Hi Guys,
Today, we’ll be looking into another exciting installment of cross-over between Reality Stone & Timestone from the python verse.
We’ll be exploring Encryption/Decryption implemented using the Flask Framework Server component. We would like to demonstrate this Encrypt/Decrypt features as Server API & then we can call it from clients like Postman to view the response.
So, here are primary focus will be implementing this in Server-side rather than the client-side.
However, there is a catch. We would like to implement different kind of encryption or decryption based on our source data.
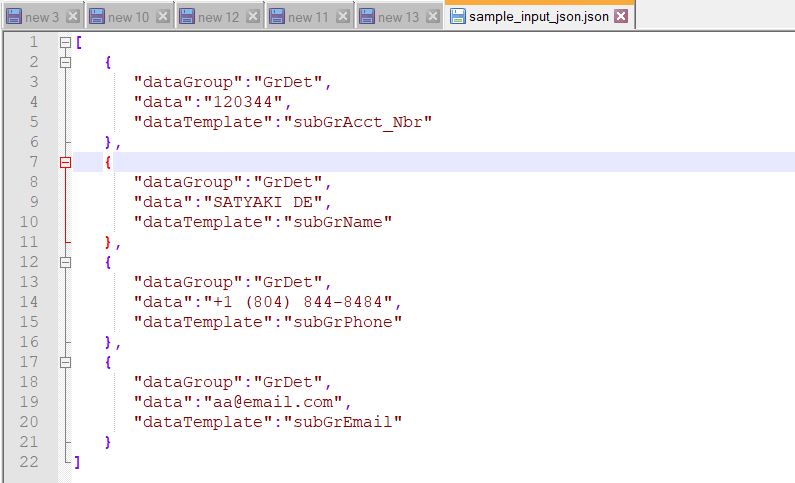
Let’s look into the sample data first –

As you can see, we intend to encrypt Account Number encryption with different salt compared to Name or Phone or Email. Hence, we would be using different salt to encrypt our sample data & get the desired encrypt/decrypt output.
From the above data, we can create the following types of JSON payload –
Let’s explore –
Before we start, we would like to show you the directory structure of Windows & MAC as we did the same in my earlier post as well.

