
Hi Guys!
Today, we’ll be discussing a preview features from Microsoft Azure. Building an Azure function using Python on it’s Linux/Ubuntu VM. Since this is a preview feature, we cannot implement this to production till now. However, my example definitely has more detailed steps & complete code guide compared to whatever available over the internet.
In this post, I will take one of my old posts & enhance it as per this post. Hence, I’ll post those modified scripts. However, I won’t discuss the logic in details as most of these scripts have cosmetic changes to cater to this requirement.
In this post, we’ll only show Ubuntu run & there won’t be Windows or MAC comparison.
Initial Environment Preparation:
- Set-up new virtual machine on Azure.
- Set-up Azure function environments on that server.
Set-up new virtual machine on Azure:
I’m not going into the details of how to create Ubuntu VM on Microsoft Azure. You can refer the steps in more information here.
After successful creation, the VM will look like this –

Detailed information you can get after clicking this hyperlink over the name of the VM.

You have to open port 7071 for application testing from the local using postman.
You can get it from the network option under VM as follows –

Make sure that you are restricting these ports to specific network & not open to ALL traffic.
So, your VM is ready now.
To update Azure CLI, you need to use the following commands –
sudo apt-get update && sudo apt-get install –only-upgrade -y azure-cli
Set-up Azure function environments on that server:
To set-up the environment, you don’t have to go for Python installation as by default Ubuntu in Microsoft Azure comes up with desired Python version, i.e., Python3.6. However, to run the python application, you need to install the following app –
- Microsoft SDK. You will get the details from this link.
- Installing node-js. You will get the details from this link.
- You need to install a docker. However, as per Microsoft official version, this is not required. But, you can create a Docker container to distribute the python function in Azure application. I would say you can install this just in case if you want to continue with this approach. You will get the details over here. If you want to know details about the Docker. And, how you want to integrate python application. You can refer to this link.
- Your desired python packages. In this case, we’ll be modifying this post – “Encryption/Decryption, JSON, API, Flask Framework in Python (Crossover between Reality Stone & Time Stone in Python Verse).” We’ll be modifying a couple of lines only to cater to this functionality & deploying the same as an Azure function.
- Creating an Azure function template on Ubuntu. The essential detail you’ll get it from here. However, over there, it was not shown in detailed steps of python packages & how you can add all the dependencies to publish it in details. It was an excellent post to start-up your knowledge.
Let’s see these components status & very brief details –
Microsoft SDK:
To check the dot net version. You need to type the following commands in Ubuntu –
dotnet –info
And, the output will look like this –

Node-Js:
Following is the way to verify your node-js version & details –
node -v
npm -v
And, the output looks like this –

Docker:
Following is the way to test your docker version –
docker -v
And, the output will look like this –

Python Packages:
Following are the python packages that we need to run & publish that in Azure cloud as an Azure function –
pip freeze | grep -v “pkg-resources” > requirements.txt
And, the output is –

You must be wondered that why have I used this grep commands here. I’ve witnessed that on many occassion in Microsoft Azure’s Linux VM it produces one broken package called resource=0.0.0, which will terminate the deployment process. Hence, this is very crucial to eliminate those broken packages.
Now, we’re ready for our python scripts. But, before that, let’s see the directory structure over here –

Creating an Azure Function Template on Ubuntu:
Before we post our python scripts, we’ll create these following components, which is essential for our Python-based Azure function –
- Creating a group:
Creating a group either through Azure CLI or using a docker, you can proceed. The commands for Azure CLI is as follows –
az group create –name “rndWestUSGrp” –location westus
It is advisable to use double quotes for parameters value. Otherwise, you might land-up getting the following error – “Error: “resourceGroupName” should satisfy the constraint – “Pattern”: /^[-w._]+$/“.
I’m sure. You don’t want to face that again. And, here is the output –

Note that, here I haven’t used the double-quotes. But, to avoid any unforeseen issues – you should use double-quotes. You can refer the docker command from the above link, which I’ve shared earlier.
Now, you need to create one storage account where the metadata information of your function will be stored. You will create that as follows –
az storage account create –name cryptpy2019 –location westus –resource-group rndWestUSGrp –sku Standard_LRS
And, the output will look like this –

Great. Now, we’ll create a virtual environment for Python3.6.
python3.6 -m venv .env
source .env/bin/activate

Now, we’ll create a local function project.
func init encPro
And, the output you will get is as follows –

