_name": "Metric",
"info": "Optional distance metric for vector comparisons in the vector store.",
"advanced": True,
},
"batch_size": {
"display_name": "Batch Size",
"info": "Optional number of records to process in a single batch.",
"advanced": True,
},
"bulk_insert_batch_concurrency": {
"display_name": "Bulk Insert Batch Concurrency",
"info": "Optional concurrency level for bulk insert operations.",
"advanced": True,
},
"bulk_insert_overwrite_concurrency": {
"display_name": "Bulk Insert Overwrite Concurrency",
"info": "Optional concurrency level for bulk insert operations that overwrite existing records.",
"advanced": True,
},
"bulk_delete_concurrency": {
"display_name": "Bulk Delete Concurrency",
"info": "Optional concurrency level for bulk delete operations.",
"advanced": True,
},
"setup_mode": {
"display_name": "Setup Mode",
"info": "Configuration mode for setting up the vector store, with options like “Sync”, “Async”, or “Off”.",
"options": ["Sync", "Async", "Off"],
"advanced": True,
},
"pre_delete_collection": {
"display_name": "Pre Delete Collection",
"info": "Boolean flag to determine whether to delete the collection before creating a new one.",
"advanced": True,
},
"metadata_indexing_include": {
"display_name": "Metadata Indexing Include",
"info": "Optional list of metadata fields to include in the indexing.",
"advanced": True,
},
"metadata_indexing_exclude": {
"display_name": "Metadata Indexing Exclude",
"info": "Optional list of metadata fields to exclude from the indexing.",
"advanced": True,
},
"collection_indexing_policy": {
"display_name": "Collection Indexing Policy",
"info": "Optional dictionary defining the indexing policy for the collection.",
"advanced": True,
},
}
def build(
self,
embedding: Embeddings,
token: str,
api_endpoint: str,
collection_name: str,
inputs: Optional[List[Record]] = None,
namespace: Optional[str] = None,
metric: Optional[str] = None,
batch_size: Optional[int] = None,
bulk_insert_batch_concurrency: Optional[int] = None,
bulk_insert_overwrite_concurrency: Optional[int] = None,
bulk_delete_concurrency: Optional[int] = None,
setup_mode: str = "Sync",
pre_delete_collection: bool = False,
metadata_indexing_include: Optional[List[str]] = None,
metadata_indexing_exclude: Optional[List[str]] = None,
collection_indexing_policy: Optional[dict] = None,
) -> Union[VectorStore, BaseRetriever]:
try:
setup_mode_value = SetupMode[setup_mode.upper()]
except KeyError:
raise ValueError(f"Invalid setup mode: {setup_mode}")
if inputs:
documents = [_input.to_lc_document() for _input in inputs]
vector_store = AstraDBVectorStore.from_documents(
documents=documents,
embedding=embedding,
collection_name=collection_name,
token=token,
api_endpoint=api_endpoint,
namespace=namespace,
metric=metric,
batch_size=batch_size,
bulk_insert_batch_concurrency=bulk_insert_batch_concurrency,
bulk_insert_overwrite_concurrency=bulk_insert_overwrite_concurrency,
bulk_delete_concurrency=bulk_delete_concurrency,
setup_mode=setup_mode_value,
pre_delete_collection=pre_delete_collection,
metadata_indexing_include=metadata_indexing_include,
metadata_indexing_exclude=metadata_indexing_exclude,
collection_indexing_policy=collection_indexing_policy,
)
else:
vector_store = AstraDBVectorStore(
embedding=embedding,
collection_name=collection_name,
token=token,
api_endpoint=api_endpoint,
namespace=namespace,
metric=metric,
batch_size=batch_size,
bulk_insert_batch_concurrency=bulk_insert_batch_concurrency,
bulk_insert_overwrite_concurrency=bulk_insert_overwrite_concurrency,
bulk_delete_concurrency=bulk_delete_concurrency,
setup_mode=setup_mode_value,
pre_delete_collection=pre_delete_collection,
metadata_indexing_include=metadata_indexing_include,
metadata_indexing_exclude=metadata_indexing_exclude,
collection_indexing_policy=collection_indexing_policy,
)
return vector_store
Method: build_config:
- This method defines the configuration options for the component.
- Each configuration option includes a display_name and info, which provides details about the option.
- Some options are marked as advanced, indicating they are optional and more complex.
Method: build:
- This method is used to create an instance of the Astra DB Vector Store.
- It takes several parameters, including embedding, token, api_endpoint, collection_name, and various optional parameters.
- It converts the setup_mode string to an enum value.
- If inputs are provided, they are converted to a format suitable for storing in the vector store.
- Depending on whether inputs are provided, a new vector store from documents can be created, or an empty vector store can be initialized with the given configurations.
- Finally, it returns the created vector store instance.
And, here is the the screenshot of your run –

And, this is the last steps to run the Integrated Chatbot as shown below –
Step – 1

Step – 2

As one can see the left side highlighted shows the reference text & chunks & the right side actual response.
So, we’ve done it. And, you know the fun fact. I did this entire workflow within 35 minutes alone. 😛
I’ll bring some more exciting topics in the coming days from the Python verse.
To learn more about LangFlow, please click here.
To learn about Astra DB, you need to click the following link.
To learn about my blog & photography, you can click the following url.
Till then, Happy Avenging! 🙂
Note: All the data & scenarios posted here are representational data & scenarios & available over the internet & for educational purposes only. There is always room for improvement in this kind of model & the solution associated with it. I’ve shown the basic ways to achieve the same for educational purposes only.













You must be logged in to post a comment.