Following are the scripts that we’re using to develop this server applications & they are as follows –
1. clsConfigServer.py (This script contains all the parameters of the server.)
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 |
########################################### #### Written By: SATYAKI DE ######## #### Written On: 10-Feb-2019 ######## #### ######## #### Objective: Parameter File ######## ########################################### import os import platform as pl # Checking with O/S system os_det = pl.system() class clsConfigServer(object): Curr_Path = os.path.dirname(os.path.realpath(__file__)) if os_det == "Windows": config = { 'FILE': 'acct_addr_20180112.csv', 'SRC_FILE_PATH': Curr_Path + '\\' + 'src_file\\', 'PROFILE_FILE_PATH': Curr_Path + '\\' + 'profile\\', 'HOST_IP_ADDR': '0.0.0.0', 'DEF_SALT': 'iooquzKtqLwUwXG3rModqj_fIl409vemWg9PekcKh2o=', 'ACCT_NBR_SALT': 'iooquzKtqLwUwXG3rModqj_fIlpp1vemWg9PekcKh2o=', 'NAME_SALT': 'iooquzKtqLwUwXG3rModqj_fIlpp1026Wg9PekcKh2o=', 'PHONE_SALT': 'iooquzKtqLwUwXG3rMM0F5_fIlpp1026Wg9PekcKh2o=', 'EMAIL_SALT': 'iooquzKtqLwU0653rMM0F5_fIlpp1026Wg9PekcKh2o=' } else: config = { 'FILE': 'acct_addr_20180112.csv', 'SRC_FILE_PATH': Curr_Path + '/' + 'src_file/', 'PROFILE_FILE_PATH': Curr_Path + '/' + 'profile/', 'HOST_IP_ADDR': '0.0.0.0', 'DEF_SALT': 'iooquzKtqLwUwXG3rModqj_fIl409vemWg9PekcKh2o=', 'ACCT_NBR_SALT': 'iooquzKtqLwUwXG3rModqj_fIlpp1vemWg9PekcKh2o=', 'NAME_SALT': 'iooquzKtqLwUwXG3rModqj_fIlpp1026Wg9PekcKh2o=', 'PHONE_SALT': 'iooquzKtqLwUwXG3rMM0F5_fIlpp1026Wg9PekcKh2o=', 'EMAIL_SALT': 'iooquzKtqLwU0653rMM0F5_fIlpp1026Wg9PekcKh2o=' } |
Key things to monitor –
'ACCT_NBR_SALT': 'iooquzKtqLwUwXG3rModqj_fIlpp1vemWg9PekcKh2o=', 'NAME_SALT': 'iooquzKtqLwUwXG3rModqj_fIlpp1026Wg9PekcKh2o=', 'PHONE_SALT': 'iooquzKtqLwUwXG3rMM0F5_fIlpp1026Wg9PekcKh2o=', 'EMAIL_SALT': 'iooquzKtqLwU0653rMM0F5_fIlpp1026Wg9PekcKh2o='
As mentioned, the different salt key’s defined for different kind of data.
2. clsEnDec.py (This script is a lighter version of encryption & decryption of our previously discussed script. Hence, we won’t discuss in details. You can refer my earlier post to understand the logic of this script.)
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 |
########################################### #### Written By: SATYAKI DE ######## #### Written On: 25-Jan-2019 ######## #### Package Cryptography needs to ######## #### install in order to run this ######## #### script. ######## #### ######## #### Objective: This script will ######## #### encrypt/decrypt based on the ######## #### hidden supplied salt value. ######## ########################################### from cryptography.fernet import Fernet class clsEnDec(object): def __init__(self, token): # Calculating Key self.token = token def encrypt_str(self, data): try: # Capturing the Salt Information salt = self.token # Checking Individual Types inside the Dataframe cipher = Fernet(salt) encr_val = str(cipher.encrypt(bytes(data,'utf8'))).replace("b'","").replace("'","") return encr_val except Exception as e: x = str(e) print(x) encr_val = '' return encr_val def decrypt_str(self, data): try: # Capturing the Salt Information salt = self.token # Checking Individual Types inside the Dataframe cipher = Fernet(salt) decr_val = str(cipher.decrypt(bytes(data,'utf8'))).replace("b'","").replace("'","") return decr_val except Exception as e: x = str(e) print(x) decr_val = '' return decr_val |
3. clsFlask.py (This is the main server script that will the encrypt/decrypt class from our previous script. This script will capture the requested JSON from the client, who posted from the clients like another python script or third-party tools like Postman.)
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 |
########################################### #### Written By: SATYAKI DE #### #### Written On: 25-Jan-2019 #### #### Package Flask package needs to #### #### install in order to run this #### #### script. #### #### #### #### Objective: This script will #### #### encrypt/decrypt based on the #### #### supplied salt value. Also, #### #### this will capture the individual #### #### element & stored them into JSON #### #### variables using flask framework. #### ########################################### from clsConfigServer import clsConfigServer as csf import clsEnDec as cen class clsFlask(object): def __init__(self): self.xtoken = str(csf.config['DEF_SALT']) def getEncryptProcess(self, dGroup, input_data, dTemplate): try: # It is sending default salt value xtoken = self.xtoken # Capturing the individual element dGroup = dGroup input_data = input_data dTemplate = dTemplate # This will check the mandatory json elements if ((dGroup != '') & (dTemplate != '')): # Based on the Group & Element it will fetch the salt # Based on the specific salt it will encrypt the data if ((dGroup == 