Inside this directory, you’ll see the following files –

You need to edit the host.json with these default lines –
{
“version”: “2.0”,
“extensionBundle”: {
“id”: “Microsoft.Azure.Functions.ExtensionBundle”,
“version”: “[1.*, 2.0.0)”
}
}
And, the final content of these two files (excluding the requirements.txt) will look like this –

Finally, we’ll create the template function by this following command –
func new
This will follow with steps finish it. You need to choose Python as your programing language. You need to choose an HTTP trigger template. Once you created that successfully, you’ll see the following files –

Note that, our initial function name is -> getVal.
By default, Azure will generate some default code inside the __init__.py. The details of those two files can be found here.
Since we’re ready with our environment setup. We can now discuss our Python scripts –
1. clsConfigServer.py (This script contains all the parameters of the server.)
###########################################
#### Written By: SATYAKI DE ########
#### Written On: 10-Feb-2019 ########
#### ########
#### Objective: Parameter File ########
###########################################
import os
import platform as pl
# Checking with O/S system
os_det = pl.system()
class clsConfigServer(object):
Curr_Path = os.path.dirname(os.path.realpath(__file__))
if os_det == "Windows":
config = {
'FILE': 'acct_addr_20180112.csv',
'SRC_FILE_PATH': Curr_Path + '\\' + 'src_file\\',
'PROFILE_FILE_PATH': Curr_Path + '\\' + 'profile\\',
'HOST_IP_ADDR': '0.0.0.0',
'DEF_SALT': 'iooquzKtqLwUwXG3rModqj_fIl409vemWg9PekcKh2o=',
'ACCT_NBR_SALT': 'iooquzKtqLwUwXG3rModqj_fIlpp1vemWg9PekcKh2o=',
'NAME_SALT': 'iooquzKtqLwUwXG3rModqj_fIlpp1026Wg9PekcKh2o=',
'PHONE_SALT': 'iooquzKtqLwUwXG3rMM0F5_fIlpp1026Wg9PekcKh2o=',
'EMAIL_SALT': 'iooquzKtqLwU0653rMM0F5_fIlpp1026Wg9PekcKh2o='
}
else:
config = {
'FILE': 'acct_addr_20180112.csv',
'SRC_FILE_PATH': Curr_Path + '/' + 'src_file/',
'PROFILE_FILE_PATH': Curr_Path + '/' + 'profile/',
'HOST_IP_ADDR': '0.0.0.0',
'DEF_SALT': 'iooquzKtqLwUwXG3rModqj_fIl409vemWg9PekcKh2o=',
'ACCT_NBR_SALT': 'iooquzKtqLwUwXG3rModqj_fIlpp1vemWg9PekcKh2o=',
'NAME_SALT': 'iooquzKtqLwUwXG3rModqj_fIlpp1026Wg9PekcKh2o=',
'PHONE_SALT': 'iooquzKtqLwUwXG3rMM0F5_fIlpp1026Wg9PekcKh2o=',
'EMAIL_SALT': 'iooquzKtqLwU0653rMM0F5_fIlpp1026Wg9PekcKh2o='
}