'GrDet') & (dTemplate == 'subGrAcct_Nbr')): xtoken = str(csf.config['ACCT_NBR_SALT']) print("xtoken: ", xtoken) print("Flask Input Data: ", input_data) x = cen.clsEnDec(xtoken) ret_val = x.encrypt_str(input_data) elif ((dGroup == 'GrDet') & (dTemplate == 'subGrName')): xtoken = str(csf.config['NAME_SALT']) print("xtoken: ", xtoken) print("Flask Input Data: ", input_data) x = cen.clsEnDec(xtoken) ret_val = x.encrypt_str(input_data) elif ((dGroup == 'GrDet') & (dTemplate == 'subGrPhone')): xtoken = str(csf.config['PHONE_SALT']) print("xtoken: ", xtoken) print("Flask Input Data: ", input_data) x = cen.clsEnDec(xtoken) ret_val = x.encrypt_str(input_data) elif ((dGroup == 'GrDet') & (dTemplate == 'subGrEmail')): xtoken = str(csf.config['EMAIL_SALT']) print("xtoken: ", xtoken) print("Flask Input Data: ", input_data) x = cen.clsEnDec(xtoken) ret_val = x.encrypt_str(input_data) else: ret_val = '' else: ret_val = '' # Return value return ret_val except Exception as e: ret_val = '' # Return the valid json Error Response return ret_val def getDecryptProcess(self, dGroup, input_data, dTemplate): try: xtoken = self.xtoken # Capturing the individual element dGroup = dGroup input_data = input_data dTemplate = dTemplate # This will check the mandatory json elements if ((dGroup != '') & (dTemplate != '')): # Based on the Group & Element it will fetch the salt # Based on the specific salt it will decrypt the data if ((dGroup == 'GrDet') & (dTemplate == 'subGrAcct_Nbr')): xtoken = str(csf.config['ACCT_NBR_SALT']) print("xtoken: ", xtoken) print("Flask Input Data: ", input_data) x = cen.clsEnDec(xtoken) ret_val = x.decrypt_str(input_data) elif ((dGroup == 'GrDet') & (dTemplate == 'subGrName')): xtoken = str(csf.config['NAME_SALT']) print("xtoken: ", xtoken) print("Flask Input Data: ", input_data) x = cen.clsEnDec(xtoken) ret_val = x.decrypt_str(input_data) elif ((dGroup == 'GrDet') & (dTemplate == 'subGrPhone')): xtoken = str(csf.config['PHONE_SALT']) print("xtoken: ", xtoken) print("Flask Input Data: ", input_data) x = cen.clsEnDec(xtoken) ret_val = x.decrypt_str(input_data) elif ((dGroup == 'GrDet') & (dTemplate == 'subGrEmail')): xtoken = str(csf.config['EMAIL_SALT']) print("xtoken: ", xtoken) print("Flask Input Data: ", input_data) x = cen.clsEnDec(xtoken) ret_val = x.decrypt_str(input_data) else: ret_val = '' else: ret_val = '' # Return value return ret_val except Exception as e: ret_val = '' # Return the valid Error Response return ret_val |
Key lines to check –
# This will check the mandatory json elements if ((dGroup != '') & (dTemplate != '')):
Encrypt & Decrypt will only work on the data when the key element contains valid values. In this case, we are looking for values stored in dGroup & dTemplate, which will denote the specific encryption type.
# Based on the Group & Element it will fetch the salt # Based on the specific salt it will encrypt the data if ((dGroup == 'GrDet') & (dTemplate == 'subGrAcct_Nbr')): xtoken = str(csf.config['ACCT_NBR_SALT']) print("xtoken: ", xtoken) print("Flask Input Data: ", input_data) x = cen.clsEnDec(xtoken) ret_val = x.encrypt_str(input_data) elif ((dGroup == 'GrDet') & (dTemplate == 'subGrName')): xtoken = str(csf.config['NAME_SALT']) print("xtoken: ", xtoken) print("Flask Input Data: ", input_data) x = cen.clsEnDec(xtoken) ret_val = x.encrypt_str(input_data) elif ((dGroup == 'GrDet') & (dTemplate == 'subGrPhone')): xtoken = str(csf.config['PHONE_SALT']) print("xtoken: ", xtoken) print("Flask Input Data: ", input_data) x = cen.clsEnDec(xtoken) ret_val = x.encrypt_str(input_data) elif ((dGroup == 'GrDet') & (dTemplate == 'subGrEmail')): xtoken = str(csf.config['EMAIL_SALT']) print("xtoken: ", xtoken) print("Flask Input Data: ", input_data) x = cen.clsEnDec(xtoken) ret_val = x.encrypt_str(input_data)
Here, as you can see that based on dGroup & dTemplate, the application is using specific salt to encrypt or decrypt the corresponding data. Highlighted dark brown showed a particular salt against dGroup & dTemplate.
4. callRunServer.py (This script will create an instance of Flask Server & serve encrypt/decrypt facilities & act as an endpoint or server API & provide the response made to it by clients such as another python or any third-party application.)
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 |