2. clsEnDec.py (This script is a lighter version of encryption & decryption of our previously discussed scenario. Hence, we won’t discuss in details. You can refer my earlier post to understand the logic of this script.)
###########################################
#### Written By: SATYAKI DE ########
#### Written On: 25-Jan-2019 ########
#### Package Cryptography needs to ########
#### install in order to run this ########
#### script. ########
#### ########
#### Objective: This script will ########
#### encrypt/decrypt based on the ########
#### hidden supplied salt value. ########
###########################################
from cryptography.fernet import Fernet
import logging
from getVal.clsConfigServer import clsConfigServer as csf
class clsEnDec(object):
def __init__(self):
# Calculating Key
self.token = str(csf.config['DEF_SALT'])
def encrypt_str(self, data, token):
try:
# Capturing the Salt Information
t1 = self.token
t2 = token
if t2 == '':
salt = t1
else:
salt = t2
logging.info("Encrypting the value!")
# Checking Individual Types inside the Dataframe
cipher = Fernet(salt)
encr_val = str(cipher.encrypt(bytes(data,'utf8'))).replace("b'","").replace("'","")
strV1 = "Encrypted value:: " + str(encr_val)
logging.info(strV1)
return encr_val
except Exception as e:
x = str(e)
print(x)
encr_val = ''
return encr_val
def decrypt_str(self, data, token):
try:
# Capturing the Salt Information
t1 = self.token
t2 = token
if t2 == '':
salt = t1
else:
salt = t2
logging.info("Decrypting the value!")
# Checking Individual Types inside the Dataframe
cipher = Fernet(salt)
decr_val = str(cipher.decrypt(bytes(data,'utf8'))).replace("b'","").replace("'","")
strV2 = "Decrypted value:: " + str(decr_val)
logging.info(strV2)
return decr_val
except Exception as e:
x = str(e)
print(x)
decr_val = ''
return decr_val
3. clsFlask.py (This is the main server script that will the encrypt/decrypt class from our previous scenario. This script will capture the requested JSON from the client, who posted from the clients like another python script or third-party tools like Postman.)
###########################################
#### Written By: SATYAKI DE ####
#### Written On: 25-Jan-2019 ####
#### Package Flask package needs to ####
#### install in order to run this ####
#### script. ####
#### ####
#### Objective: This script will ####
#### encrypt/decrypt based on the ####
#### supplied salt value. Also, ####
#### this will capture the individual ####
#### element & stored them into JSON ####
#### variables using flask framework. ####
###########################################
from getVal.clsConfigServer import clsConfigServer as csf
from getVal.clsEnDec import clsEnDecAuth
getVal = clsEnDec()
import logging
class clsFlask(object):
def __init__(self):
self.xtoken = str(csf.config['DEF_SALT'])
def getEncryptProcess(self, dGroup, input_data, dTemplate):
try:
# It is sending default salt value
xtoken = self.xtoken
# Capturing the individual element
dGroup = dGroup
input_data = input_data
dTemplate = dTemplate
# This will check the mandatory json elements
if ((dGroup != '') & (dTemplate != '')):
# Based on the Group & Element it will fetch the salt
# Based on the specific salt it will encrypt the data
if ((dGroup == 'GrDet') & (dTemplate == 'subGrAcct_Nbr')):
xtoken = str(csf.config['ACCT_NBR_SALT'])
strV1 = "xtoken: " + str(xtoken)
logging.info(strV1)
strV2 = "Flask Input Data: " + str(input_data)
logging.info(strV2)
#x = cen.clsEnDecAuth()
ret_val = getVal.encrypt_str(input_data, xtoken)
elif ((dGroup == 'GrDet') & (dTemplate == 'subGrName')):
xtoken = str(csf.config['NAME_SALT'])
strV1 = "xtoken: " + str(xtoken)
logging.info(strV1)
strV2 = "Flask Input Data: " + str(input_data)
logging.info(strV2)
#x = cen.clsEnDecAuth()
ret_val = getVal.encrypt_str(input_data, xtoken)
elif ((dGroup == 'GrDet') & (dTemplate == 'subGrPhone')):
xtoken = str(csf.config['PHONE_SALT'])
strV1 = "xtoken: " + str(xtoken)
logging.info(strV1)
strV2 = "Flask Input Data: " + str(input_data)
logging.info(strV2)
#x = cen.clsEnDecAuth()
ret_val = getVal.encrypt_str(input_data, xtoken)
elif ((dGroup == 'GrDet') & (dTemplate == 'subGrEmail')):
xtoken = str(csf.config['EMAIL_SALT'])
strV1 = "xtoken: " + str(xtoken)
logging.info(strV1)
strV2 = "Flask Input Data: " + str(input_data)
logging.info(strV2)
#x = cen.clsEnDecAuth()
ret_val = getVal.encrypt_str(input_data, xtoken)
else:
ret_val = ''
else:
ret_val = ''
# Return value
return ret_val
except Exception as e:
ret_val = ''
# Return the valid json Error Response
return ret_val
def getDecryptProcess(self, dGroup, input_data, dTemplate):
try:
xtoken = self.xtoken
# Capturing the individual element
dGroup = dGroup
input_data = input_data
dTemplate = dTemplate
# This will check the mandatory json elements
if ((dGroup != '') & (dTemplate != '')):