############################################ #### Written By: SATYAKI DE #### #### Written On: 10-Feb-2019 #### #### Package Flask package needs to #### #### install in order to run this #### #### script. #### #### #### #### Objective: This script will #### #### initiate the encrypt/decrypt class #### #### based on client supplied data. #### #### Also, this will create an instance #### #### of the server & create an endpoint #### #### or API using flask framework. #### ############################################ from flask import Flask from flask import jsonify from flask import request from flask import abort from clsConfigServer import clsConfigServer as csf import clsFlask as clf app = Flask(__name__) @app.route('/process/getEncrypt', methods=['POST']) def getEncrypt(): try: # If the server application doesn't have # valid json, it will throw 400 error if not request.get_json: abort(400) # Capturing the individual element content = request.get_json() dGroup = content['dataGroup'] input_data = content['data'] dTemplate = content['dataTemplate'] # For debug purpose only print("-" * 157) print("Group: ", dGroup) print("Data: ", input_data) print("Template: ", dTemplate) print("-" * 157) ret_val = '' if ((dGroup != '') & (dTemplate != '')): y = clf.clsFlask() ret_val = y.getEncryptProcess(dGroup, input_data, dTemplate) else: abort(500) return jsonify({'status': 'success', 'encrypt_val': ret_val}) except Exception as e: x = str(e) return jsonify({'status': 'error', 'detail': x}) @app.route('/process/getDecrypt', methods=['POST']) def getDecrypt(): try: # If the server application doesn't have # valid json, it will throw 400 error if not request.get_json: abort(400) # Capturing the individual element content = request.get_json() dGroup = content['dataGroup'] input_data = content['data'] dTemplate = content['dataTemplate'] # For debug purpose only print("-" * 157) print("Group: ", dGroup) print("Data: ", input_data) print("Template: ", dTemplate) print("-" * 157) ret_val = '' if ((dGroup != '') & (dTemplate != '')): y = clf.clsFlask() ret_val = y.getDecryptProcess(dGroup, input_data, dTemplate) else: abort(500) return jsonify({'status': 'success', 'decrypt_val': ret_val}) except Exception as e: x = str(e) return jsonify({'status': 'error', 'detail': x}) def main(): try: print('Starting Encrypt/Decrypt Application!') # Calling Server Start-Up Script app.run(debug=True, host=str(csf.config['HOST_IP_ADDR'])) ret_val = 0 if ret_val == 0: print("Finished Returning Message!") else: raise IOError except Exception as e: print("Server Failed To Start!") if __name__ == '__main__': main() |
Keycode to discuss –
Encrypt:
@app.route('/process/getEncrypt', methods=['POST']) def getEncrypt():
Decrypt:
@app.route('/process/getDecrypt', methods=['POST']) def getDecrypt():
Based on the path & method, this will trigger either encrypt or decrypt methods.
# If the server application doesn't have # valid json, it will throw 400 error if not request.get_json: abort(400)
As the comments suggested, this will check whether the sample data send to the server application is a valid JSON or not. And, based on that, it will proceed or abort the request & send the response back to the client.
# Capturing the individual element content = request.get_json() dGroup = content['dataGroup'] input_data = content['data'] dTemplate = content['dataTemplate']
Here, the application is capturing the json into individual elements.
if ((dGroup != '') & (dTemplate != '')): y = clf.clsFlask() ret_val = y.getEncryptProcess(dGroup, input_data, dTemplate) else: abort(500)
The server will process only when both the dGroup & dTemplate will contains no null values. The same logic is applicable for both the encrypt & decrypt process.
return jsonify({'status': 'success', 'encrypt_val': ret_val}) except Exception as e: x = str(e) return jsonify({'status': 'error', 'detail': x})
If the process is successful, then it will send a json response, or else it will return json with error details. Similar logic is applicable for decrypt as well.
app.run(debug=True, host=str(csf.config['HOST_IP_ADDR']))
Based on the supplied IP address from our configuration file, this server will create an instance on that specific IP address when triggers. Please refer clsConfigServer.py for particular parameter values.
Let’s run the server application & see the debug encrypt & decrypt screen looks from the server-side –
Windows (64 bit):

And, we’re using Postman Third-party app to invoke this & please find the authentication details & JSON Payload for encrypting are as follows –


Let’s see the decrypt from the server-side & how it looks like from the Postman –


Mac (32 bit):
Let’s look from MAC’s perspective & how the encryption debug looks like from the server.

Please find the screen from postman along with the necessary authentication –


Let’s discover how the decrypt looks like both from server & Postman as well –


So, from this post, we’ve achieved our goal. We’ve successfully demonstrated of a creating a server component using Flask framework & we’ve incorporated our custom encryption/decryption script to create a simulated API for the third-party clients or any other application.
Hope, you will like this approach.
Let me know your comment on the same.
I’ll bring some more exciting topic in the coming days from the Python verse.
Till then, Happy Avenging!
You must be logged in to post a comment.