# Based on the Group & Element it will fetch the salt
# Based on the specific salt it will decrypt the data
if ((dGroup == 'GrDet') & (dTemplate == 'subGrAcct_Nbr')):
xtoken = str(csf.config['ACCT_NBR_SALT'])
strV1 = "xtoken: " + str(xtoken)
logging.info(strV1)
strV2 = "Flask Input Data: " + str(input_data)
logging.info(strV2)
#x = cen.clsEnDecAuth()
ret_val = getVal.decrypt_str(input_data, xtoken)
elif ((dGroup == 'GrDet') & (dTemplate == 'subGrName')):
xtoken = str(csf.config['NAME_SALT'])
strV1 = "xtoken: " + str(xtoken)
logging.info(strV1)
strV2 = "Flask Input Data: " + str(input_data)
logging.info(strV2)
#x = cen.clsEnDecAuth()
ret_val = getVal.decrypt_str(input_data, xtoken)
elif ((dGroup == 'GrDet') & (dTemplate == 'subGrPhone')):
xtoken = str(csf.config['PHONE_SALT'])
strV1 = "xtoken: " + str(xtoken)
logging.info(strV1)
strV2 = "Flask Input Data: " + str(input_data)
logging.info(strV2)
#x = cen.clsEnDecAuth()
ret_val = getVal.decrypt_str(input_data, xtoken)
elif ((dGroup == 'GrDet') & (dTemplate == 'subGrEmail')):
xtoken = str(csf.config['EMAIL_SALT'])
strV1 = "xtoken: " + str(xtoken)
logging.info(strV1)
strV2 = "Flask Input Data: " + str(input_data)
logging.info(strV2)
#x = cen.clsEnDecAuth()
ret_val = getVal.decrypt_str(input_data, xtoken)
else:
ret_val = ''
else:
ret_val = ''
# Return value
return ret_val
except Exception as e:
ret_val = ''
# Return the valid Error Response
return ret_val
4. __init__.py (This autogenerated script contains the primary calling methods of encryption & decryption based on the element header & values after enhanced as per the functionality.)
###########################################
#### Written By: SATYAKI DE ####
#### Written On: 08-Jun-2019 ####
#### Package Flask package needs to ####
#### install in order to run this ####
#### script. ####
#### ####
#### Objective: Main Calling scripts. ####
#### This is an autogenrate scripts. ####
#### However, to meet the functionality####
#### we've enhanced as per our logic. ####
###########################################
__all__ = ['clsFlask']
import logging
import azure.functions as func
import json
from getVal.clsFlask import clsFlask
getVal = clsFlask()
def main(req: func.HttpRequest) -> func.HttpResponse:
logging.info('Python Encryption function processed a request.')
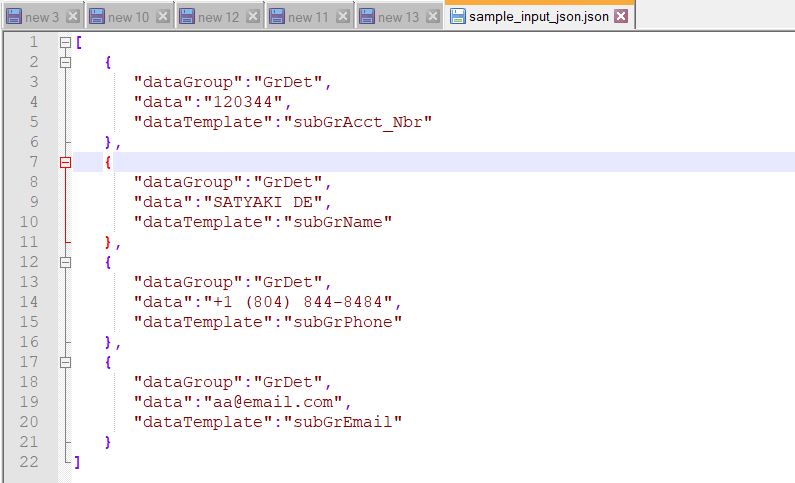
str_val = 'Input Payload:: ' + str(req.get_json())
str_1 = str(req.get_json())
logging.info(str_val)
ret_val = {}
DataIn = ''
dGroup = ''
dTemplate = ''
flg = ''
if (str_1 != ''):
try:
req_body = req.get_json()
dGroup = req_body.get('dataGroup')
try:
DataIn = req_body.get('data')
strV15 = 'If Part:: ' + str(DataIn)
logging.info(strV15)
if ((DataIn == '') | (DataIn == None)):
raise ValueError
flg = 'Y'
except ValueError:
DataIn = req_body.get('edata')
strV15 = 'Else Part:: ' + str(DataIn)
logging.info(strV15)
flg = 'N'
except:
DataIn = req_body.get('edata')
strV15 = 'Else Part:: ' + str(DataIn)
logging.info(strV15)
flg = 'N'
dTemplate = req_body.get('dataTemplate')
except ValueError:
pass
strV5 = "Encrypt Decrypt Flag:: " + flg
logging.info(strV5)
if (flg == 'Y'):
if ((DataIn != '') & ((dGroup != '') & (dTemplate != ''))):
logging.info("Encryption Started!")
ret_val = getVal.getEncryptProcess(dGroup, DataIn, dTemplate)
strVal2 = 'Return Payload:: ' + str(ret_val)
logging.info(strVal2)
xval = json.dumps(ret_val)
return func.HttpResponse(xval)
else:
return func.HttpResponse(
"Please pass a data in the request body",
status_code=400
)
else:
if ((DataIn != '') & ((dGroup != '') & (dTemplate != ''))):
logging.info("Decryption Started!")
ret_val2 = getVal.getDecryptProcess(dGroup, DataIn, dTemplate)
strVal3 = 'Return Payload:: ' + str(ret_val)
logging.info(strVal3)
xval1 = json.dumps(ret_val2)
return func.HttpResponse(xval1)
else:
return func.HttpResponse(
"Please pass a data in the request body",
status_code=400
)
In this script, based on the value of an flg variable, we’re calling our encryption or decryption methods. And, the value of the flg variable is set based on the following logic –
try: DataIn = req_body.get('data') strV15 = 'If Part:: ' + str(DataIn) logging.info(strV15) if ((DataIn == '') | (DataIn == None)): raise ValueError flg = 'Y' except ValueError: DataIn = req_body.get('edata') strV15 = 'Else Part:: ' + str(DataIn) logging.info(strV15) flg = 'N' except: DataIn = req_body.get('edata') strV15 = 'Else Part:: ' + str(DataIn) logging.info(strV15) flg = 'N'
So, if the application gets the “data” element then – it will consider the data needs to be encrypted; otherwise, it will go for decryption. And, based on that – it is setting the value.
Now, we’re ready to locally run our application –
func host start
And, the output will look like this –
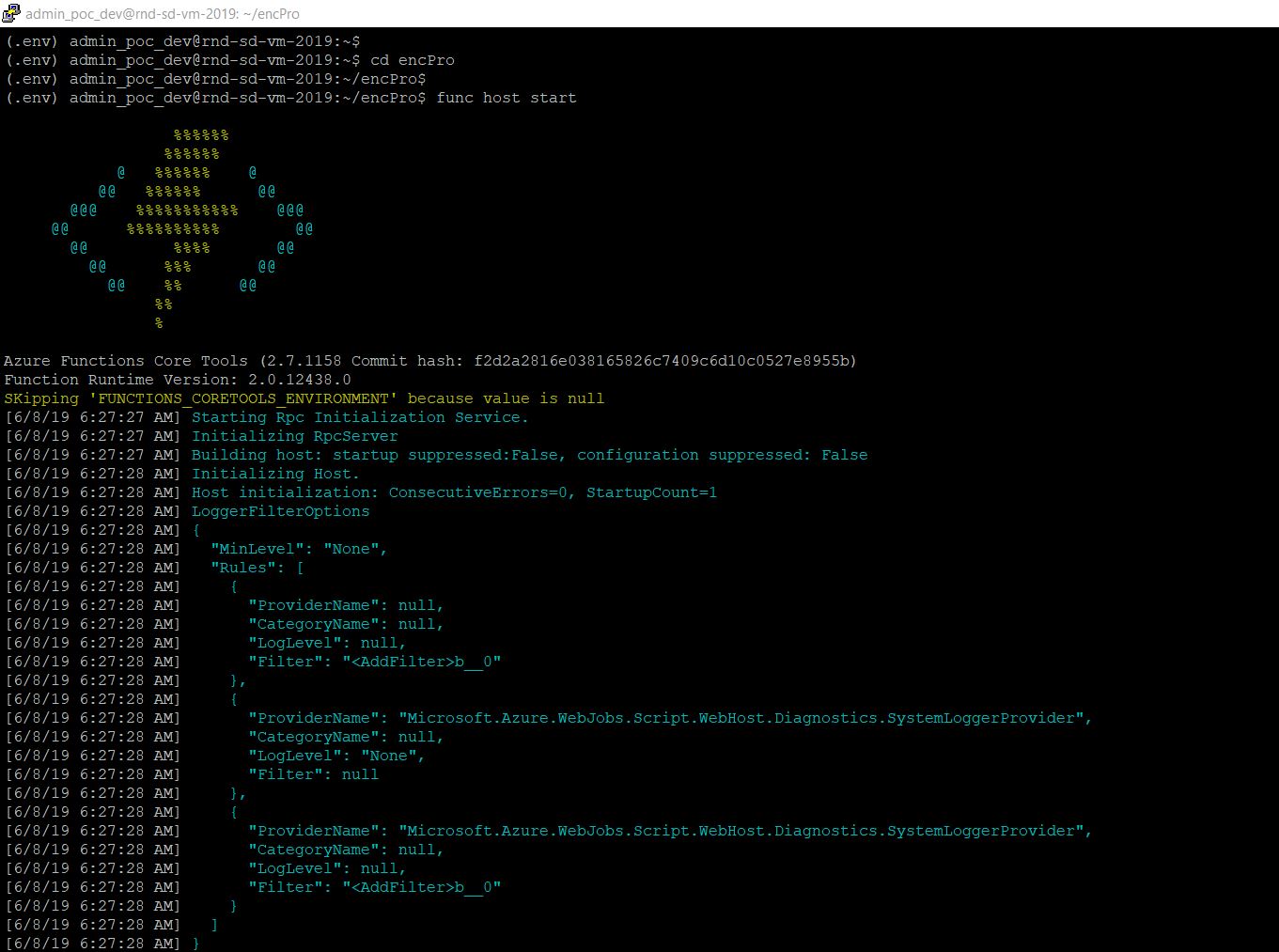
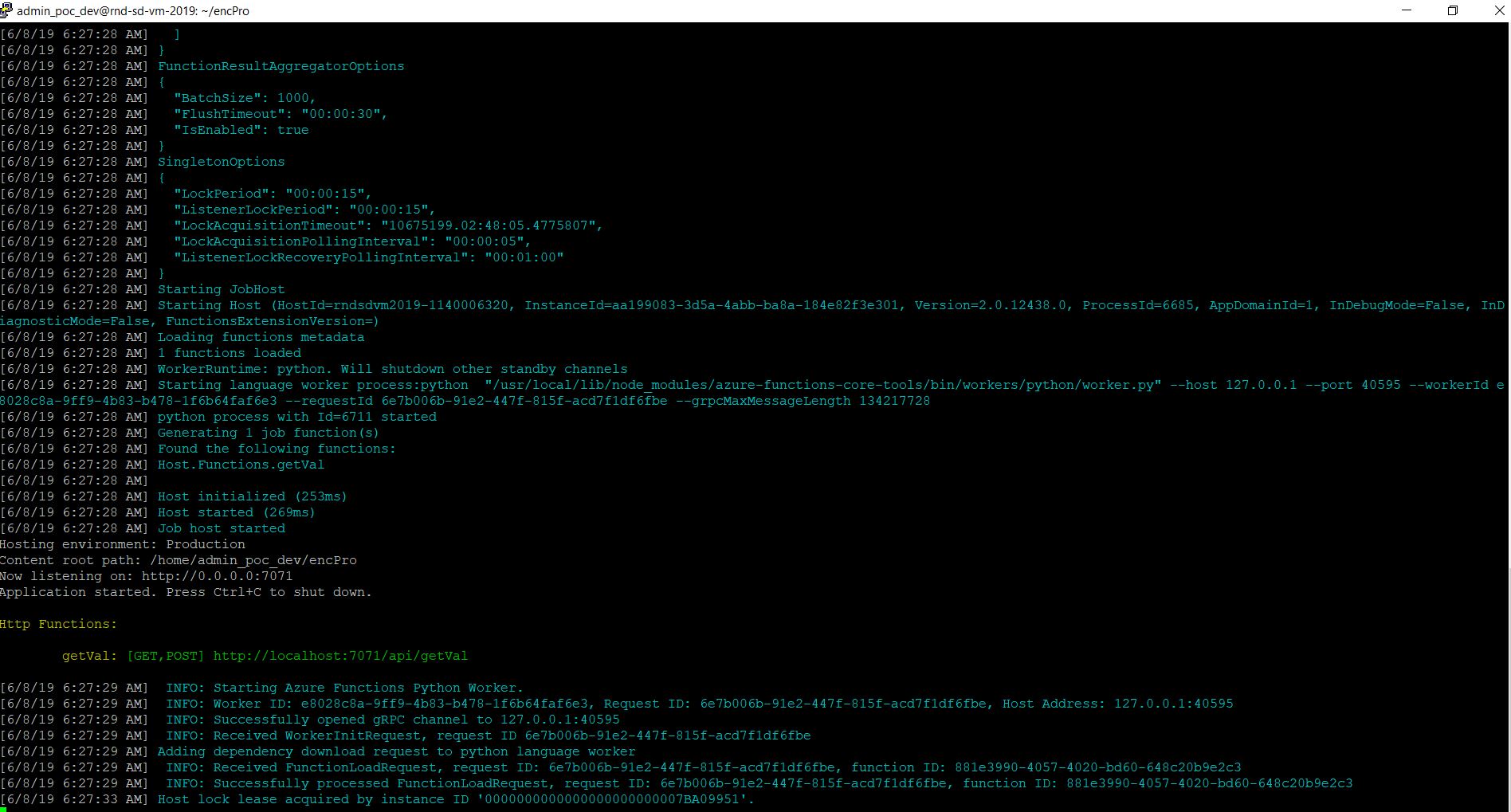
Let’s test it from postman –
Encrypt:

Decrypt:

Great. Now, we’re ready to publish this application to Azure cloud.
As in our earlier steps, we’ve already built our storage account for the metadata. Please scroll to top to view that again. Now, using that information, we’ll make the function app with a more meaningful name –
az functionapp create –resource-group rndWestUSGrp –os-type Linux \
–consumption-plan-location westus –runtime python \
–name getEncryptDecrypt –storage-account cryptpy2019
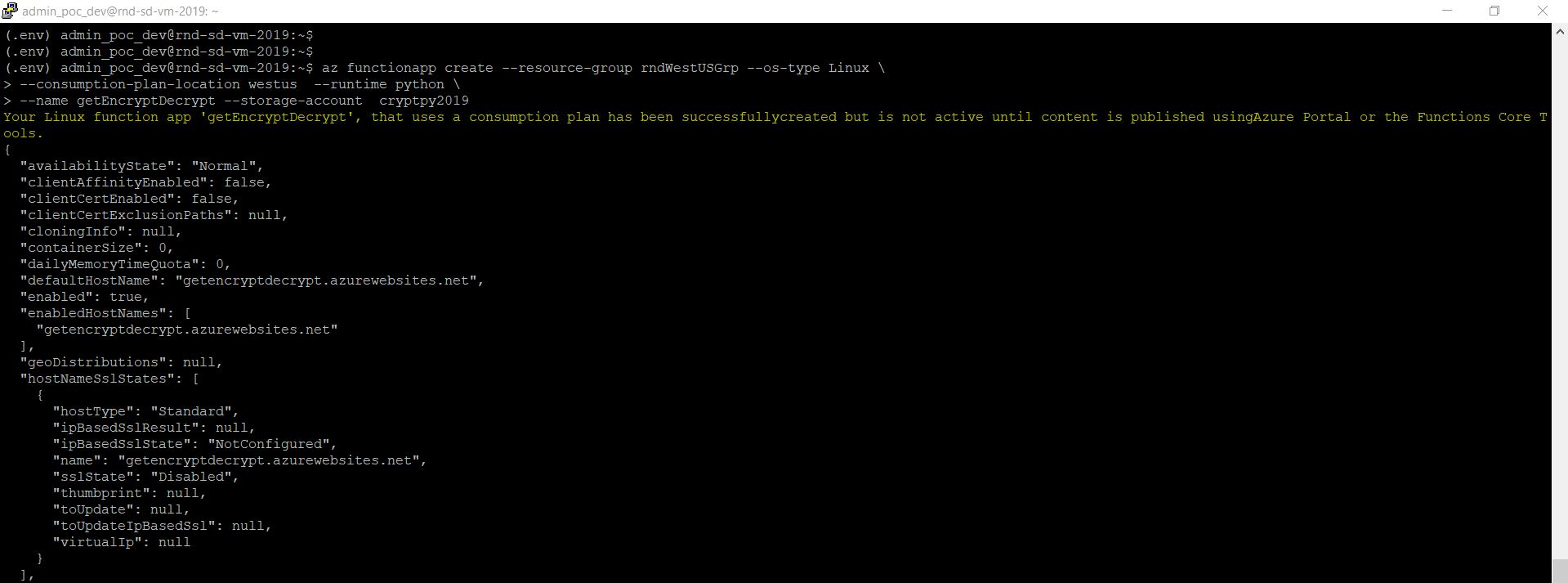
Let’s publish the function –
sudo func azure functionapp publish “getEncryptDecrypt” –build-native-deps
On many occassion, without the use of “–build-native-deps” might leads to failure. Hence, I’ve added that to avoid such scenarios.

Now, we need to test our first published complex Azure function with Python through postman –
Encrypt:

Decrypt:

Wonderful! So, it is working.
You can see the function under the Azure portal –
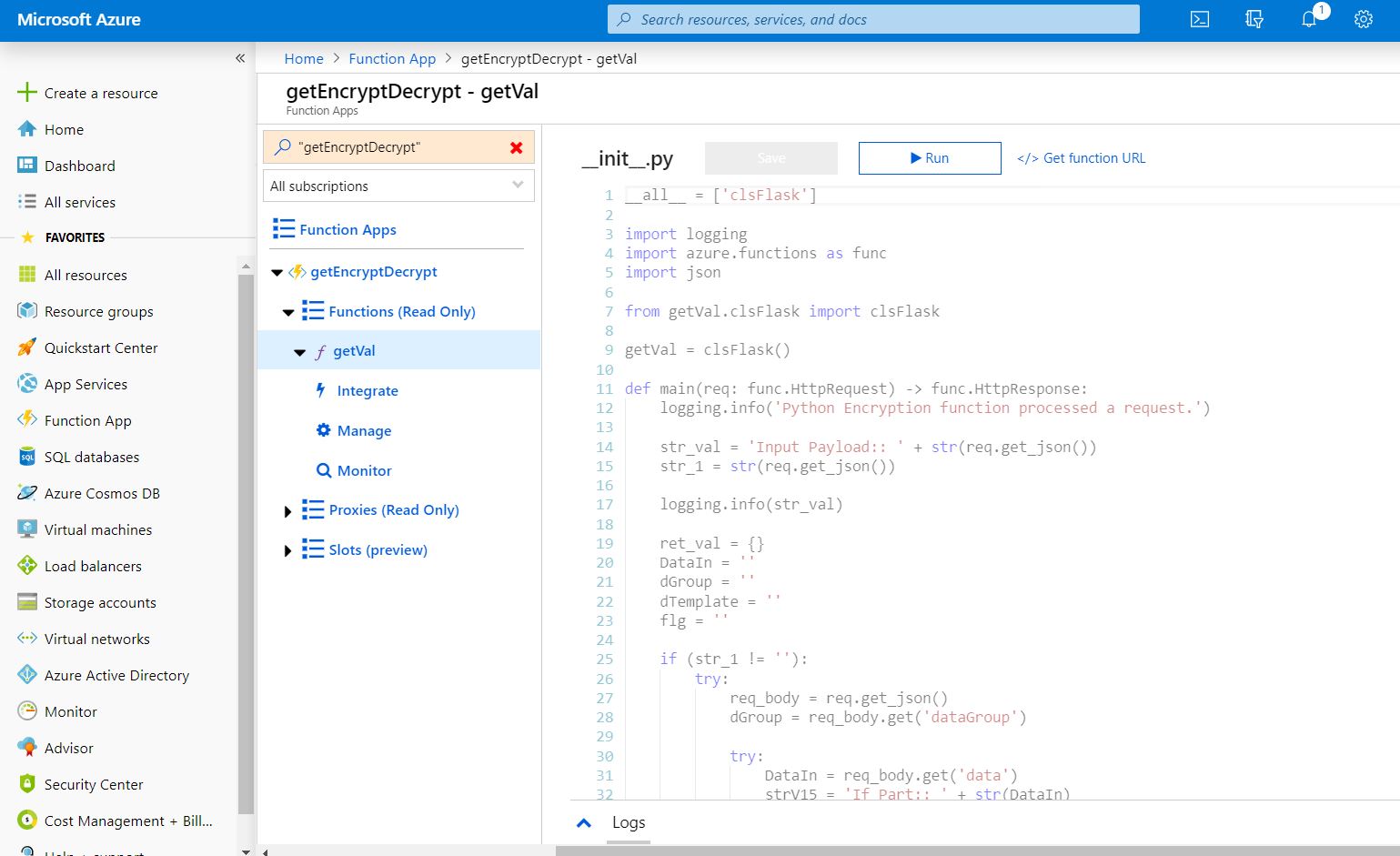
Let’s see some other important features of this function –
Monitor: You can monitor two ways. One is by clicking the monitor options you will get the individual requests level details & also get to see the log information over here –

Clicking Application Insights will give you another level of detailed logs, which can be very useful for debugging. We’ll touch this at the end of this post with a very brief discussion.

As you can see, clicking individual lines will show the details further.
Let’s quickly check the application insights –

Application Insights will give you a SQL like an interface where you can get the log details of all your requests.

You can expand the individual details for further information.

You can change the parameter name & other details & click the run button to get all the log details for your debugging purpose.
So, finally, we’ve achieved our goal. This is relatively long posts. But, I’m sure this will help you to create your first python-based function on the Azure platform.
Hope, you will like this approach. Let me know your comment on the same.
I’ll bring some more exciting topic in the coming days from the Python verse.
Till then, Happy Avenging! 😀
Note: All the data posted here are representational data & available over the internet.

























































You must be logged in to post a comment.